Downloaded 106 times




![Taint and toleration
Taints
● Command
○ kubectl taint nodes [NODE_NAME] [KEY]=[VALUE]:[EFFECT]
○ kubectl taint nodes node1 key=value:NoSchedule
○ kubectl taint node -l myLabel=X dedicated=foo:PreferNoSchedule](https://image.slidesharecdn.com/kubernetes6-advancedscheduling-180606150252/85/Kubernetes-6-advanced-scheduling-4-320.jpg)

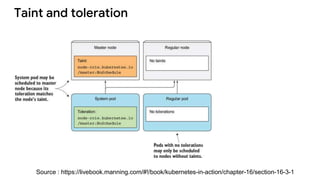




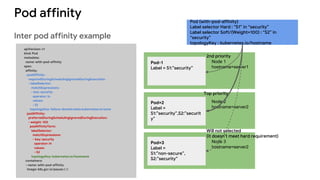
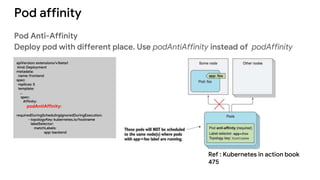
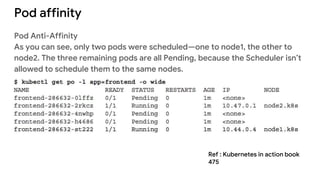

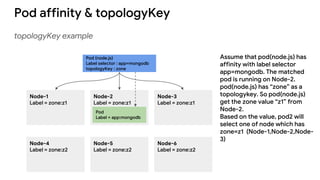
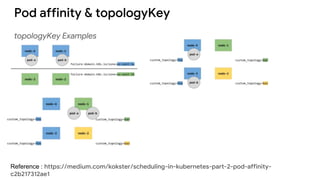


The document discusses advanced scheduling features in Kubernetes, specifically focusing on taints, tolerations, node affinity, and pod affinity. It explains how taints on nodes can be used to control pod deployment, while node affinity allows specifying preferred or required nodes based on labels. Additionally, it covers pod affinity and anti-affinity for deploying related pods together or separating them based on topology keys.














































































