Download to read offline





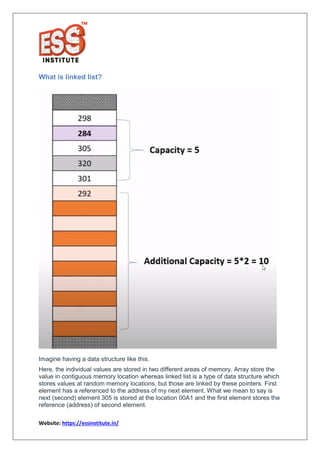
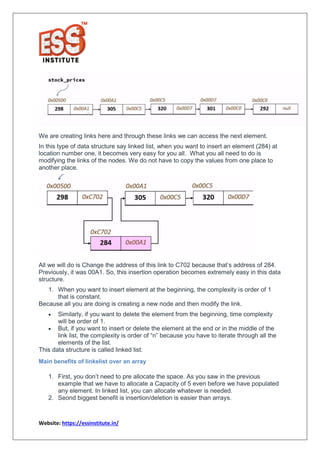


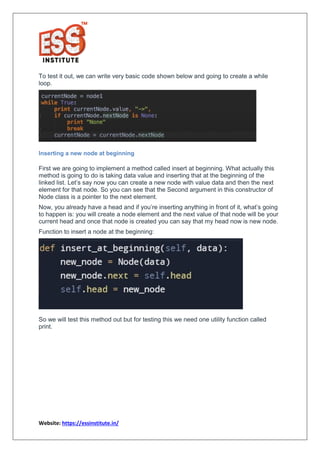
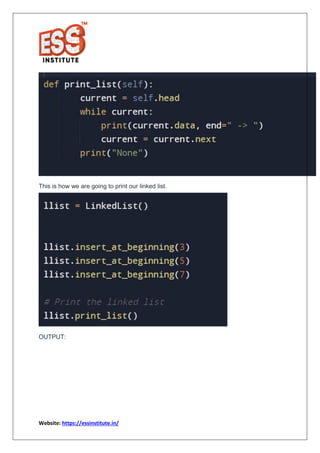

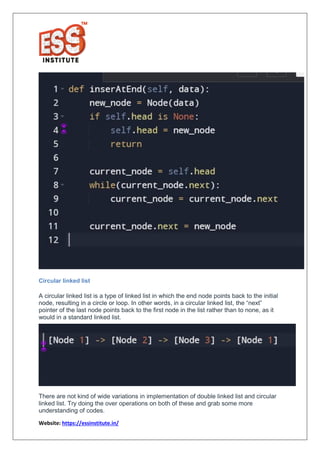


The document provides a comprehensive overview of linked lists in Python, highlighting their complexities and operations compared to arrays. It explains the advantages of linked lists, such as easier insertion and deletion, and discusses different types like doubly linked lists and circular linked lists. Additionally, it includes code snippets for implementing linked lists in Python, making it a valuable resource for beginners and intermediate programmers.















































