Downloaded 273 times





![Example
14
sc.textFile(“/wiki/pagecounts”) RDD[String]
textFile](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-14-2048.jpg)
![Example
15
sc.textFile(“/wiki/pagecounts”)
.map(line => line.split(“t”))
RDD[String]
textFile map
RDD[List[String]]](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-15-2048.jpg)
![Example
16
sc.textFile(“/wiki/pagecounts”)
.map(line => line.split(“t”))
.map(R => (R[0], int(R[1])))
RDD[String]
textFile map
RDD[List[String]]
RDD[(String, Int)]
map](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-16-2048.jpg)
![Example
17
sc.textFile(“/wiki/pagecounts”)
.map(line => line.split(“t”))
.map(R => (R[0], int(R[1])))
.reduceByKey(_+_)
RDD[String]
textFile map
RDD[List[String]]
RDD[(String, Int)]
map
RDD[(String, Int)]
reduceByKey](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-17-2048.jpg)
![Example
18
sc.textFile(“/wiki/pagecounts”)
.map(line => line.split(“t”))
.map(R => (R[0], int(R[1])))
.reduceByKey(_+_, 3)
.collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
RDD[(String, Int)]
reduceByKey
Array[(String, Int)]
collect](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-18-2048.jpg)



![Collections and External Datasets
• A Collection can be parallelized using the SparkContext
– val data = Array(1, 2, 3, 4, 5)
– val distData = sc.parallelize(data)
• Spark can create distributed dataset from HDFS, Cassandra,
Hbase, Amazon S3, etc.
• Spark supports text files, Sequence Files and any other
Hadoop input format
• Files can be read from an URI local or remote (hdfs://, s3n://)
– scala> val distFile = sc.textFile("data.txt")
– distFile: RDD[String] = MappedRDD@1d4cee08
– distFile.map(s => s.length).reduce((a,b) => a + b)
26](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-26-2048.jpg)

![Passing a function to Spark
• Spark is based on Anonymous function syntax
– (x: Int) => x *x
• Which is a shorthand for
new Function1[Int,Int] {
def apply(x: Int) = x * x
}
• We can define functions with more parameters and without
– (x: Int, y: Int) => "(" + x + ", " + y + ")”
– () => { System.getProperty("user.dir") }
• The syntax is a shorthand for
– Funtion1[T,+E] … Function22[…]
28](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-28-2048.jpg)
![Passing a function to Spark
object MyFunctions {
def func1(s: String): String = s + s
}
file.map(MyFunctions.func1)
class MyClass {
def func1(s: String): String = { ... }
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(func1) }
}
29](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-29-2048.jpg)







![Broadcast Variables
• Broadcast variables allow the programmer to keep a
read-only variable cached on each machine rather
than shipping a copy of it with tasks.
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] =
Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
37](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-37-2048.jpg)
![Accumulators
• Accumulators are variables that are only “added” to through
an associative operation and can therefore be efficiently
supported in parallel
• Spark natively supports accumulators of numeric types, and
programmers can add support for new types
• Note: not yet supported on Python
scala> val accum = sc.accumulator(0, "My Accumulator")
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
scala> accum.value
res7: Int = 10
38](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-38-2048.jpg)
![Accumulators
object VectorAccumulatorParam extends AccumulatorParam[Vector] {
def zero(initialValue: Vector): Vector = {
Vector.zeros(initialValue.size)
}
def addInPlace(v1: Vector, v2: Vector): Vector = {
v1 += v2
}
}
// Then, create an Accumulator of this type:
val vecAccum = sc.accumulator(new Vector(...))(VectorAccumulatorParam)
39](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-39-2048.jpg)

![Create a Self Contained App in
Scala
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
41](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-41-2048.jpg)

![Project folder
• That how the project directory should look
$ find .
.
./simple.sbt
./src
./src/main
./src/main/scala
./src/main/scala/SimpleApp.scala
• With sbt package we can create the jar
• To submit the job
$ YOUR_SPARK_HOME/bin/spark-submit
--class "SimpleApp"
--master local[4]
target/scala-2.10/simple-project_2.10-1.0.jar
43](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-43-2048.jpg)

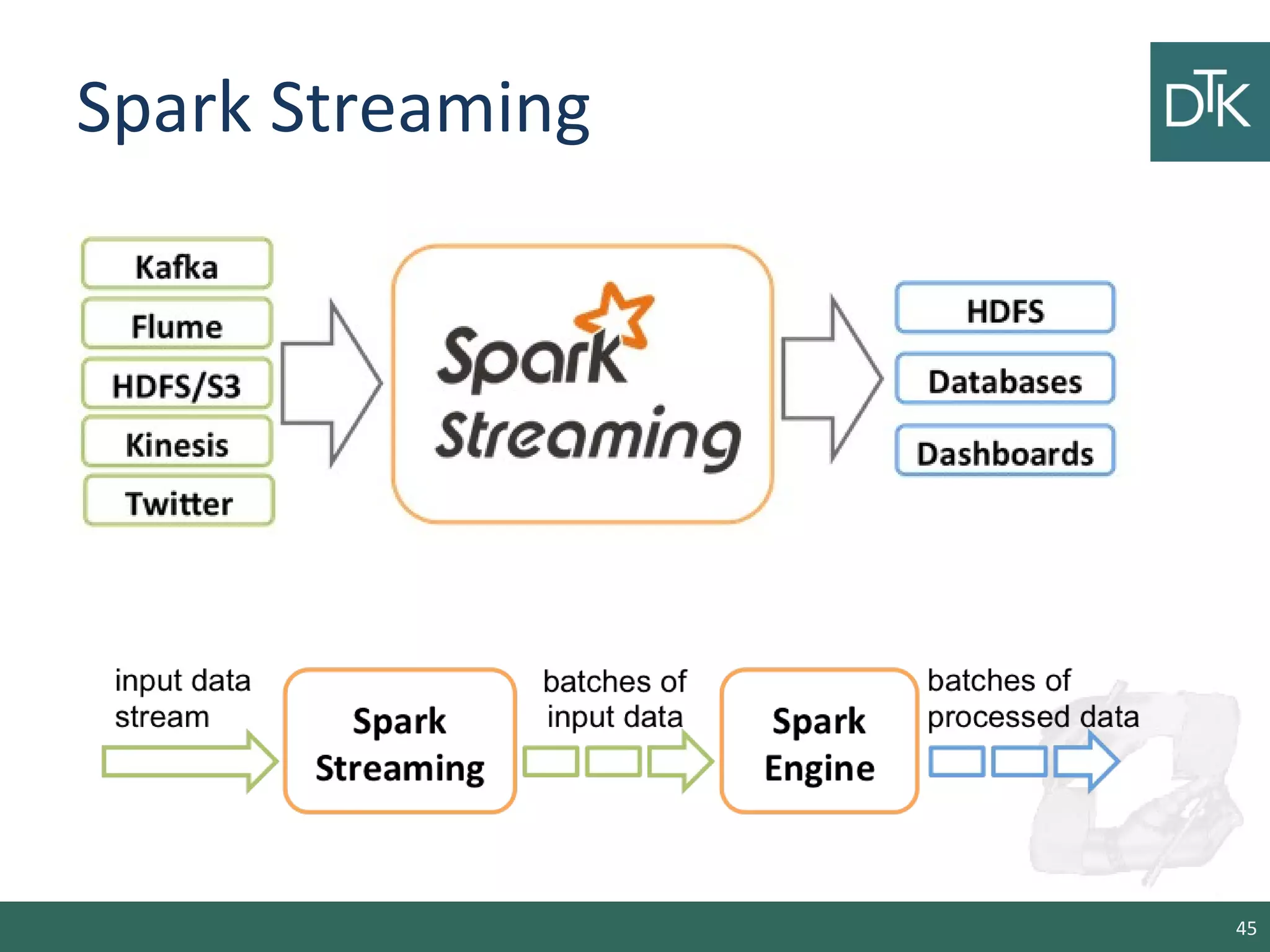
![A simple example
• We create a local StreamingContext with two execution
threads, and batch interval of 1 second.
