Downloaded 20 times


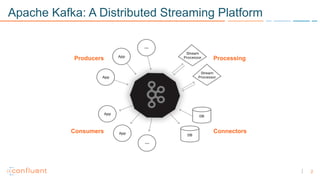

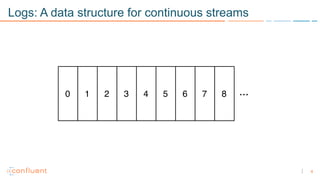

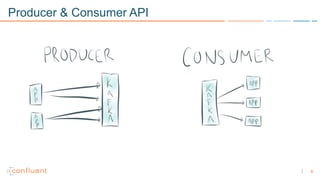
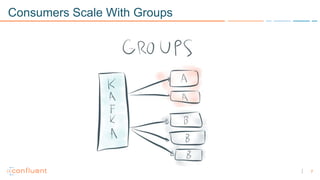
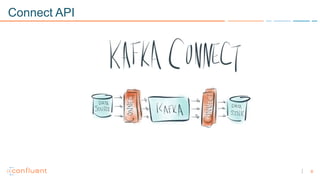

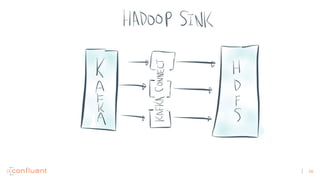
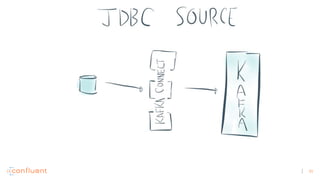
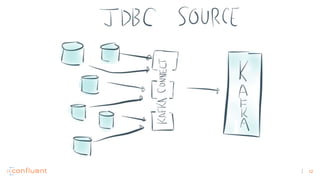
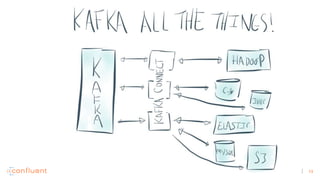








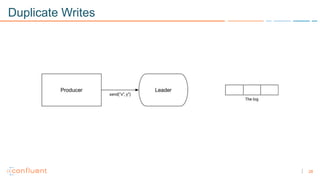
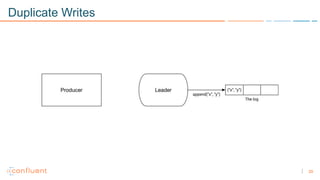
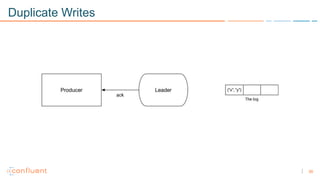
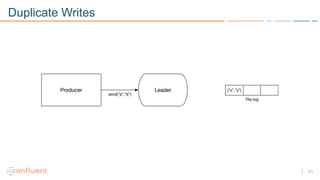
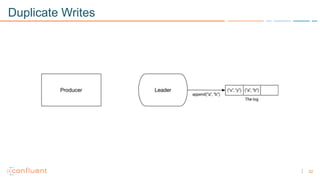
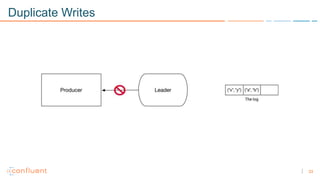
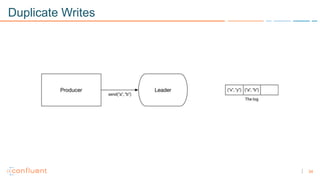
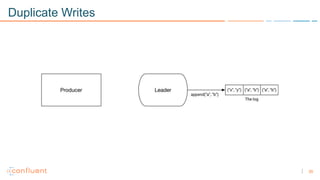
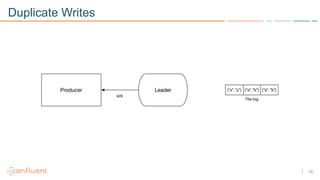

