Download as PDF, PPTX






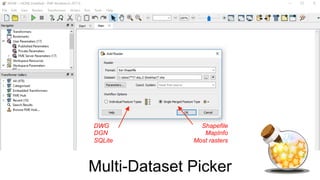
![Dataset
Wildcards
Extended glob syntax:
Symbol Matches
? Any single character
* Any sequence of zero or more
characters
[chars] Any single character in chars.
[a-d] Any character between a and
d inclusive
{a,b,...} Any of the sub-patterns a, b
/**/ 0 or more subdirectories](https://image.slidesharecdn.com/kenbraggbatchdataprocessing-170327072949/85/Ken-Bragg-Batch-data-processing-in-FME-11-320.jpg)






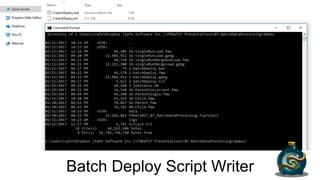
















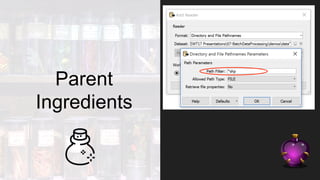

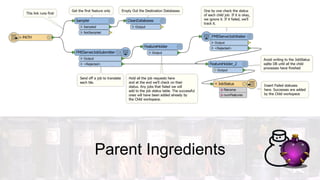
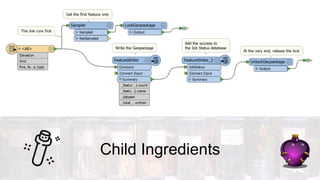








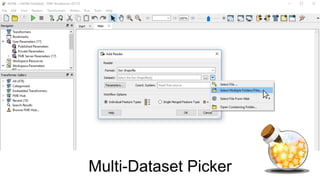
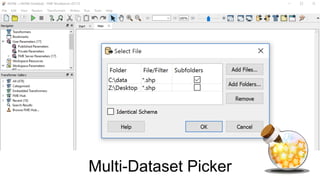
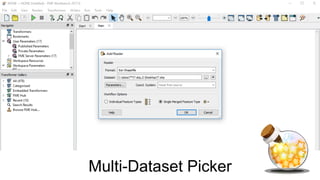
This document discusses four potions or methods for batch data processing large datasets: 1) Wildcards, 2) Batch Deploy, 3) Parent/Child Workspaces, and 4) Parent/Child Server Workspaces. Wildcards provide simple setup but have limitations. Batch Deploy scripts are also simple but have log and error handling issues. Parent/Child Workspaces separate transformations from workflows but can be slow. Parent/Child Server Workspaces leverage parallelism for speed but require data accessibility to server engines. In summary, each potion has tradeoffs; FME Server is recommended for robust automation.
















































