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// Create a local StreamingContext with two working thread and batch
interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new
SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
46](https://image.slidesharecdn.com/6-150108024847-conversion-gate02/75/Scala-and-spark-46-2048.jpg)




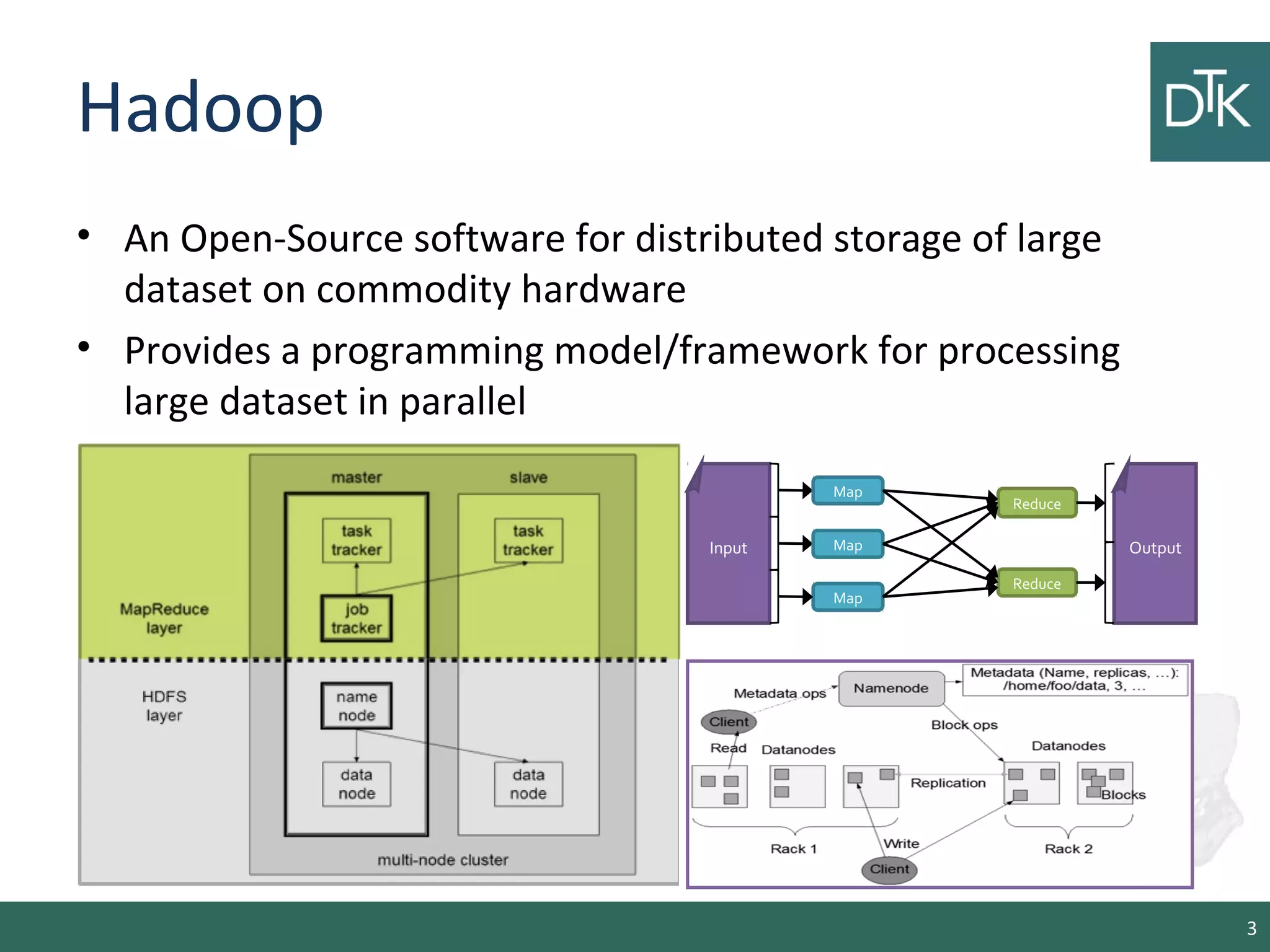
