Download as PDF, PPTX

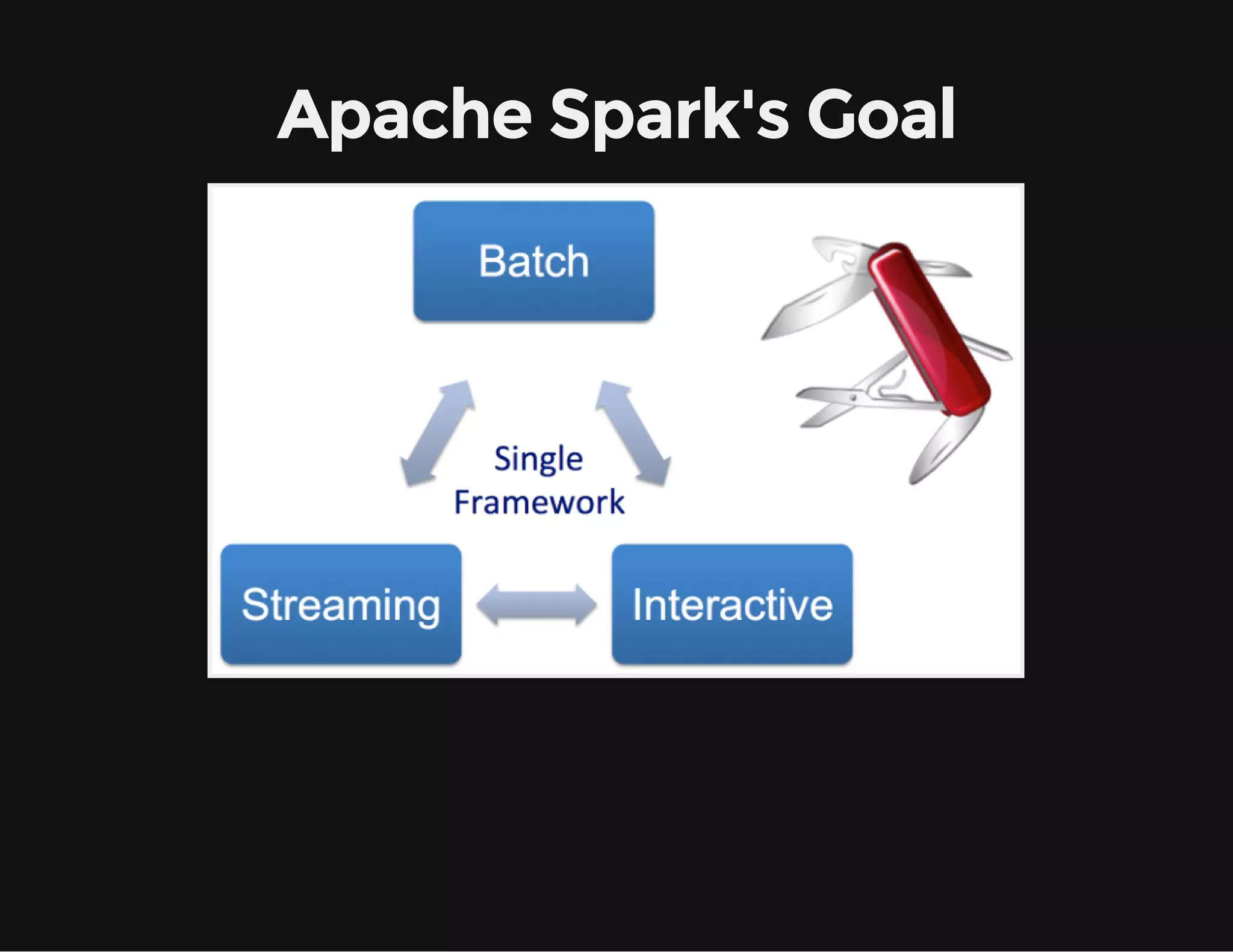

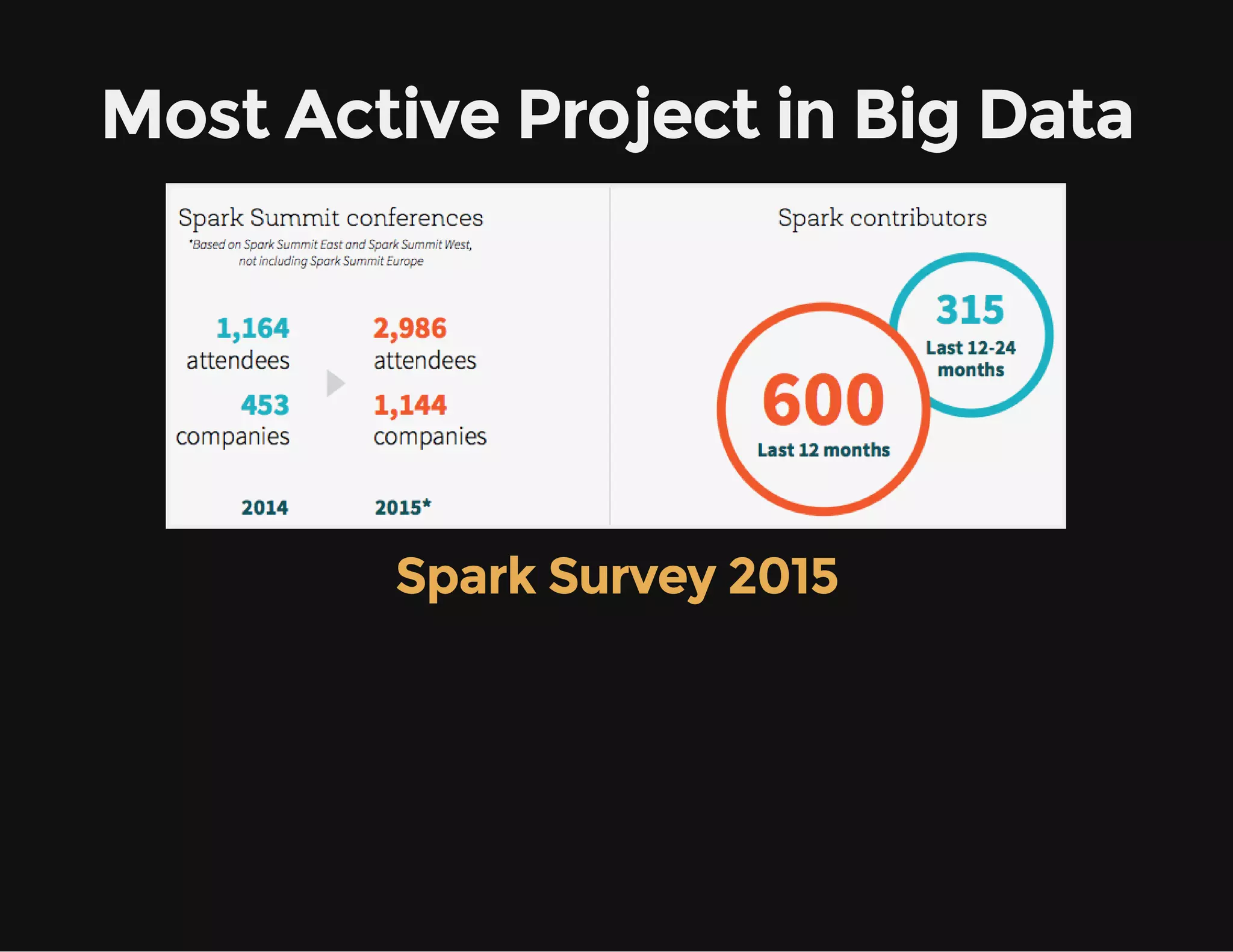

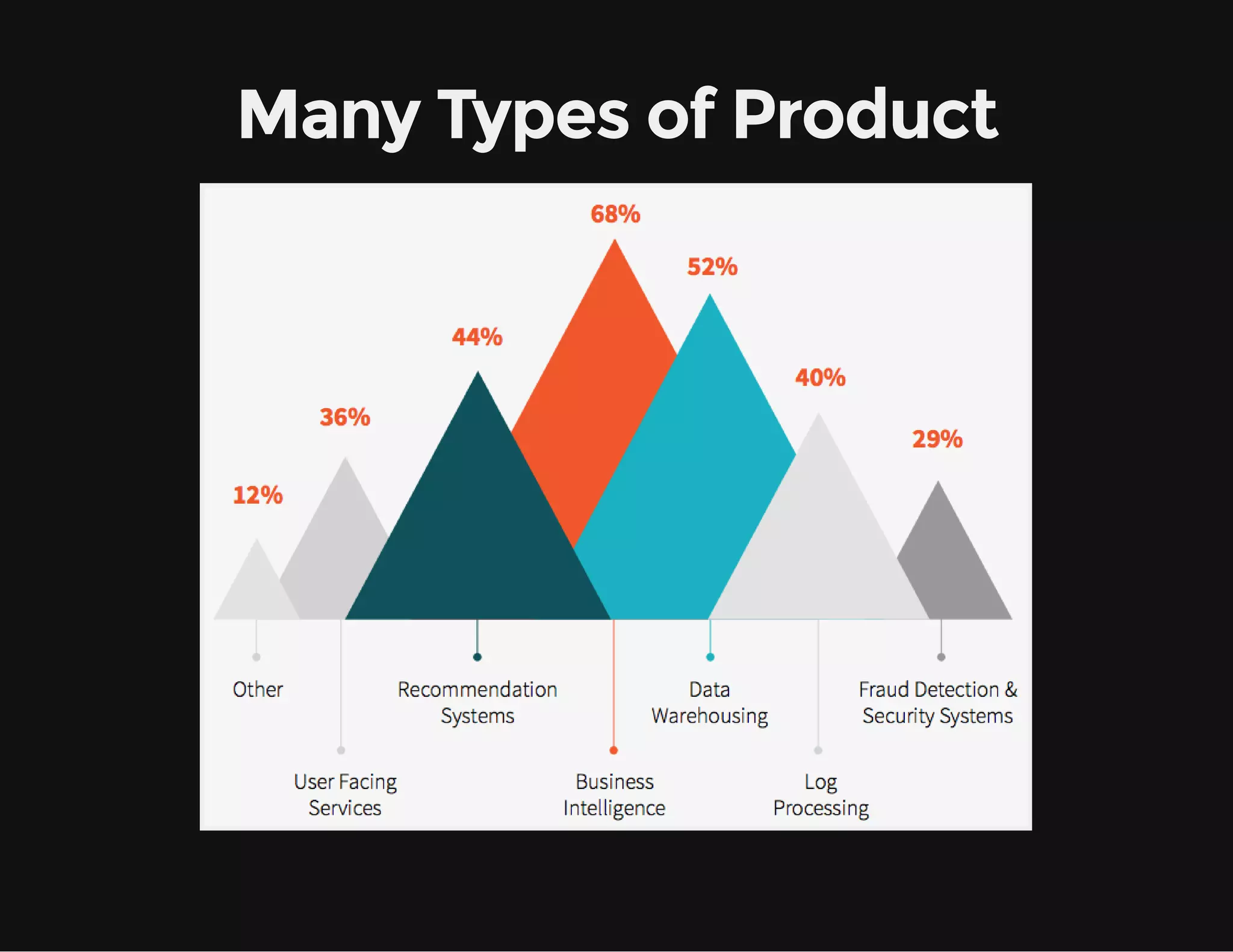







