Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
2t3
1,235 views
Random partionerのデータモデリング
第16回Cassandra勉強会
Technology
◦
Business
◦
Related topics:
Data Modeling Techniques
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PPTX
巨大な表を高速に扱うData.table について
by
Haruka Ozaki
PDF
Rにおける大規模データ解析(第10回TokyoWebMining)
by
Shintaro Fukushima
PDF
Rあんなときこんなとき(tokyo r#12)
by
Shintaro Fukushima
PDF
mmapパッケージを使ってお手軽オブジェクト管理
by
Shintaro Fukushima
PDF
Rのデータ構造とメモリ管理
by
Takeshi Arabiki
PPTX
Programming school 08
by
Masato Nakajima
PPTX
R高速化
by
Monta Yashi
PDF
R3.0.0 is relased
by
Shintaro Fukushima
巨大な表を高速に扱うData.table について
by
Haruka Ozaki
Rにおける大規模データ解析(第10回TokyoWebMining)
by
Shintaro Fukushima
Rあんなときこんなとき(tokyo r#12)
by
Shintaro Fukushima
mmapパッケージを使ってお手軽オブジェクト管理
by
Shintaro Fukushima
Rのデータ構造とメモリ管理
by
Takeshi Arabiki
Programming school 08
by
Masato Nakajima
R高速化
by
Monta Yashi
R3.0.0 is relased
by
Shintaro Fukushima
What's hot
PDF
R-hpc-1 TokyoR#11
by
Shintaro Fukushima
PPTX
分かった気分になるスタックトレース
by
Trash Briefing ,Ltd
PDF
RのffでGLMしてみたけど...
by
Kazuya Wada
PDF
Rの高速化
by
弘毅 露崎
PDF
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
PDF
RのffとbigmemoryとRevoScaleRとを比較してみた
by
Kazuya Wada
PDF
20190202-pgunconf-Access-Privilege-Inquiry-Functions
by
Toshi Harada
PPT
第7回社内勉強会「Code Sucks - 人の振り見て我が振り直せ」
by
Hiromu Shioya
PDF
Web技術勉強会 第38回
by
龍一 田中
PDF
Gensim
by
saireya _
PDF
Stanの便利な事後処理関数
by
daiki hojo
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
by
Takuya Akiba
PDF
ぼくのかんがえたさいきょうのついったーくらいあんと
by
Yutaka Tsumori
PDF
Boost.勉強会 #21 札幌「C++1zにstring_viewが導入されてうれしいので紹介します」
by
Hiro H.
PDF
Rubyによるデータ解析
by
Shugo Maeda
PDF
Perl RDBMS Programming(DBI/DBIx::Sunnyのはなし)
by
karupanerura
PDF
Pg14_sql_standard_function_body
by
kasaharatt
PPTX
全探索
by
HCPC: 北海道大学競技プログラミングサークル
PDF
Pythonデータ分析 第3回勉強会資料 8章
by
Makoto Kawano
R-hpc-1 TokyoR#11
by
Shintaro Fukushima
分かった気分になるスタックトレース
by
Trash Briefing ,Ltd
RのffでGLMしてみたけど...
by
Kazuya Wada
Rの高速化
by
弘毅 露崎
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
RのffとbigmemoryとRevoScaleRとを比較してみた
by
Kazuya Wada
20190202-pgunconf-Access-Privilege-Inquiry-Functions
by
Toshi Harada
第7回社内勉強会「Code Sucks - 人の振り見て我が振り直せ」
by
Hiromu Shioya
Web技術勉強会 第38回
by
龍一 田中
Gensim
by
saireya _
Stanの便利な事後処理関数
by
daiki hojo
プログラミングコンテストでのデータ構造 2 ~動的木編~
by
Takuya Akiba
ぼくのかんがえたさいきょうのついったーくらいあんと
by
Yutaka Tsumori
Boost.勉強会 #21 札幌「C++1zにstring_viewが導入されてうれしいので紹介します」
by
Hiro H.
