Downloaded 15 times

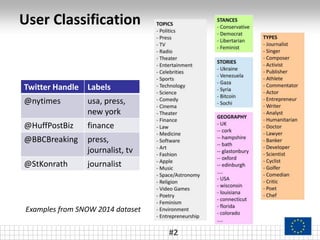
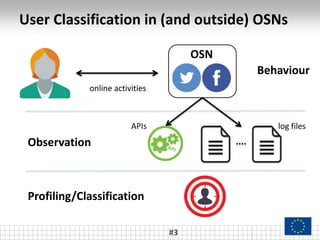
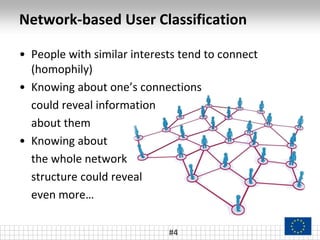


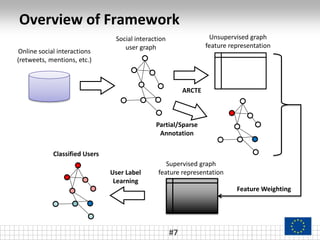

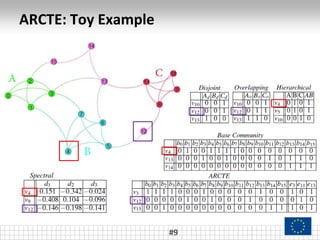


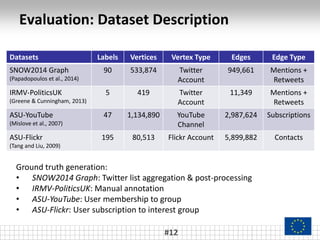
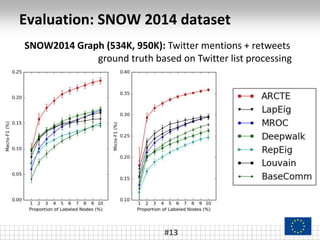
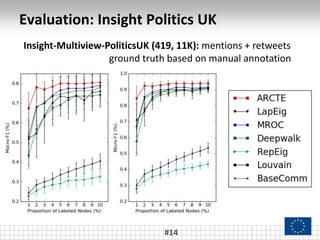
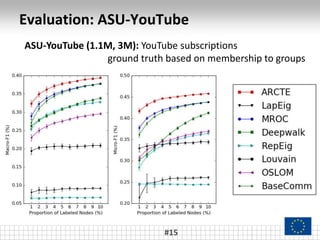
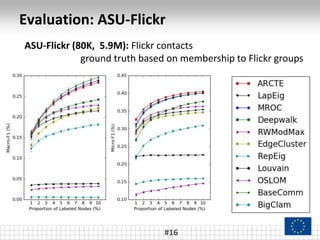
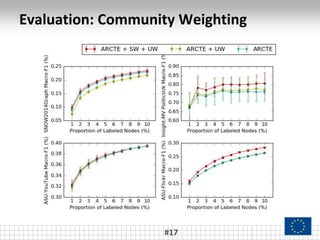








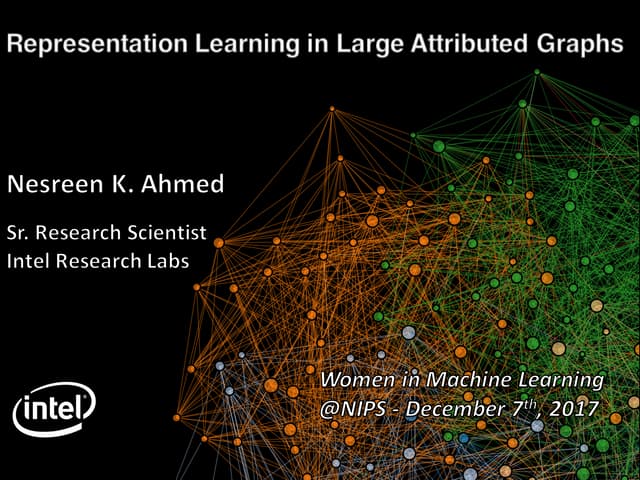
The document presents a framework called ARCTE for classifying users in online interaction networks, leveraging user-centric community detection and improved user-centric Pagerank calculations. It details methodologies for feature representation and community weighting to enhance predictive accuracy, supported by extensive evaluation across various datasets. Future work includes expanding the framework to integrate additional signals and address other classification challenges.