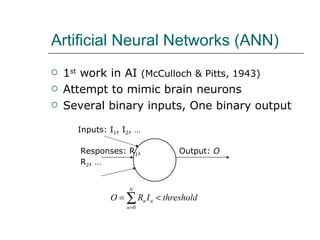
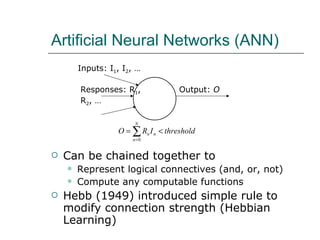
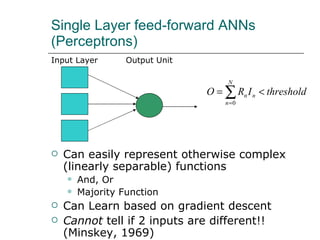
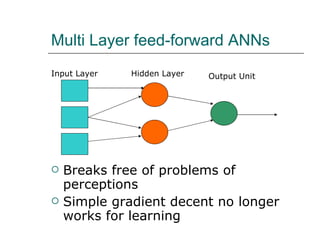
1. The document discusses different approaches to knowledge representation and machine learning including first order logic, artificial neural networks, Bayesian networks, and reinforcement learning.
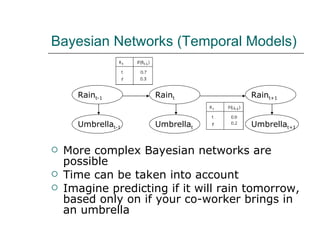
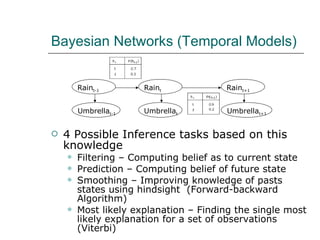
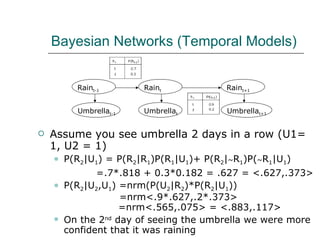
2. Artificial neural networks can represent complex functions by learning through backpropagation but lack interpretability, while Bayesian networks combine logic and learning from experience under uncertainty.
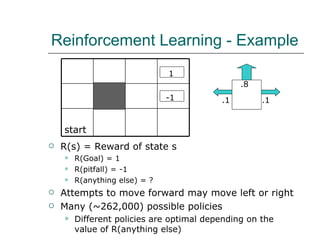
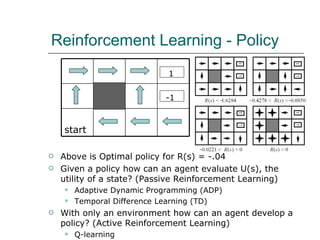
3. Reinforcement learning defines rewards and punishments to allow agents to discover optimal policies without being explicitly programmed through interactions with an environment.