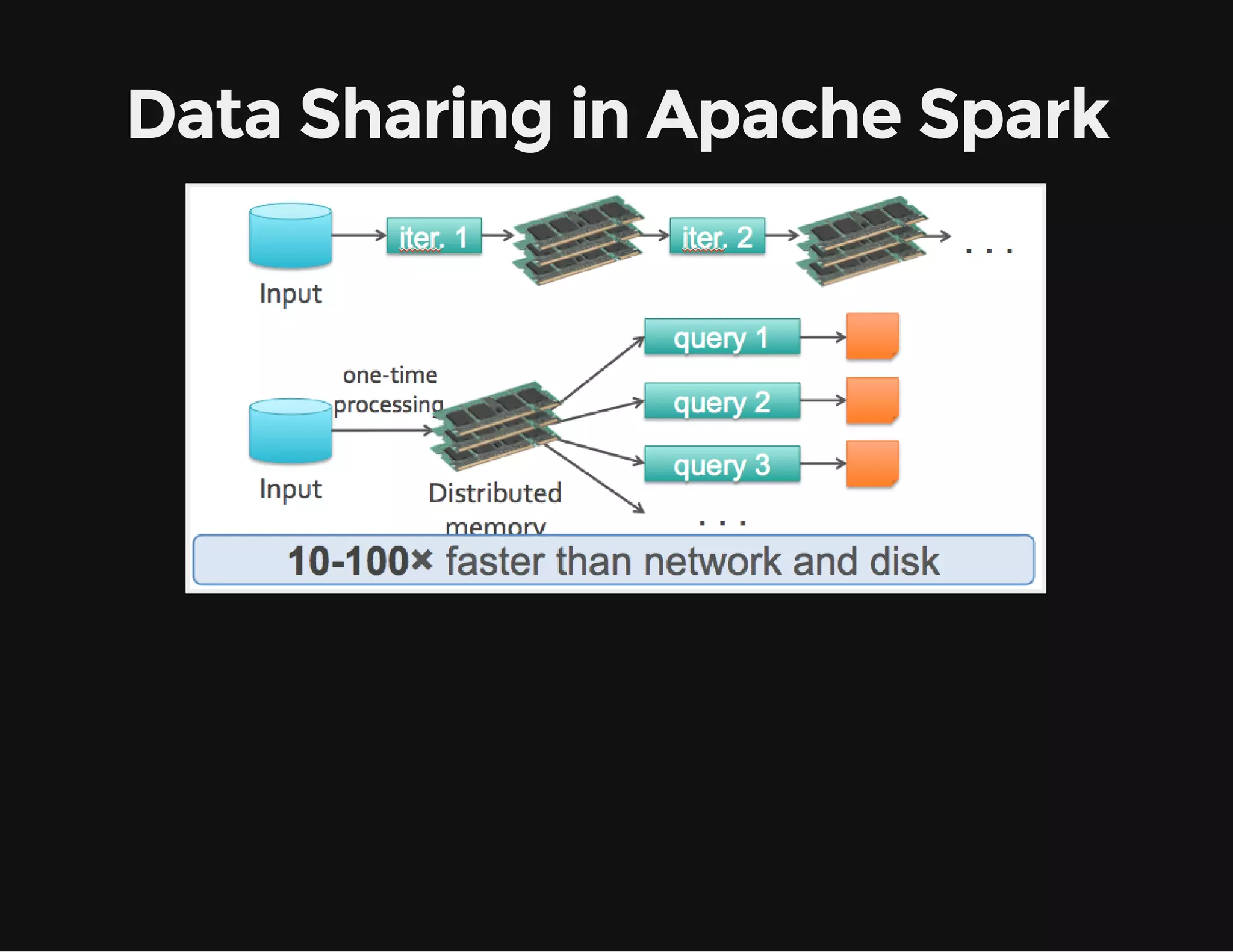
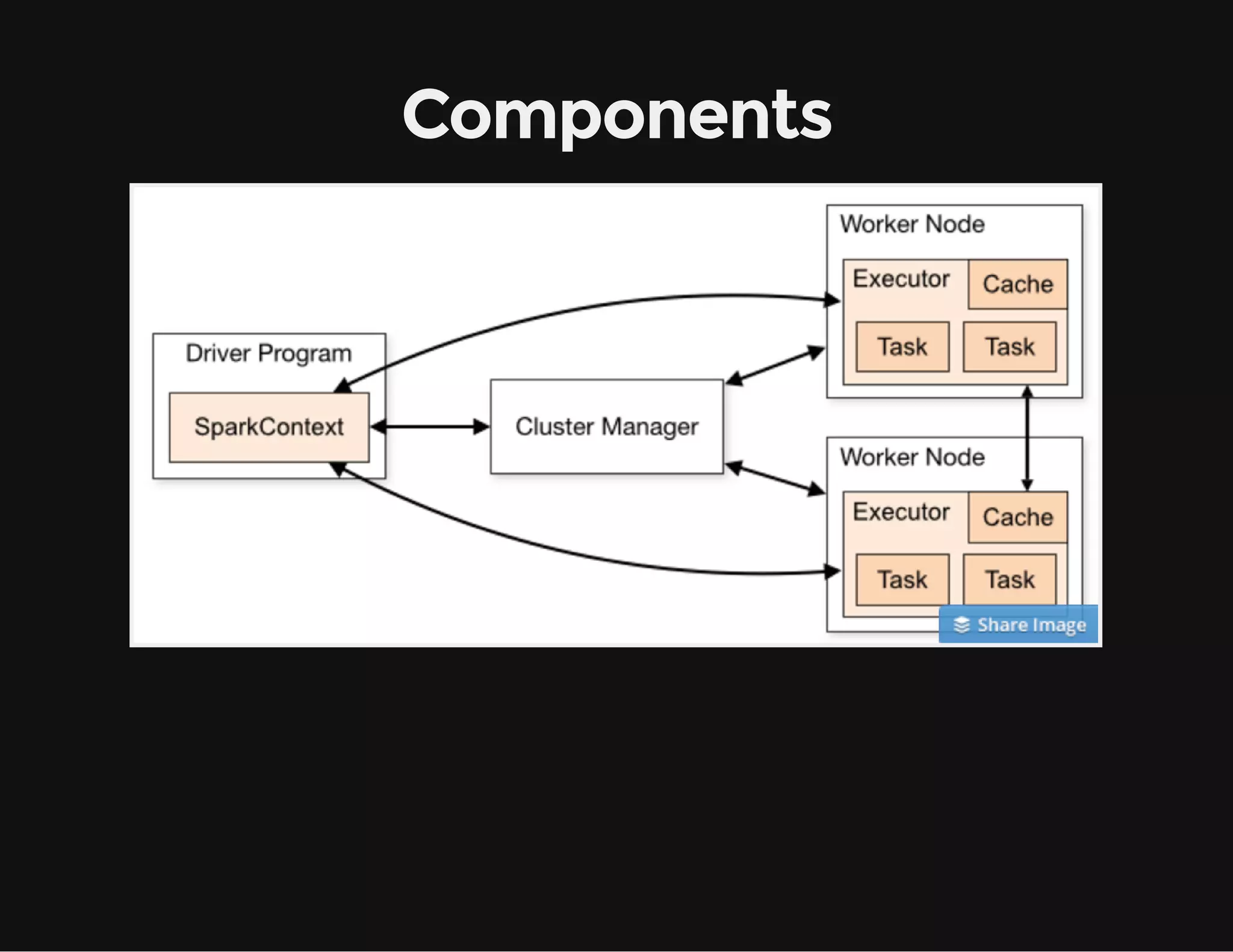
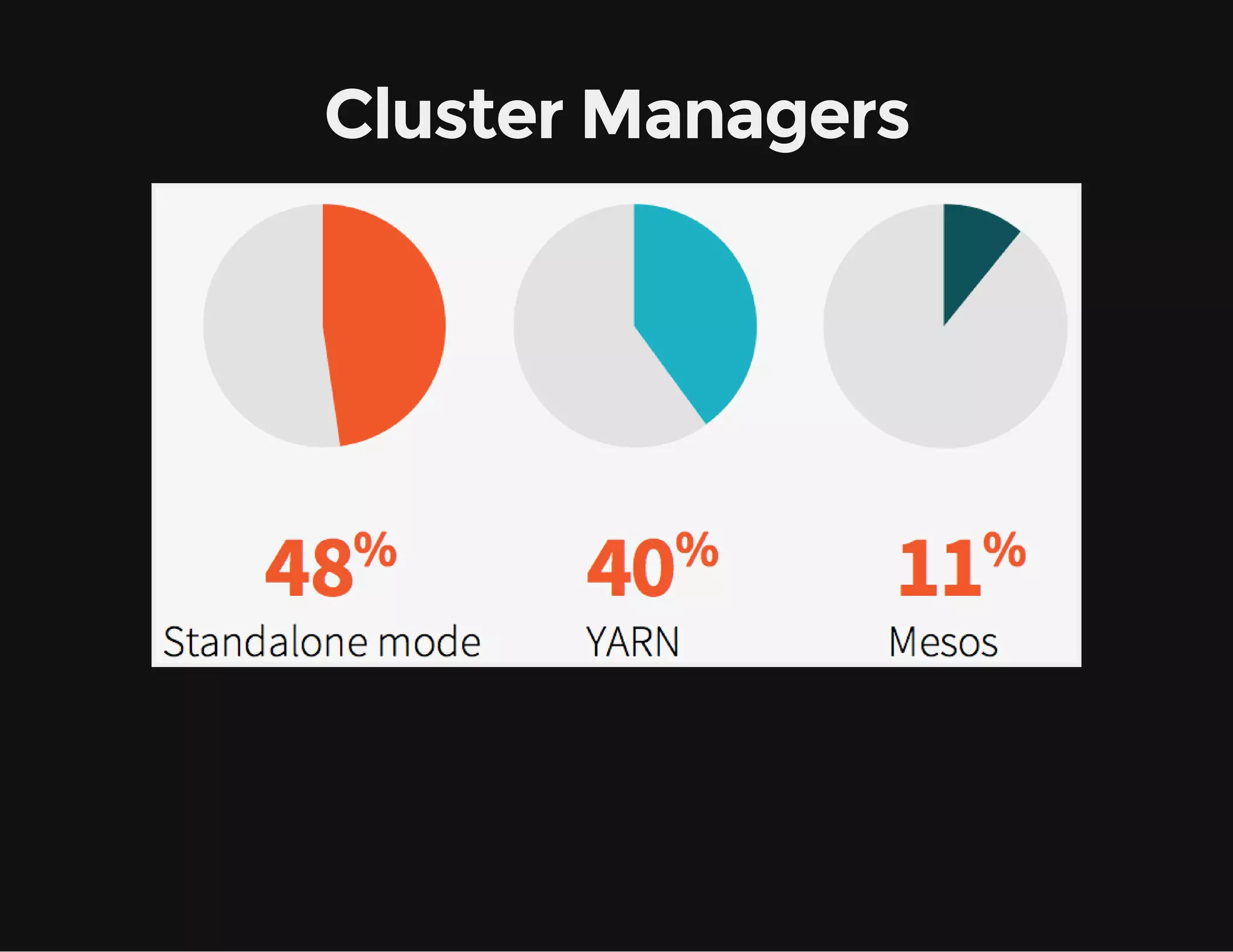






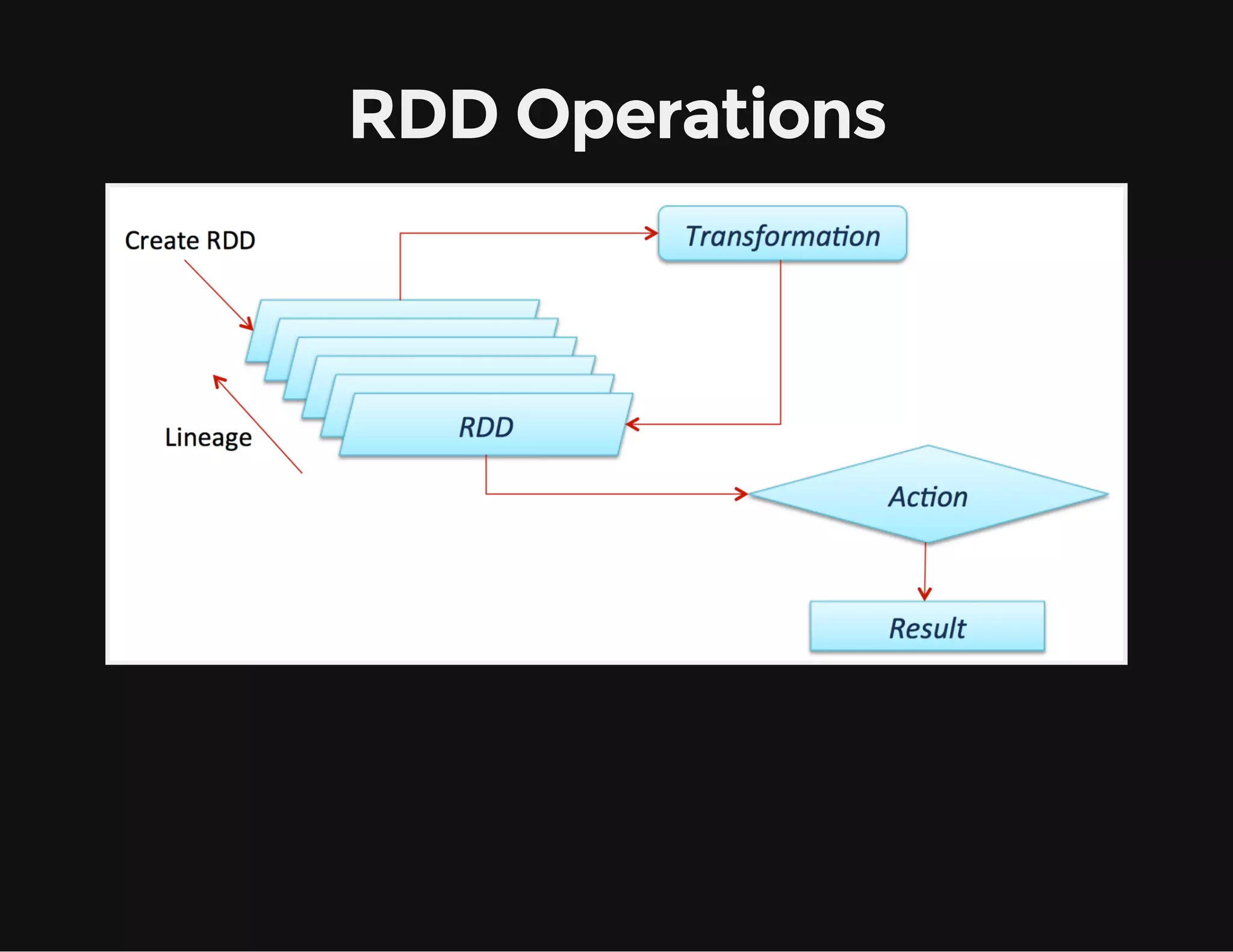