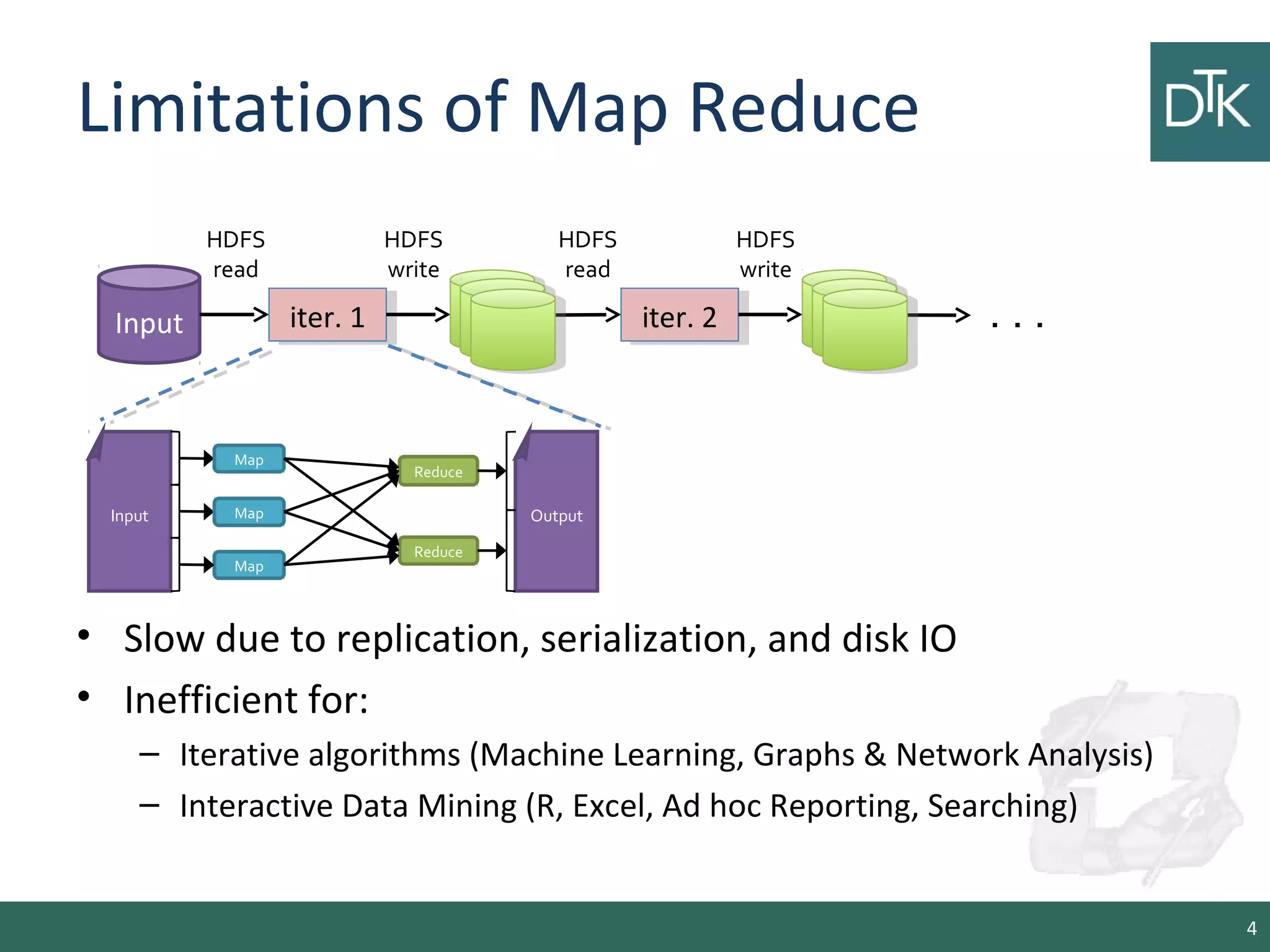
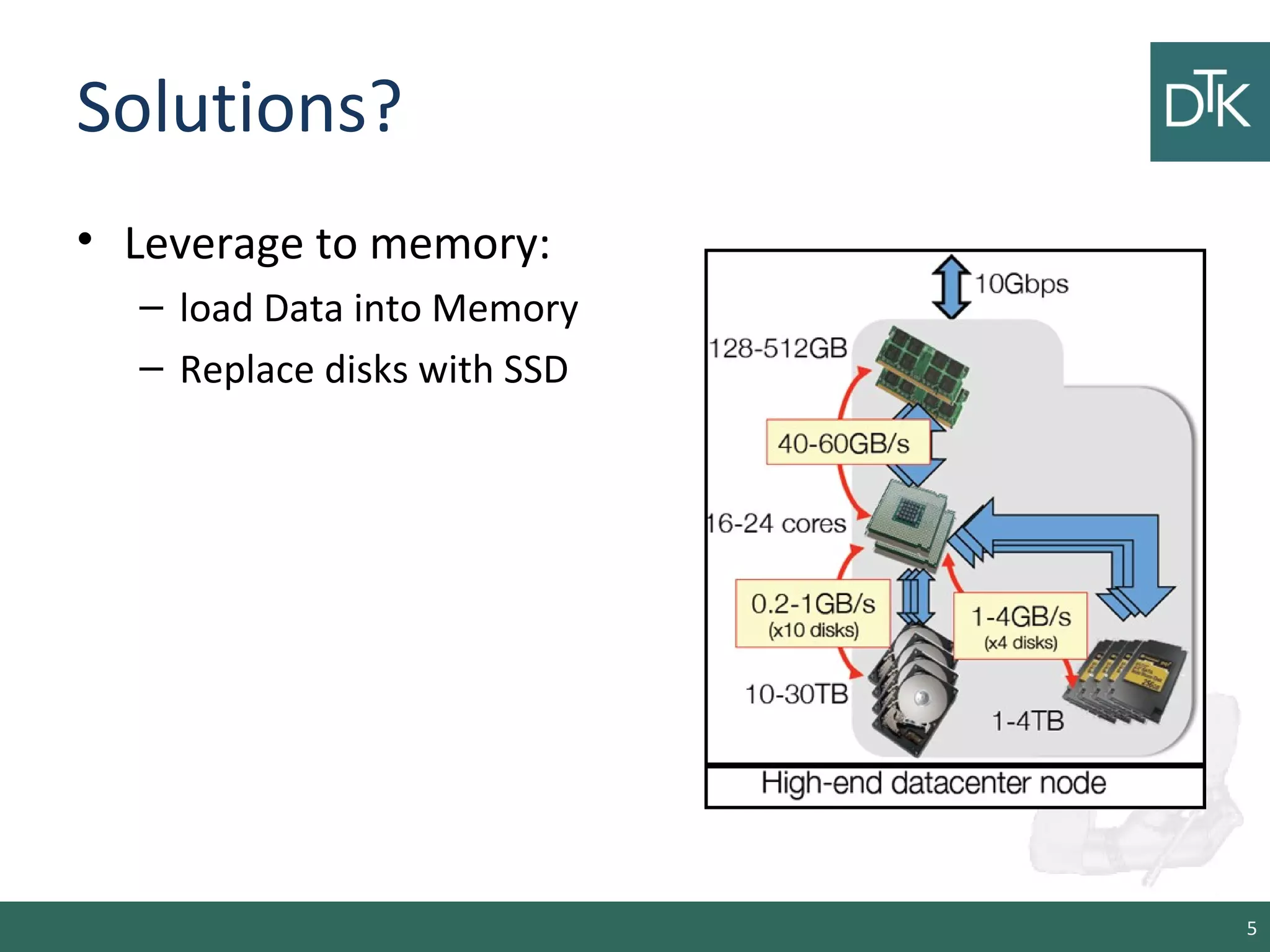
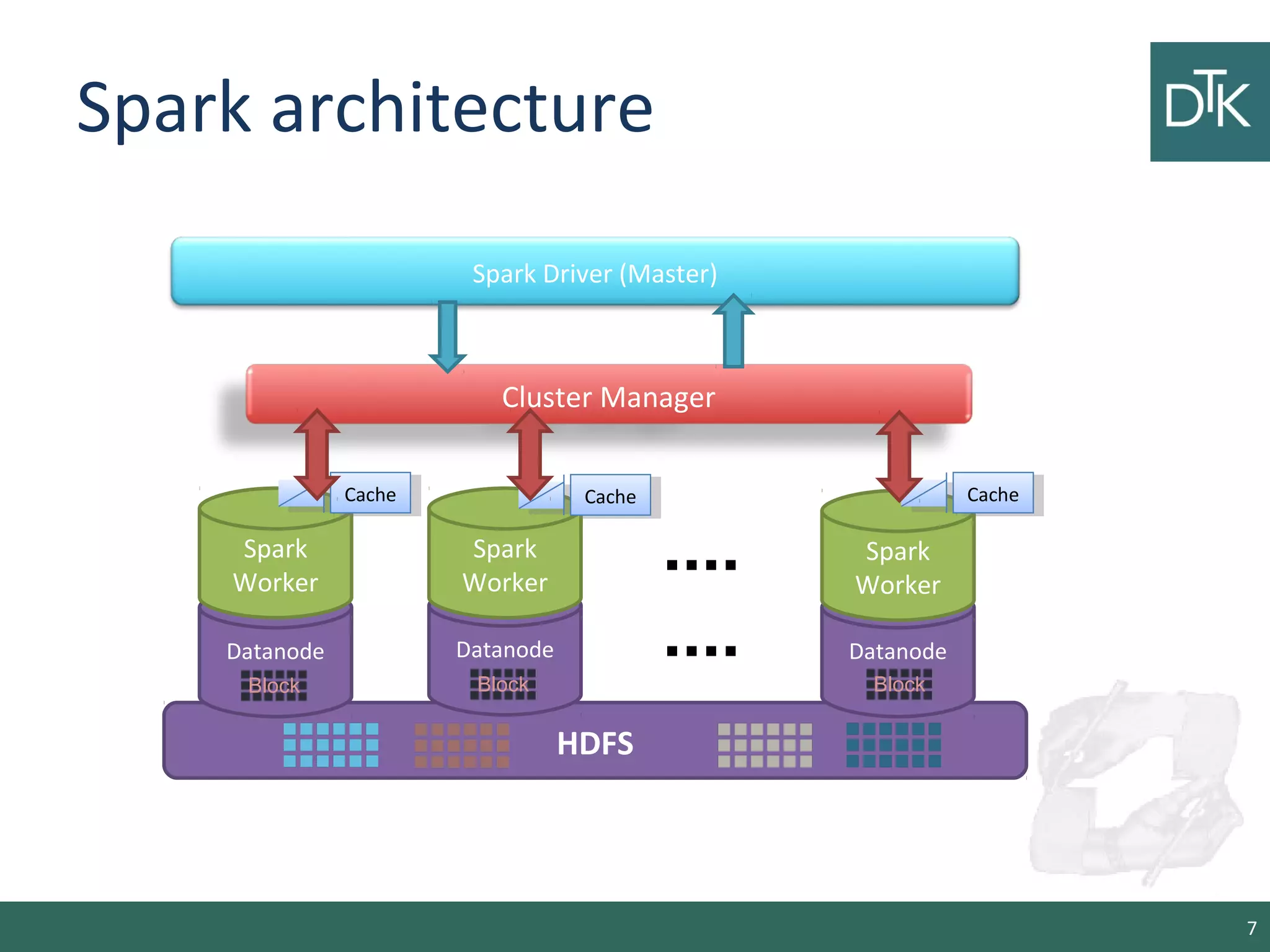
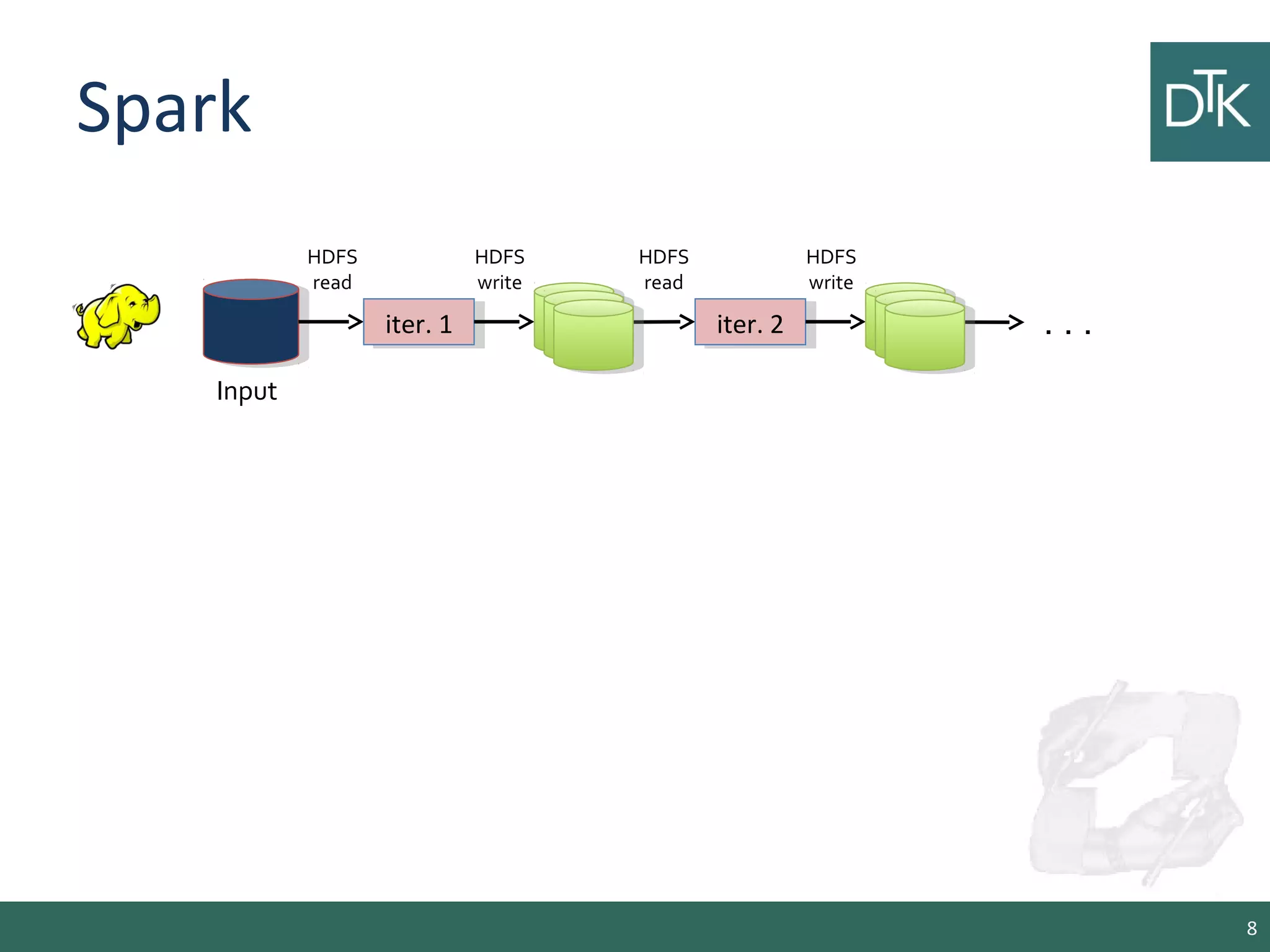
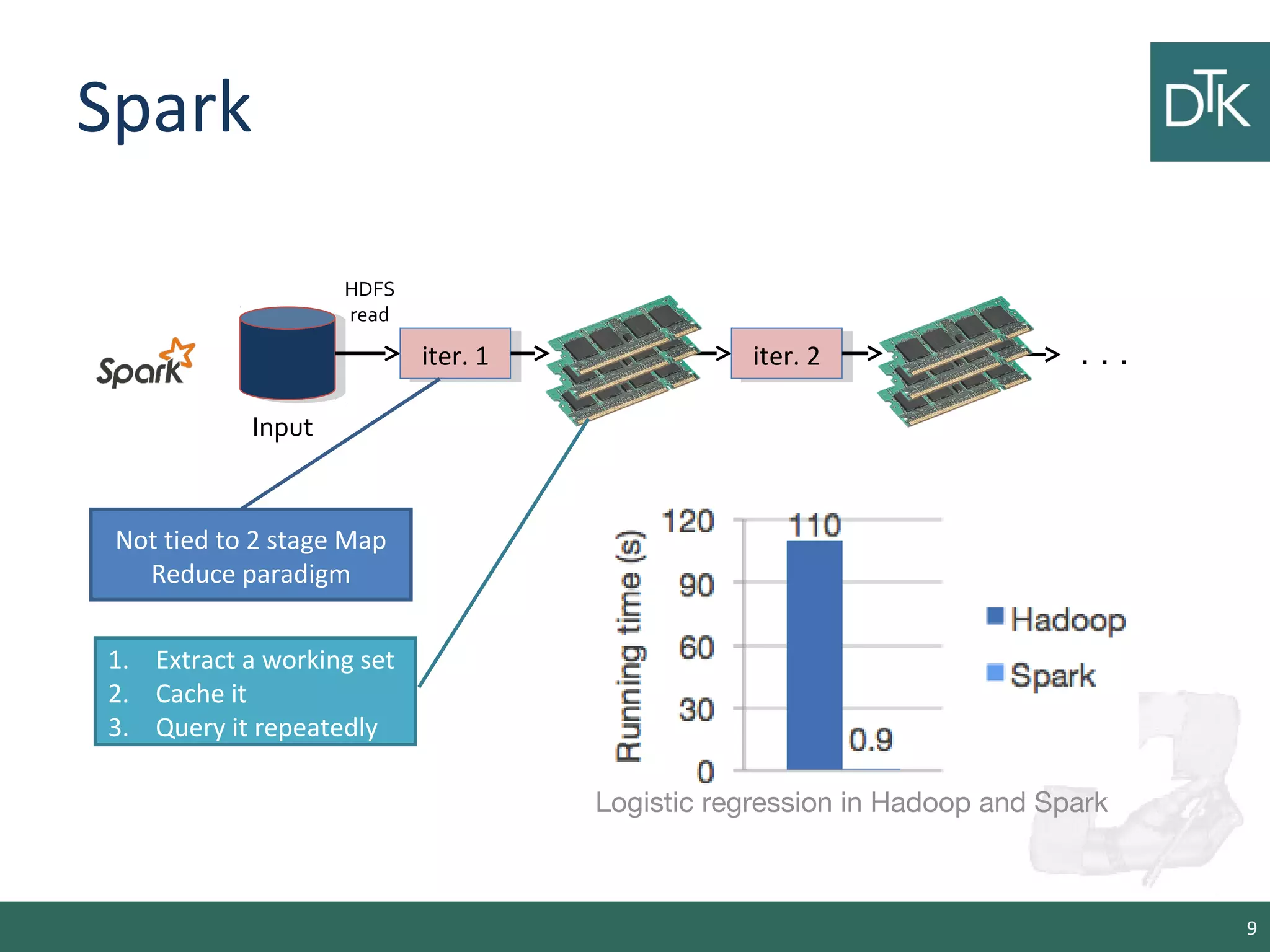
