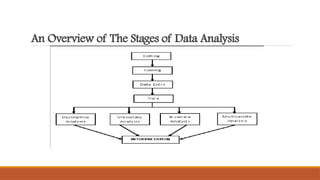
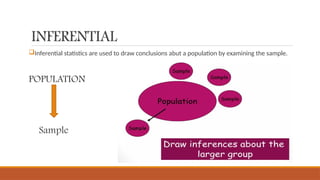
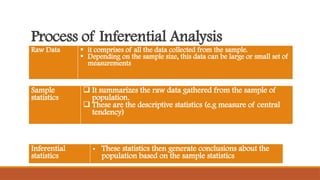
The document outlines the steps and processes involved in data analysis, including construction of statistical distributions and comparison of variables. It describes techniques for descriptive, associative, and inferential statistics, detailing procedures for obtaining descriptive statistics for both categorical and continuous variables using SPSS. Important statistical concepts such as probability, sampling distribution, and sampling error are also defined.