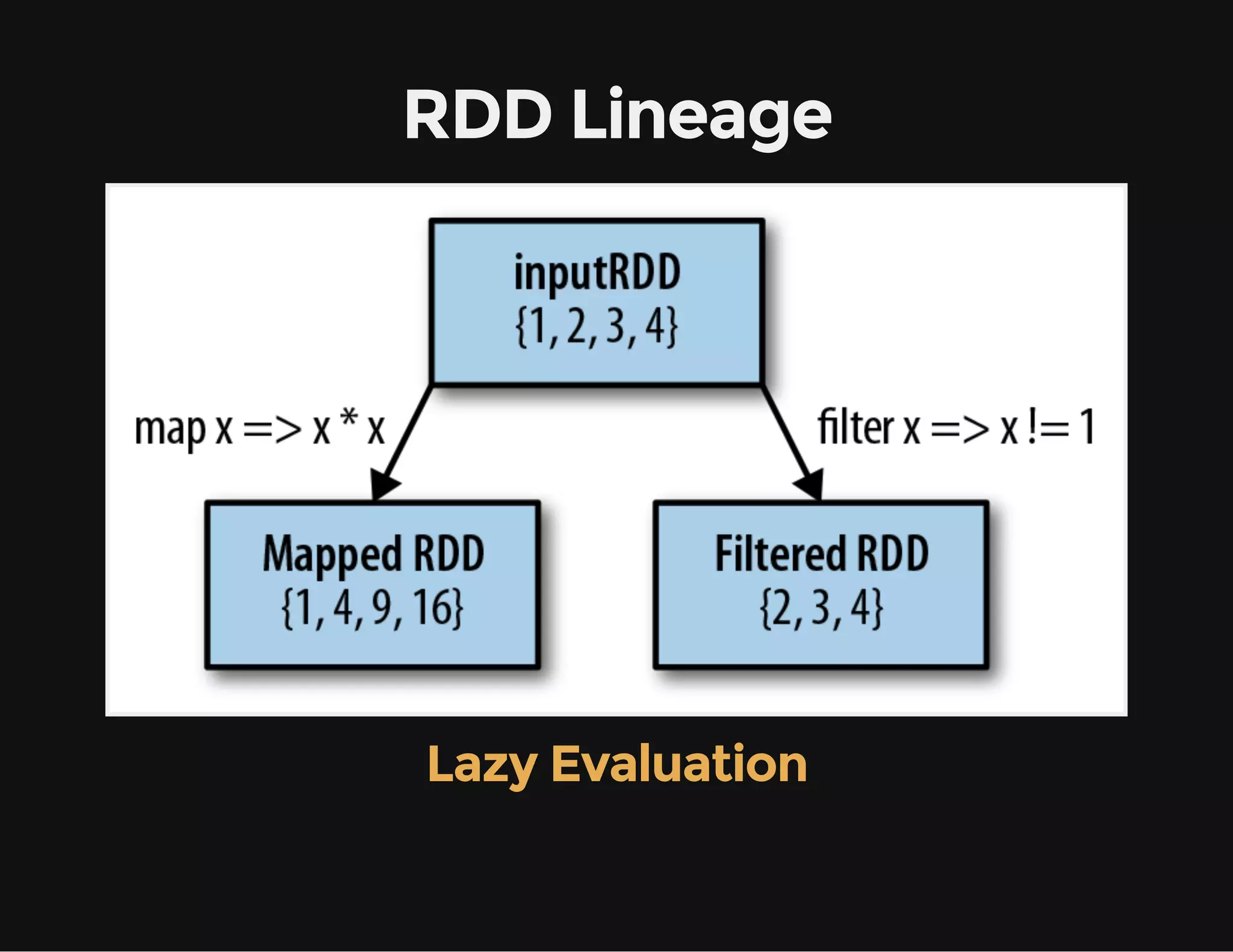

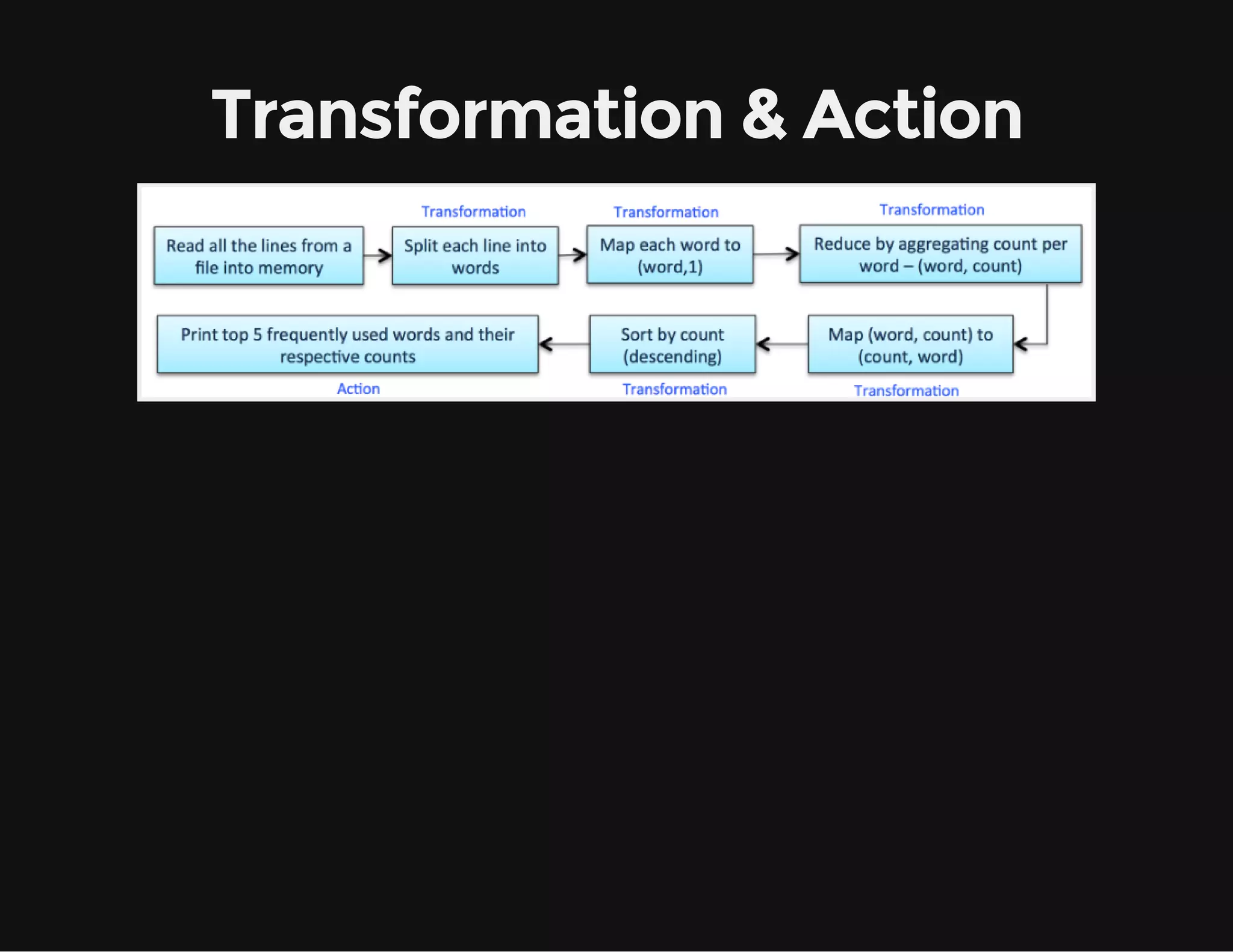



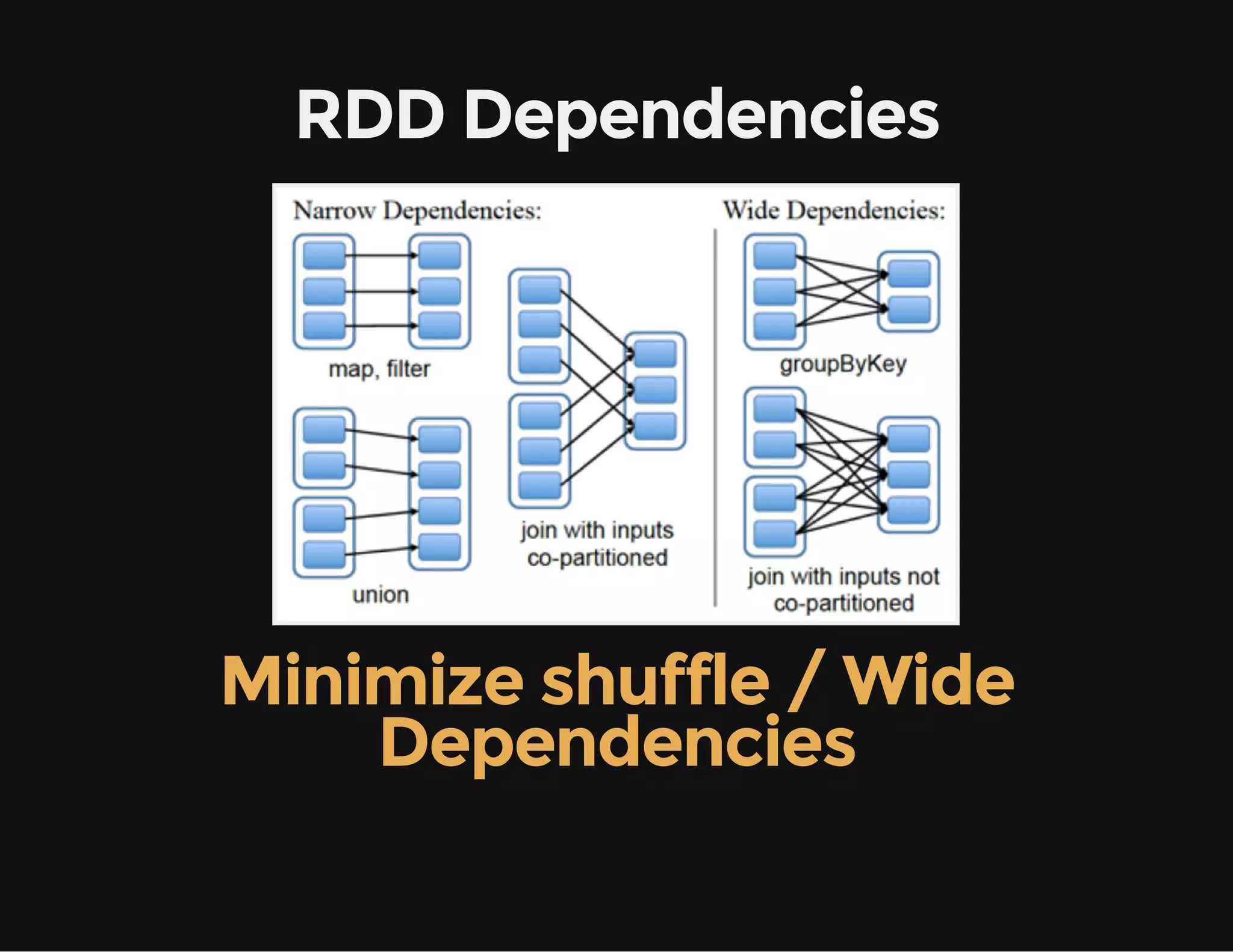







