Download as PDF, PPTX


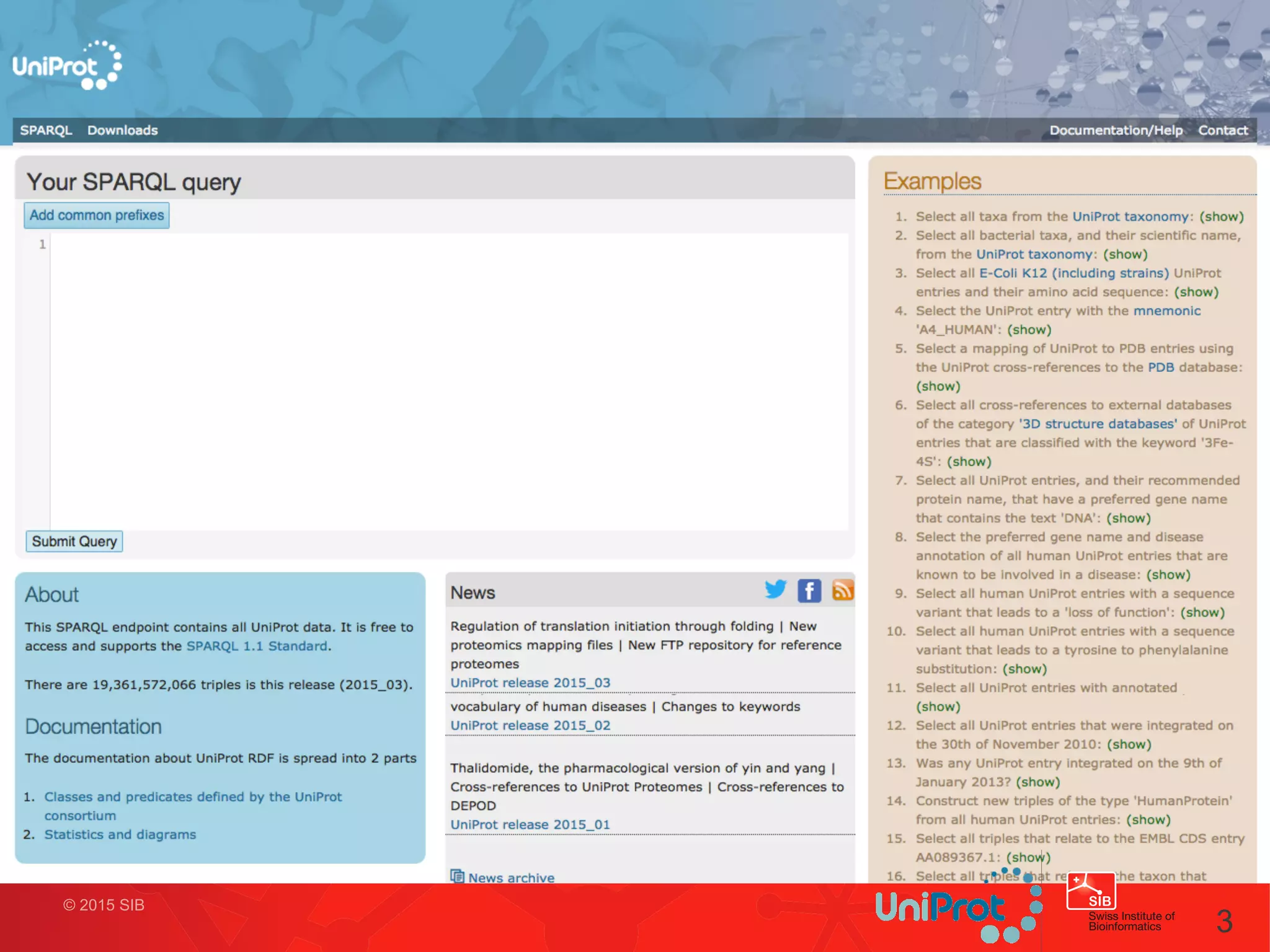

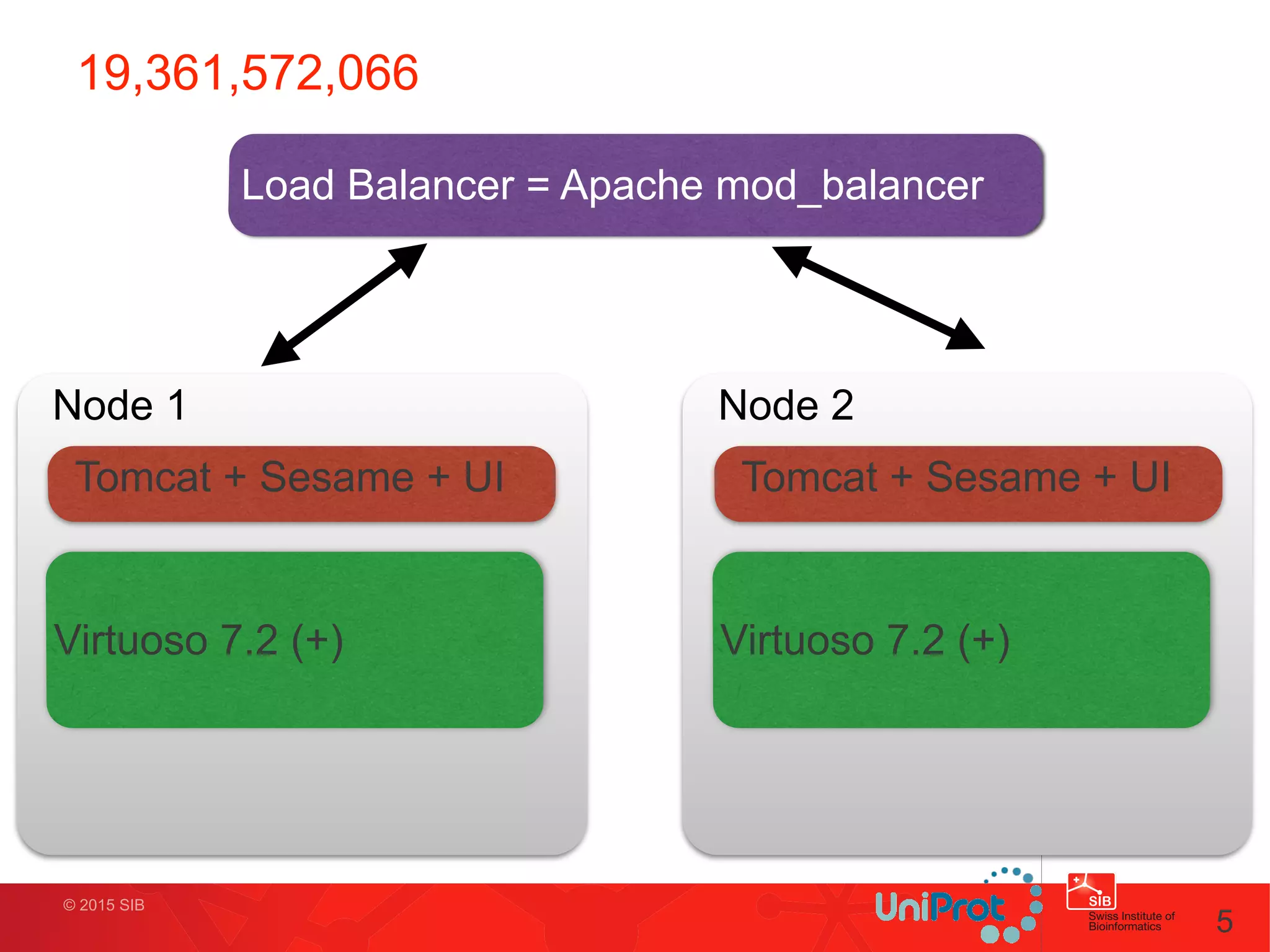


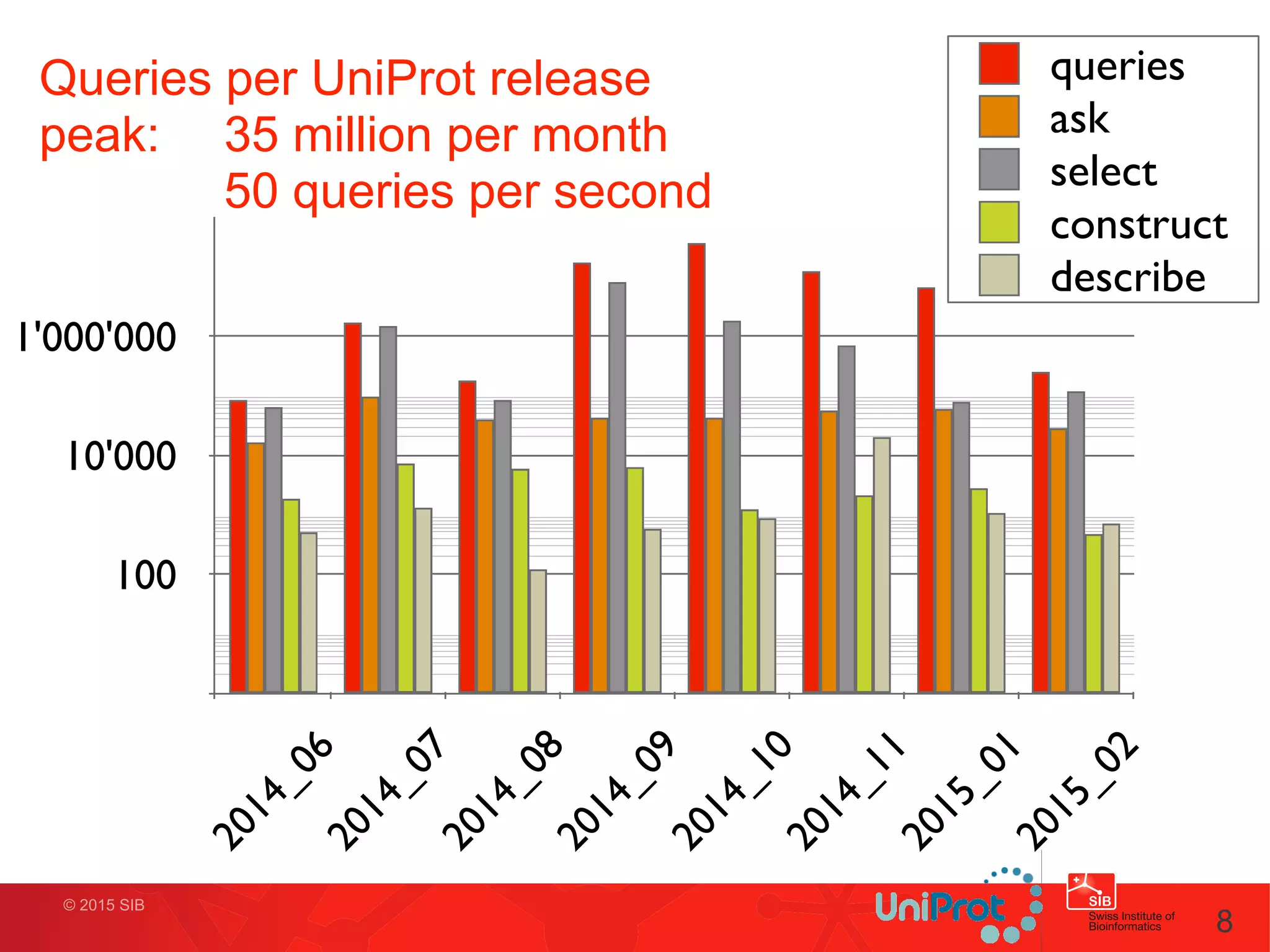










This document discusses the UniProt SPARQL endpoint, which contains 20 billion quads and serves hundreds of thousands of queries per month. It provides a public SPARQL endpoint to allow laboratories without their own databases to access and use existing life science data. It describes the architecture of the endpoint including load balancing and dedicated loading machines. It also discusses challenges such as unpredictable query loads, timeouts, and very complex queries involving counting all IRIs. Finally, it discusses potential optimizations and alternatives like key-value stores and template-based query compilation.








































































