Downloaded 11 times





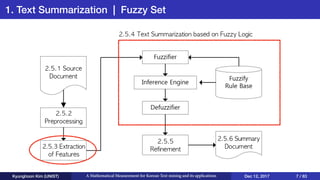
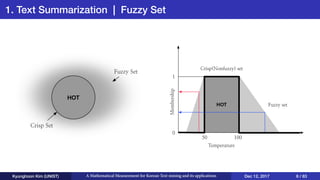

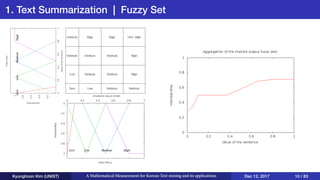





























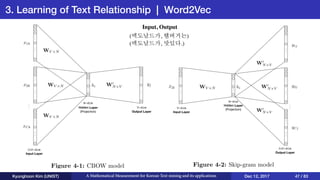
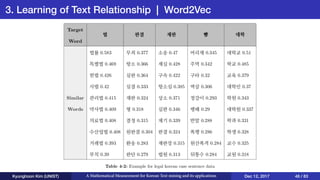



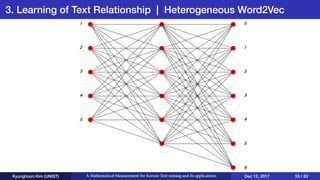


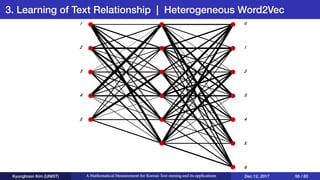























This document presents an overview of Kyunghoon Kim's research on mathematical measurements for Korean text mining and its applications. It discusses (1) text summarization using a fuzzy set approach to calculate sentence scores, (2) text clustering using syllable vectors for dimension reduction and calculating similarity, and (3) learning text relationships with heterogeneous Word2Vec to address limitations of the standard Word2Vec model. The research aims to develop methods specifically for the Korean language to overcome challenges with its structure and apply them to tasks like summarization, clustering and relationship analysis of Korean texts.

















































![[20160813, PyCon2016APAC] 뉴스를 재미있게 만드는 방법; 뉴스잼](https://cdn.slidesharecdn.com/ss_thumbnails/random-160813075211-thumbnail.jpg?width=640&height=640&fit=bounds)

