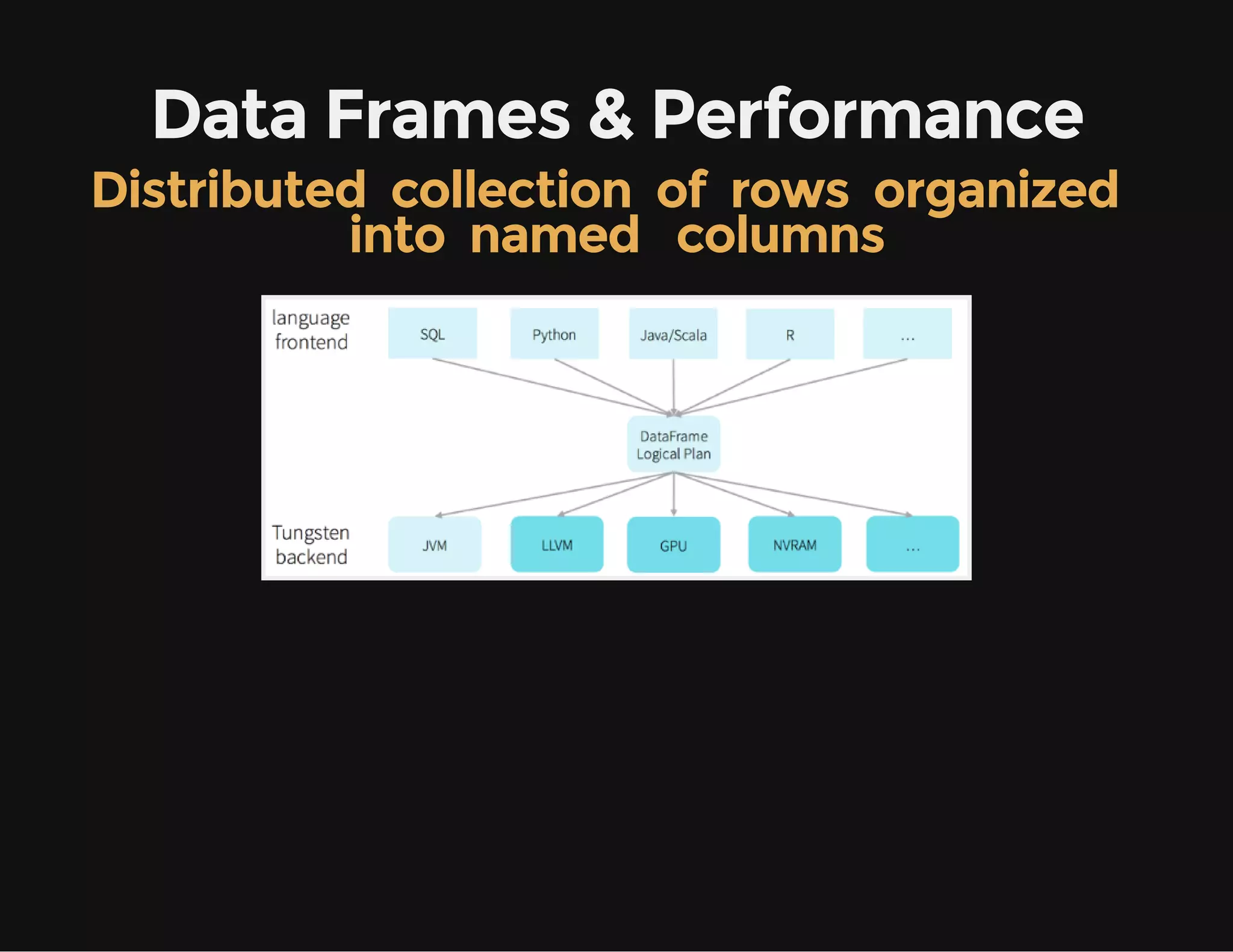






This document provides an overview of Apache Spark, including its goal of providing a fast and general engine for large-scale data processing. It discusses Spark's programming model, components like RDDs and DAGs, and how to initialize and deploy Spark on a cluster. Key aspects covered include RDDs as the fundamental data structure in Spark, transformations and actions, and storage levels for caching data in memory or disk.




























![Apache Spark 101 [in 50 min]](https://cdn.slidesharecdn.com/ss_thumbnails/apachespark101-in50min1-150227110033-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









































![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)


