Chapter 4 of 'HBase in Action' discusses HBase table design, covering schema design concepts, advanced table definition parameters, and read performance optimization. It emphasizes the importance of defining requirements, modeling for access patterns, and the role of denormalization in achieving efficient data storage and retrieval. Additionally, it highlights the unique mapping from relational to non-relational databases and advanced configurations for column families.








![4.1.4 Targeted data access
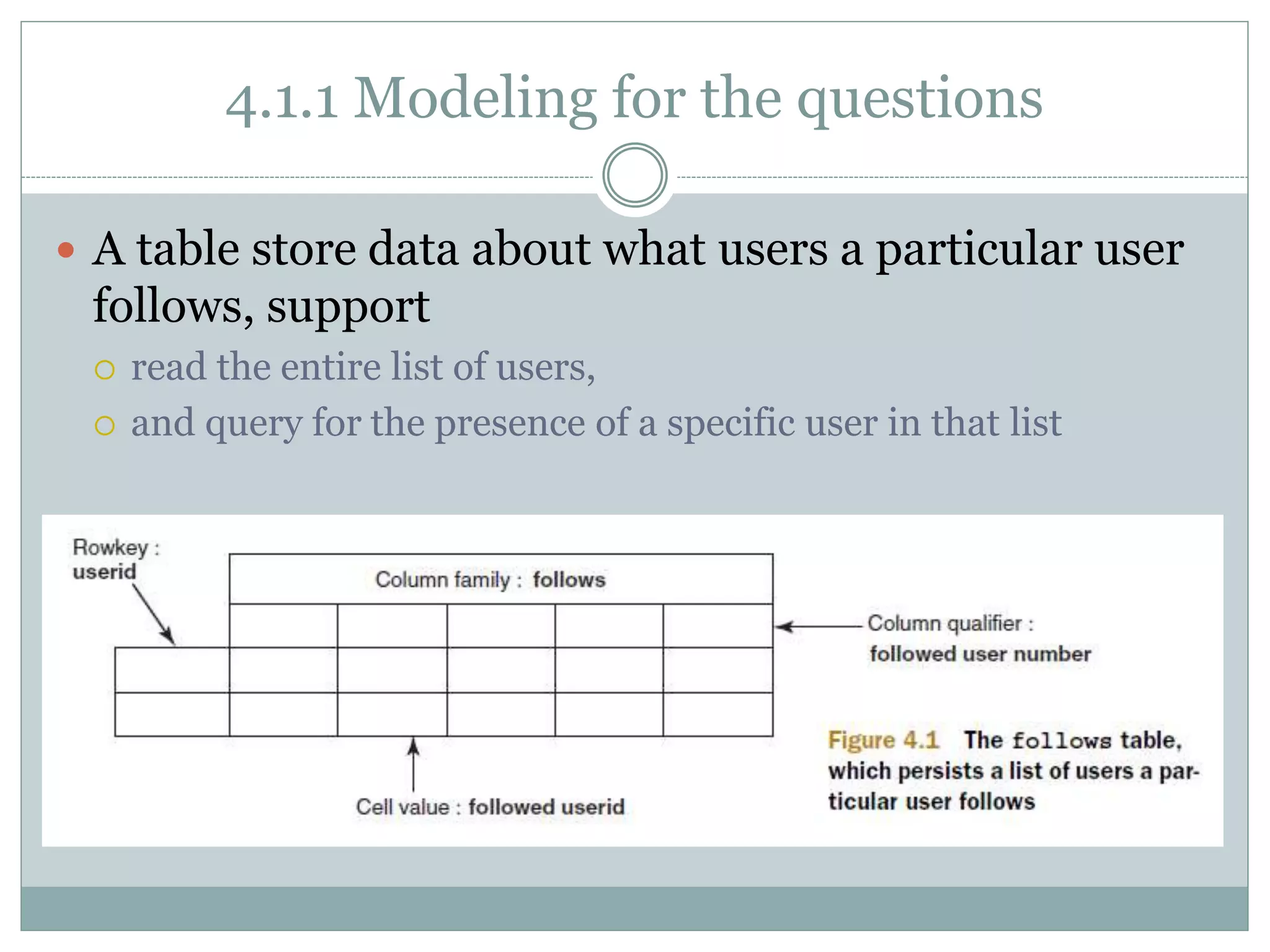
Only the keys are indexed in HBase tables.
