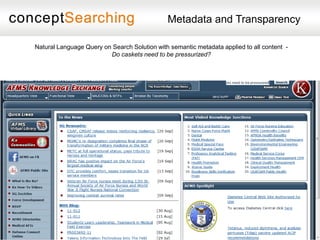
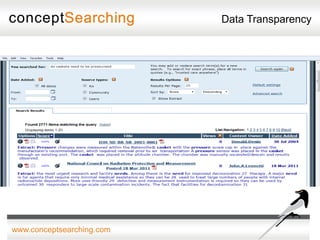
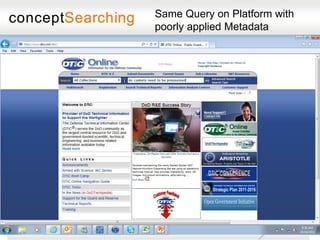
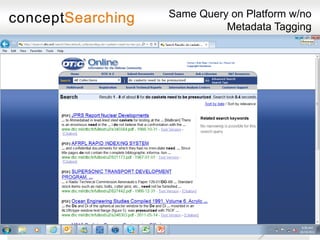
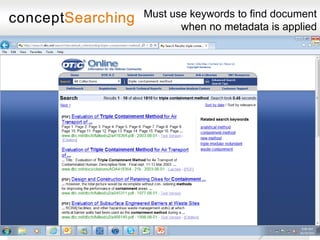
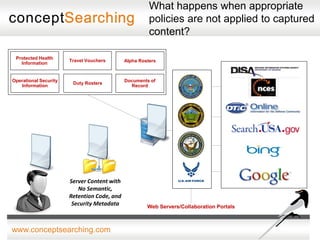
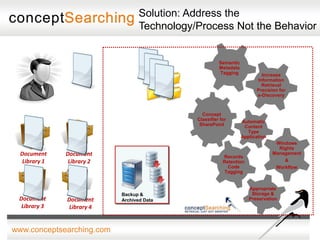
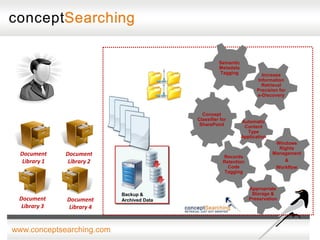
The document discusses approaches for enabling scalable enterprise search in a secure collaborative environment. It outlines four key building blocks: 1) Manage content by applying consistent classification and metadata; 2) Eliminate end users by addressing processes rather than user behavior; 3) Apply metadata-driven policies to protect data at risk; and 4) Identify and tag assets for storage and preservation using metadata-driven policies rather than relying on end users. The presentation provides examples of challenges organizations face with ineffective search and lack of information governance.