Rubyによるデータ解析
by
Shugo Maeda
Perl RDBMS Programming(DBI/DBIx::Sunnyのはなし)
by
karupanerura
Pg14_sql_standard_function_body
by
kasaharatt
全探索
by
HCPC: 北海道大学競技プログラミングサークル
Pythonデータ分析 第3回勉強会資料 8章
by
Makoto Kawano
Similar to Random partionerのデータモデリング
PDF
20110517 okuyama ソーシャルメディアが育てた技術勉強会
by
Takahiro Iwase
PPTX
1.2新機能と1.2から始めるcql3
by
seki_intheforest
PDF
InfoTalk springbreak_2012
by
Hiroshi Bunya
PDF
【第3回初心者勉強会】データベースを使おう
by
Shuhei Iitsuka
PPT
081108huge_data.ppt
by
Naoya Ito
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PDF
Apache Drill でオープンデータを分析してみる - db tech showcase Sapporo 2015 2015/09/11
by
MapR Technologies Japan
PDF
ARC-009_RDB 技術者のための NoSQL ガイド
by
decode2016
PDF
Counter Table Pattern & Temporary Table Pattern (2012-04-13 CDP Night)
by
Ryuichi Tokugami
PDF
gumiStudy#1 キーバリューストアのご紹介と利用時の設計モデルについて
by
gumilab
PDF
Guide to Cassandra for Production Deployments
by
smdkk
PPTX
Okuyama説明資料 20120119 ss
by
Takahiro Iwase
PDF
2010/07/09 osc kansai-kvsokuyama
by
Takahiro Iwase
PDF
20110519 okuyama tokyo_linuxstudy
by
Takahiro Iwase
PDF
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
PDF
Data-Intensive Text Processing with MapReduce ch4
by
Sho Shimauchi
PDF
20110708 dist_study okuyama
by
Takahiro Iwase
PDF
ISUCONで学ぶ Webアプリケーションのパフォーマンス向上のコツ 実践編 完全版
by
Masahiro Nagano
PDF
20181031 springfest spring data geode
by
Masaki Yamakawa
PDF
[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...
by
Insight Technology, Inc.
20110517 okuyama ソーシャルメディアが育てた技術勉強会
by
Takahiro Iwase
1.2新機能と1.2から始めるcql3
by
seki_intheforest
InfoTalk springbreak_2012
by
Hiroshi Bunya
【第3回初心者勉強会】データベースを使おう
by
Shuhei Iitsuka
081108huge_data.ppt
by
Naoya Ito
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
Apache Drill でオープンデータを分析してみる - db tech showcase Sapporo 2015 2015/09/11
by
MapR Technologies Japan
ARC-009_RDB 技術者のための NoSQL ガイド
by
decode2016
Counter Table Pattern & Temporary Table Pattern (2012-04-13 CDP Night)
by
Ryuichi Tokugami
gumiStudy#1 キーバリューストアのご紹介と利用時の設計モデルについて
by
gumilab
Guide to Cassandra for Production Deployments
by
smdkk
Okuyama説明資料 20120119 ss
by
Takahiro Iwase
2010/07/09 osc kansai-kvsokuyama
by
Takahiro Iwase
20110519 okuyama tokyo_linuxstudy
by
Takahiro Iwase
Logをs3とredshiftに格納する仕組み
by
Ken Morishita
Data-Intensive Text Processing with MapReduce ch4
by
Sho Shimauchi
20110708 dist_study okuyama
by
Takahiro Iwase
ISUCONで学ぶ Webアプリケーションのパフォーマンス向上のコツ 実践編 完全版
by
Masahiro Nagano
20181031 springfest spring data geode
by
Masaki Yamakawa
[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...
by
Insight Technology, Inc.
Random partionerのデータモデリング
1.
RandomPartitonerの データモデリング
株式会社ワークスアプリケーションズ 堤 勇人(@2t3)
2.
自己紹介 所属
ワークスアプリケーションズ Incubation Labo4 Webmail お仕事 ウェブメールの開発
3.
自己紹介 所属
ワークスアプリケーションズ Incubation Labo4 Webmail お仕事 ウェブメールの開発 ・・・という名義で最先端技術を試す実験場
4.
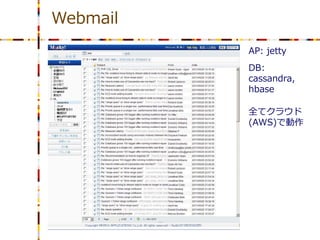
Webmail
AP: jetty DB: cassandra, hbase 全てクラウド (AWS)で動作
5.
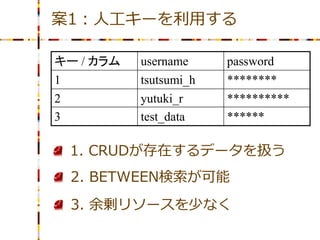
今回の達成目標 1. CRUDが存在するデータを扱う
DELETEが存在する。 2. BETWEEN検索が可能 例えば、このユーザーの3月~5月の データ、という検索をしたい。 3. 余剰リソースを少なく 低予算。
6.
前提知識:普通のデータモデリング
いわゆるRDB的な 例えば、Accountデータ キー / カラム username(key) password tsutsumi_h tsutsumi_h ******** yutuki_r yutuki_r ********** test_data test_data ******
7.
RDBを使え?
8.