There are two ways to retrieve data from a table: Get and
Scan.
HBase tables are flexible, and you can store anything in
the form of byte[].
Store everything with similar access patterns in the same
column family.
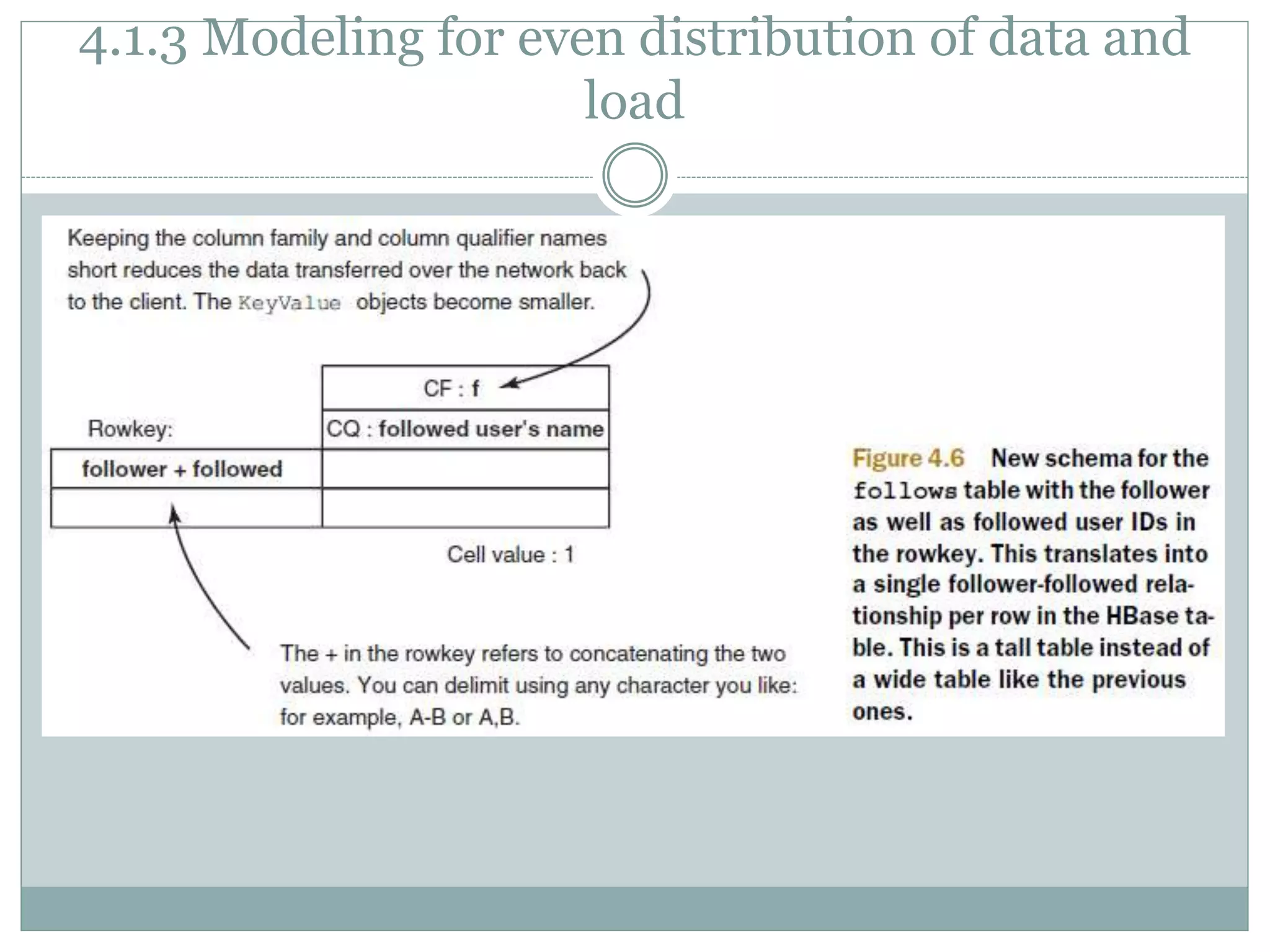
Indexing is done on the Key portion of the KeyValue
objects, consisting of the rowkey, qualifier, and
timestamp in that order.
