Download to read offline




![Modeling Dose-Response Relationship
1st challenge: Modeling
Too few doses to adopt Parametric Dose-Response model.
(Adaptive design will start with only one lower dose)
Strategy: Semiparametric Specification
The mode of action of the drug and Ph.III outcomes suggest that a
monotonicity constraint holds for the dose-response relationship:
Mm = µj ≡ E[Yij ] : E0 = µ1 ≥ µ2 ≥ µ3 ≥ µ4 ≥ µ5 = EMAX](https://image.slidesharecdn.com/lucapozzibbc2012-120610212052-phpapp02/85/Luca-Pozzi-5thBCC-2012-5-320.jpg)








![Algorithm: Predictive Resample
1 Sample (α, β)(1) , ..., (α, β)(k ) , ..., (α, β)(N ) ;
2 Select Dose d;
3 for l = 1, ..., L draw (α, β)(l ) from the posterior sample at
interim of size N;
∗(l )
4 Simulate one dataset Yd |(α, β)(l ) , Ad ;
SIR
(l )
5 Compute p Yd |(α, β)(k ) , k = 1, ..., N;
∗(l )
l (θk ;Y ∗ ) p (Yd |(α,β)(k ) )
6 Compute wk = ∗ = ∗(l ) ;
j l (θj ;Y ) j p (Yd |(α,β)(j ) )
(l )
7 Compute by resampling PPd [criterion] for each criteria;
In the end:
L
1 (l )
{PPd [criterion] c }
PPd = mean
{criteria} l =1](https://image.slidesharecdn.com/lucapozzibbc2012-120610212052-phpapp02/85/Luca-Pozzi-5thBCC-2012-14-320.jpg)
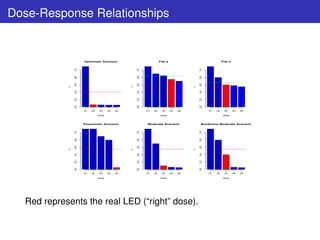

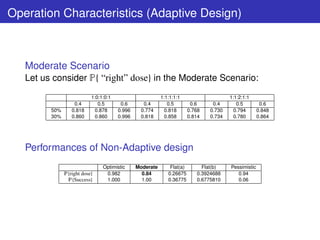






This document describes a Bayesian adaptive dose selection procedure using semi-parametric dose-response modeling. It involves modeling dose-response relationships non-parametrically using a monotonicity constraint, applying Bayesian model averaging over different dose-response shapes, and performing predictive probability calculations using importance sampling to determine the dose to take forward at an interim analysis based on predictive probabilities of success criteria being met. Simulation results demonstrate the procedure can correctly identify the optimal dose and uses fewer patients than a non-adaptive design.

































































