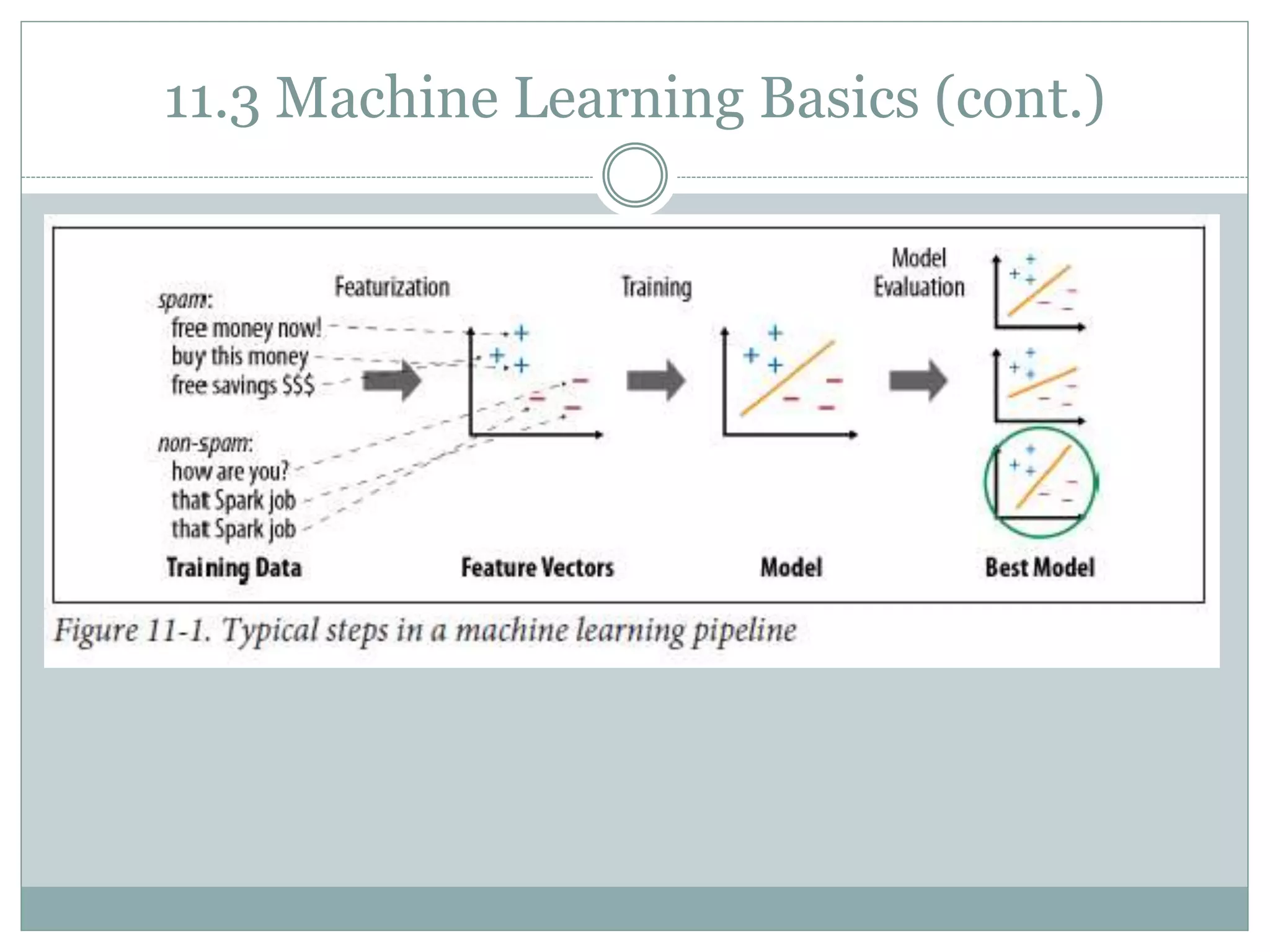
This document provides an overview of machine learning with MLlib in Spark, detailing system requirements, machine learning basics, and various algorithms including feature extraction, classification, regression, and clustering. It introduces the Pipeline API introduced in Spark 1.2 for building machine learning pipelines and highlights important performance considerations. The document concludes by emphasizing the integration of MLlib with other Spark APIs and its ongoing development.