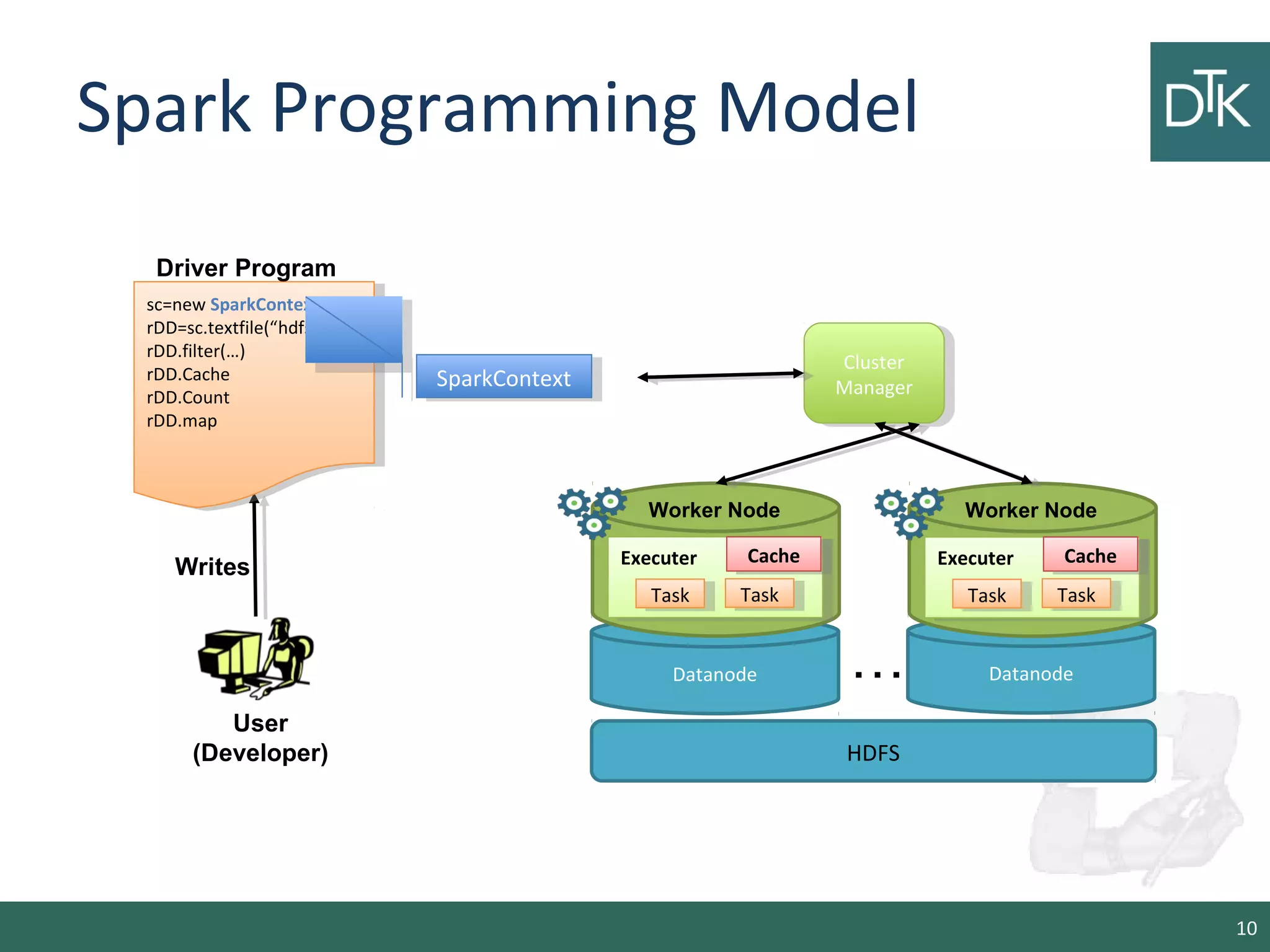
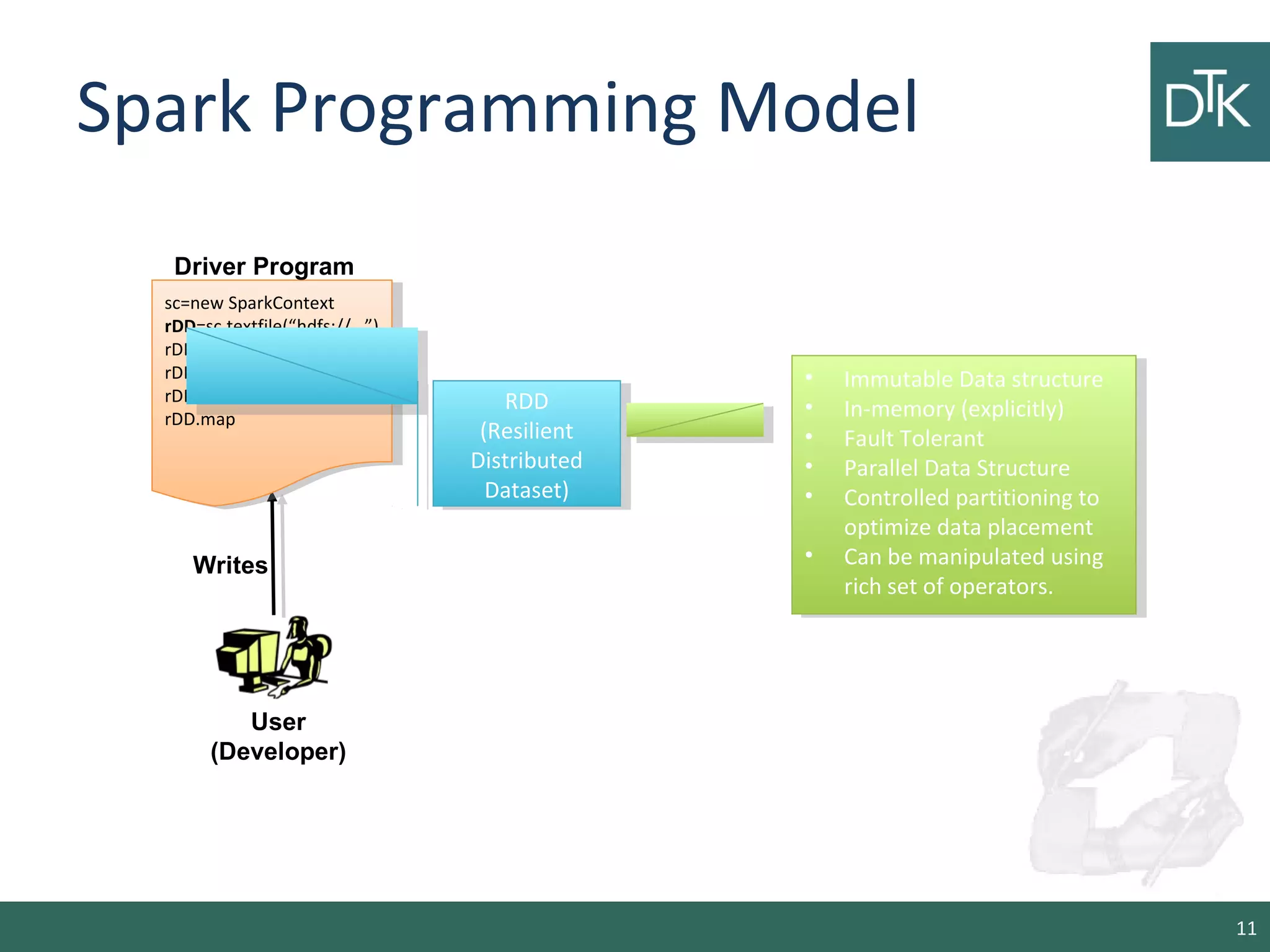
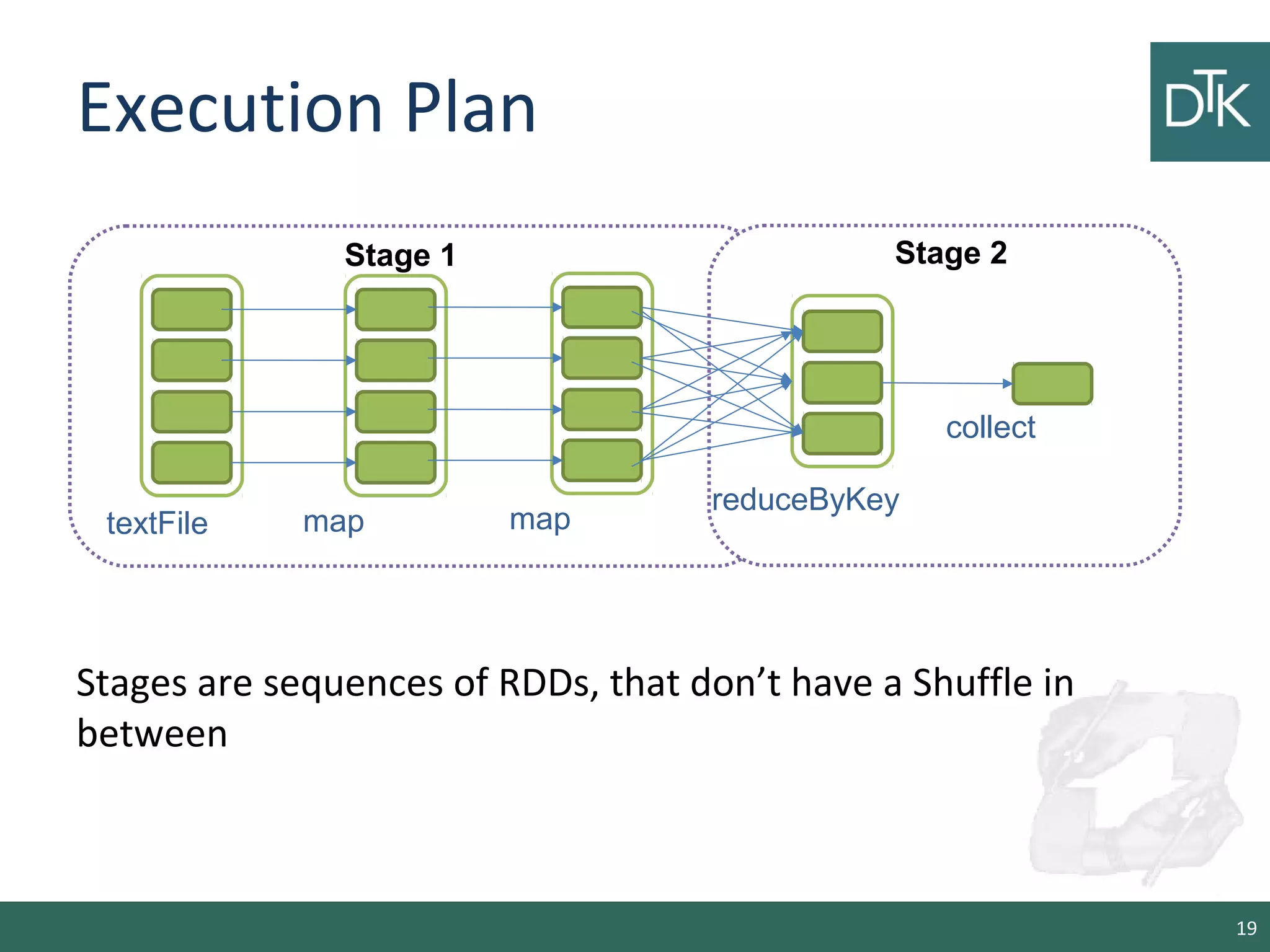
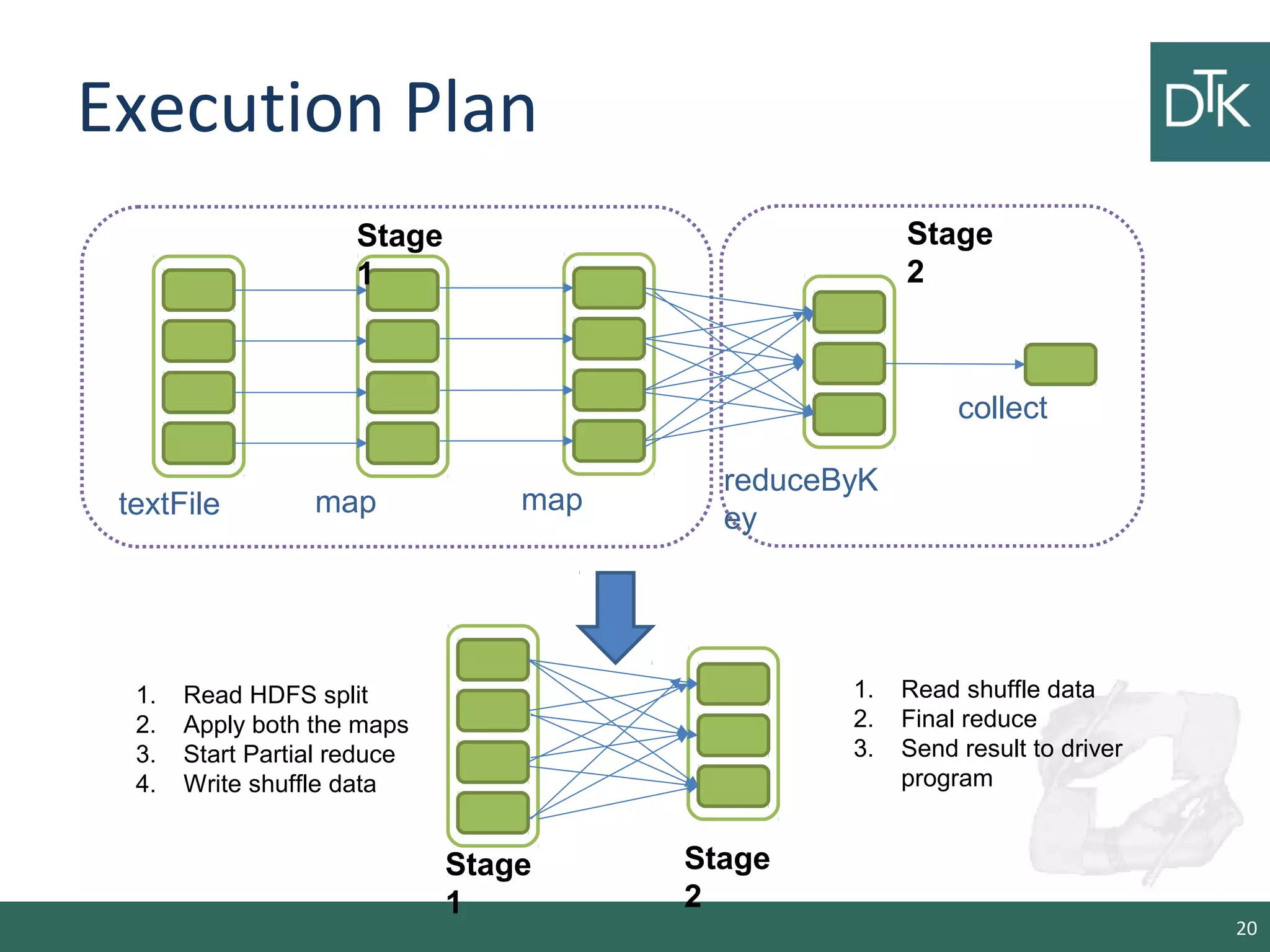
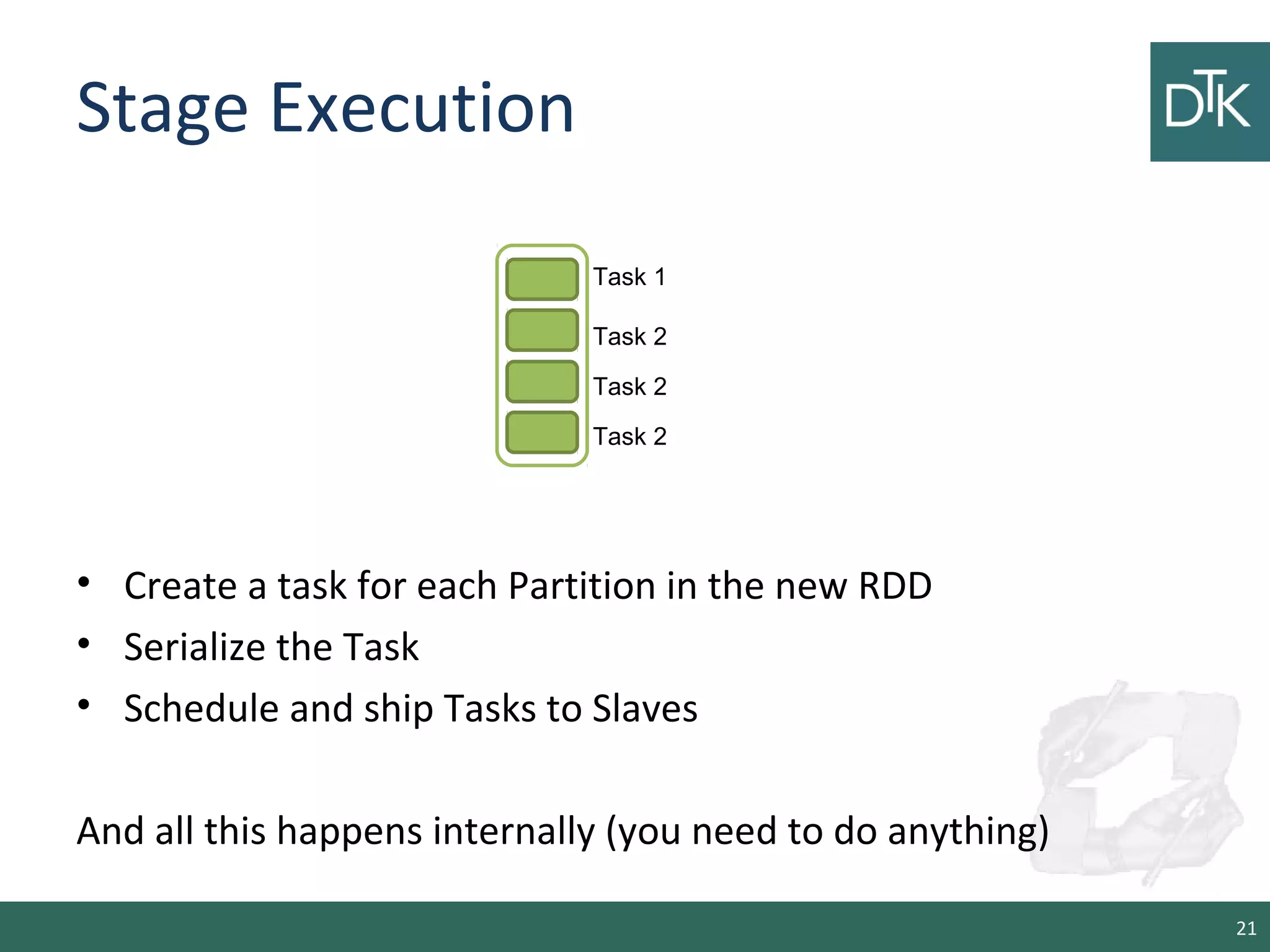
This document provides an introduction to Apache Spark, including its architecture and programming model. Spark is a cluster computing framework that provides fast, in-memory processing of large datasets across multiple cores and nodes. It improves upon Hadoop MapReduce by allowing iterative algorithms and interactive querying of datasets through its use of resilient distributed datasets (RDDs) that can be cached in memory. RDDs act as immutable distributed collections that can be manipulated using transformations and actions to implement parallel operations.