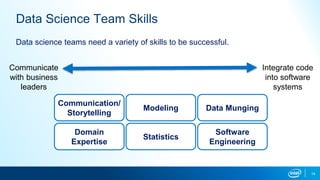
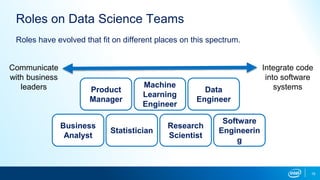
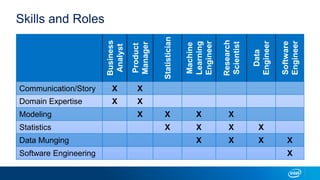
This document provides an overview of AI in the enterprise, including the data science workflow, common roles on AI teams, ways to structure teams, and considerations for model maintenance after deployment. The data science workflow involves problem definition, data collection, exploration, modeling, validation, and deployment. Successful AI teams require a variety of skills including communication, domain expertise, modeling, statistics, engineering, and data processing. Teams can be structured centralized around a head, distributed within business units, or use hybrid approaches. Maintaining models after deployment involves monitoring by business and data science teams.