RDBを使え? 知らん! 批判は断る! いやいや、分かってる分かってるん だ。最初から動的なウェブアプリ ケーションにCassandraなんて無理 だし。アトミック操作も無いしね。 件数表示とかすごい勢いでズレるし。 それは分かっていながら、敢えて、 そう敢えてのチャレンジなのですよ。 本当はlike検索とかしたい。超した い。気軽にインデックスとか貼りた い。でも最先端技術使うって名目な んだもの。
9.
もう一度、今回の達成目標 1. CRUDが存在するデータを扱う
DELETEが存在する。 2. BETWEEN検索が可能 例えば、このユーザーの3月~5月の データ、という検索をしたい。 3. 余剰リソースを少なく 低予算。
10.
案1:人工キーを利用する キー / カラム
username password 1 tsutsumi_h ******** 2 yutuki_r ********** 3 test_data ****** 1. CRUDが存在するデータを扱う 2. BETWEEN検索が可能 3. 余剰リソースを少なく
11.
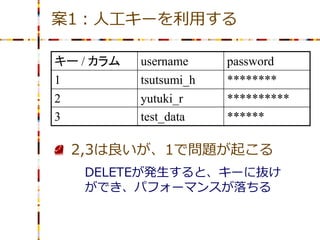
案1:人工キーを利用する キー / カラム
username password 1 tsutsumi_h ******** 2 yutuki_r ********** 3 test_data ****** 2,3は良いが、1で問題が起こる DELETEが発生すると、キーに抜け ができ、パフォーマンスが落ちる
12.
案1:人工キーを利用する キー / カラム
username password 1 tsutsumi_h ******** 2 yutuki_r ********** 3 test_data ****** 2,3は良いが、1で問題が起こる DELETEが発生すると、キーに抜け ができ、パフォーマンスが落ちる
13.
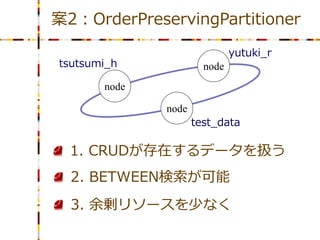
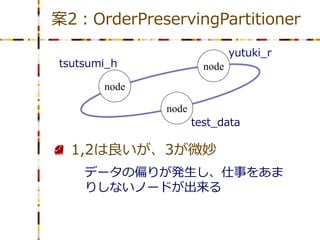
案2:OrderPreservingPartitioner
yutuki_r tsutsumi_h node node node test_data 1. CRUDが存在するデータを扱う 2. BETWEEN検索が可能 3. 余剰リソースを少なく
14.
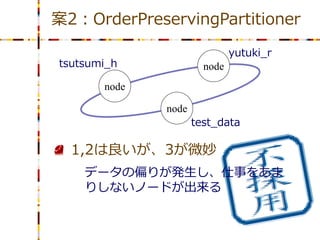
案2:OrderPreservingPartitioner
yutuki_r tsutsumi_h node node node test_data 1,2は良いが、3が微妙 データの偏りが発生し、仕事をあま りしないノードが出来る
15.
案2:OrderPreservingPartitioner
yutuki_r tsutsumi_h node node node test_data 1,2は良いが、3が微妙 データの偏りが発生し、仕事をあま りしないノードが出来る
16.
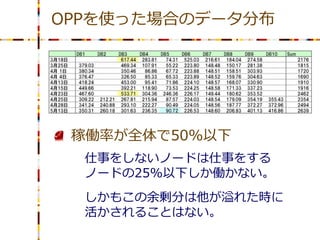
OPPを使った場合のデータ分布 稼働率が全体で50%以下
仕事をしないノードは仕事をする ノードの25%以下しか働かない。 しかもこの余剰分は他が溢れた時に 活かされることはない。
17.
前提知識:RandomPartitioner
Columnについては検索ができる 例えば、p~zまでのカラム名を抽出 キー / カラム username(key) … password tsutsumi_h tsutsumi_h … ******** yutuki_r yutuki_r … ********** test_data test_data … ******
18.
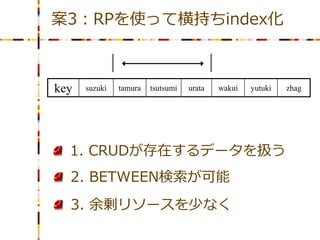
案3:RPを使って横持ちindex化 key
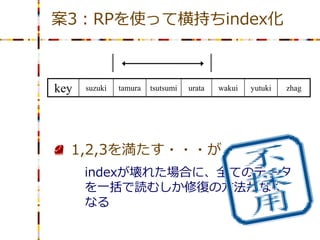
suzuki tamura tsutsumi urata wakui yutuki zhag 1. CRUDが存在するデータを扱う 2. BETWEEN検索が可能 3. 余剰リソースを少なく
19.
