Downloaded 64 times


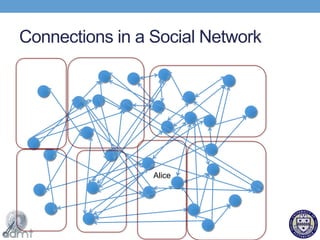










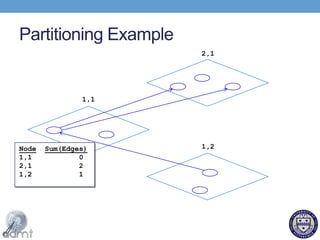








This document proposes using a key-key-value store model to efficiently process graph data in the cloud for social networks. It describes how social network data exhibits locality that can be leveraged. An on-line graph partitioning algorithm is presented that assigns related user data and profiles to the same machines to reduce the number of connections needed. The key-key-value store model extends traditional key-value stores to also store connections between users. Experimental results show the on-line partitioning algorithm performs comparably to static algorithms while adapting to dynamic changes.
































