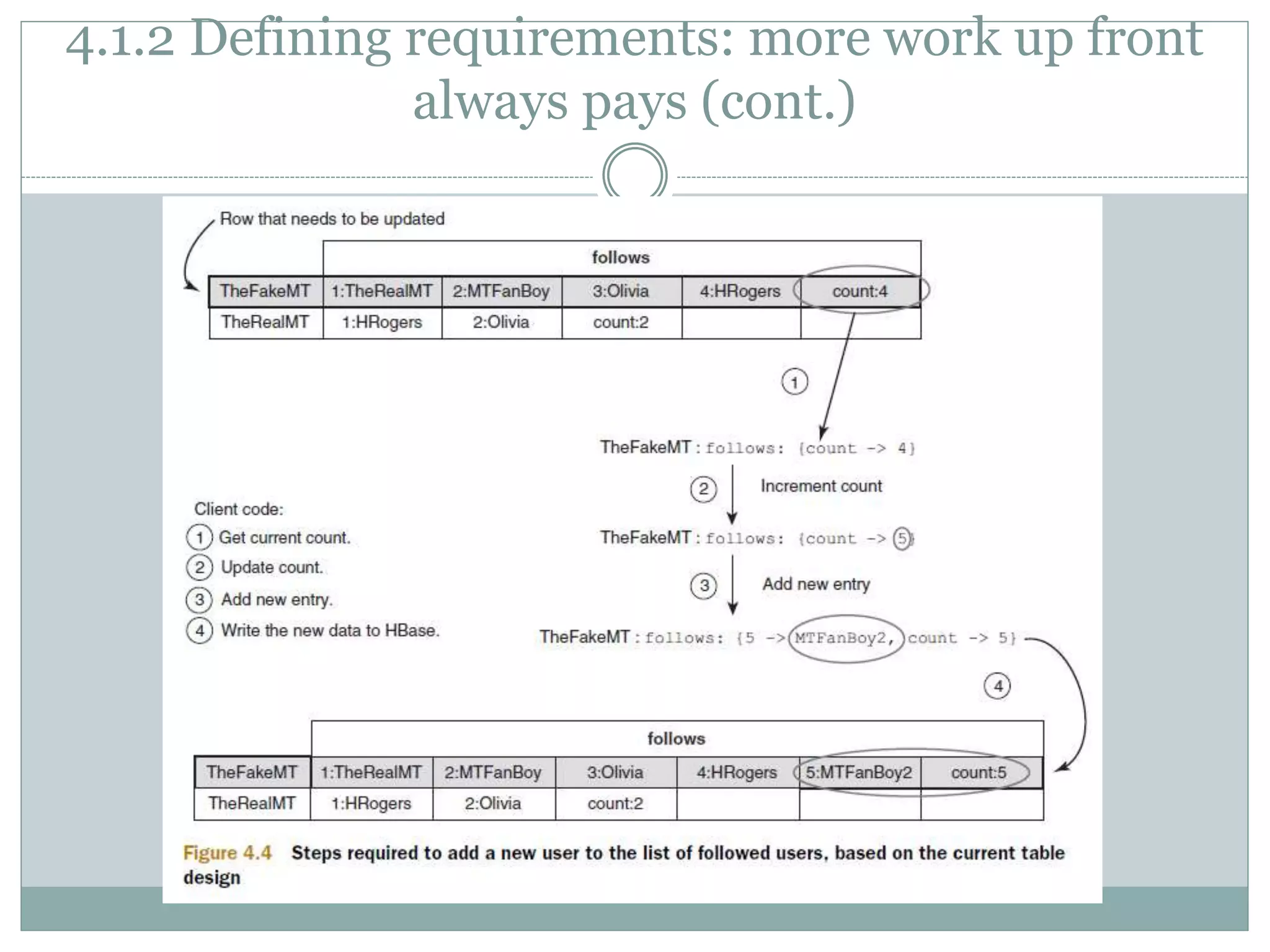
Tall tables can potentially allow you to move toward O(1)
operations, but you trade atomicity](https://image.slidesharecdn.com/hbaseinaction-ch04-150924011730-lva1-app6891/75/HBase-In-Action-Chapter-04-HBase-table-design-13-2048.jpg)































































![[Spark meetup] Spark Streaming Overview](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmeetupstratiostreaming-150121022614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




























