案3:RPを使って横持ちindex化 key
suzuki tamura tsutsumi urata wakui yutuki zhag 1,2,3を満たす・・・が indexが壊れた場合に、全てのデータ を一括で読むしか修復の方法が なくなる。
20.
案3:RPを使って横持ちindex化 key
suzuki tamura tsutsumi urata wakui yutuki zhag 1,2,3を満たす・・・が indexが壊れた場合に、全てのデータ を一括で読むしか修復の方法がなく なる
21.
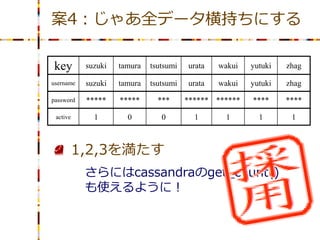
案4:じゃあ全データ横持ちにする key
suzuki tamura tsutsumi urata wakui yutuki zhag username suzuki tamura tsutsumi urata wakui yutuki zhag password ***** ***** *** ****** ****** **** **** active 1 0 0 1 1 1 1 1. CRUDが存在するデータを扱う 2. BETWEEN検索が可能 3. 余剰リソースを少なく
22.
案4:じゃあ全データ横持ちにする key
suzuki tamura tsutsumi urata wakui yutuki zhag username suzuki tamura tsutsumi urata wakui yutuki zhag password ***** ***** *** ****** ****** **** **** active 1 0 0 1 1 1 1 1,2,3を満たす さらにはcassandraのget_count() も使えるように!
23.
案4:じゃあ全データ横持ちにする key
suzuki tamura tsutsumi urata wakui yutuki zhag username suzuki tamura tsutsumi urata wakui yutuki zhag password ***** ***** *** ****** ****** **** **** active 1 0 0 1 1 1 1 1,2,3を満たす さらにはcassandraのget_count() も使えるように!
24.
横持ちの仕方には色々ある key / column
tsutsumi@20110524 tsutsumi@20110525 key tsutsumi@20110524 tsutsumi@20110525 username tsutsumi tsutsumi_h password ******* ****************** active 0 1 完全横持ち 全てのデータが、column名ごとに 横に入る。自由に検索が出来るが、 rowが大きくなる。
25.
横持ちの仕方には色々ある key / column
tsutsumi@20110524 tsutsumi@20110525 tsutsumi@key tsutsumi@20110524 tsutsumi@20110525 tsutsumi@username tsutsumi tsutsumi_h tsutsumi@password ******* ****************** tsutsumi@active 0 1 ブロック(?)持ち ユーザーなど、ブロックごとに横持ち する。rowが比較的小さくなり、 ブロック毎のcountも出来る。 ただし、ブロック内しか検索できない
26.
横持ちの仕方には色々ある key / column
tsutsumi@20110524 tsutsumi@20110525 tsutsumi@20110524 tsutsumi@20110524 空 @key tsutsumi@20110524 tsutsumi 空 @username tsutsumi@20110525 空 tsutsumi@20110525 @key tsutsumi@20110525 空 tsutsumi_h @username ナナメ持ち 一つのキー毎に別のカラム名で横持ち する。rowが小さくなり負荷が少ない
27.
RP横持ちを使ったデータ分布 ブロック持ちの場合 DB1
DB2 DB3 79.82 79.56 79.77 (GB) ほぼ均等なデータ分布・稼働率 個々のノード毎の偏りがなくなり、 負荷も全体に分散するようになった。 さらに、get_Count()関数の利用が 可能になり、range_ghostの呪いから も開放された。
28.
RP横持ちを使ったデータ分布 ブロック持ちの場合 DB1
DB2 DB3 79.82 79.56 79.77 (GB) ほぼ均等なデータ分布・稼働率 個々のノード毎の偏りがなくなり、 負荷も全体に分散するようになった。 さらに、get_Count()関数の利用が 可能になり、range_ghostの呪いから も開放された。
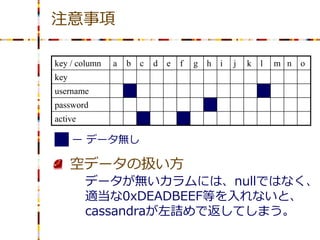
29.
注意事項 key / column
a b c d e f g h i j k l m n o key username password active ー データ無し 空データの扱い方 データが無いカラムには、nullではなく、 適当な0xDEADBEEF等を入れないと、 cassandraが左詰めで返してしまう。
30.
以上、ありがとうございました。
Download


































































![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)