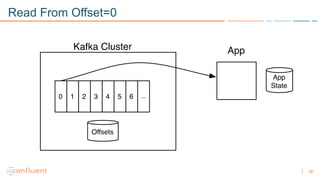
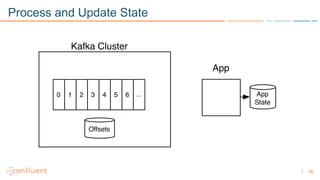
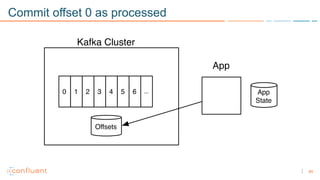
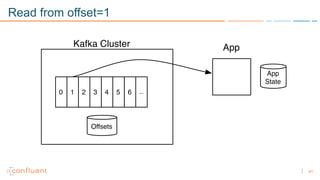
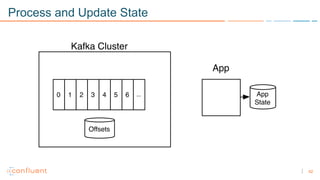
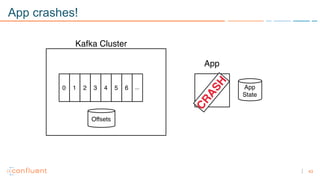
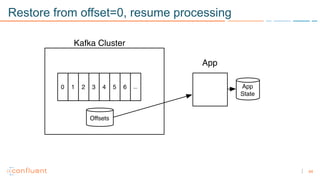
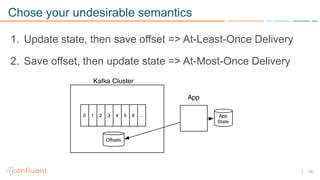






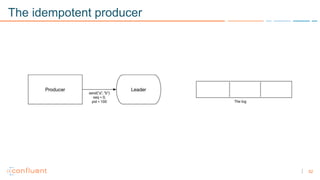
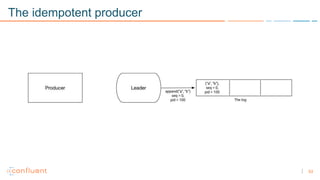
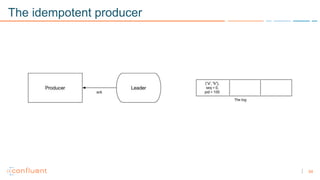
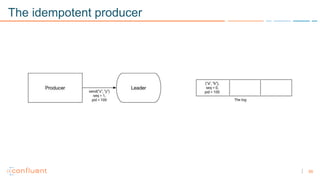
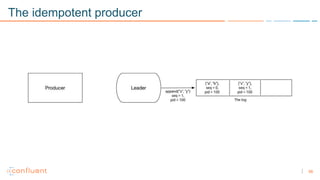
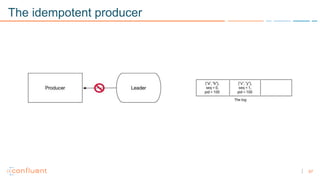
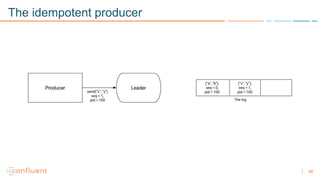
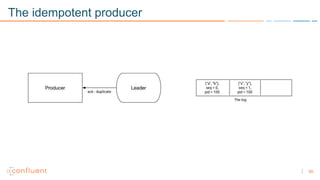


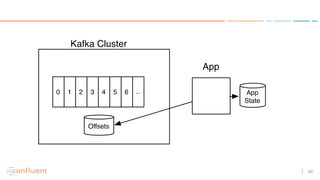
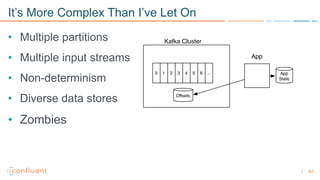


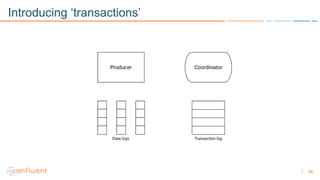
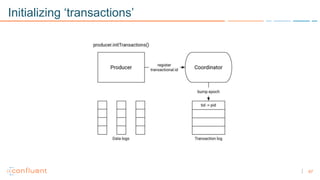
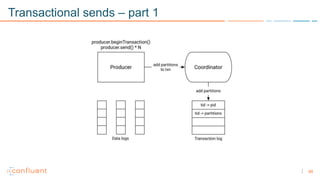
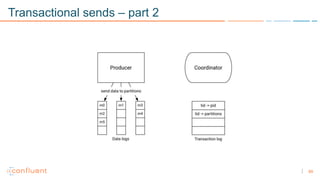
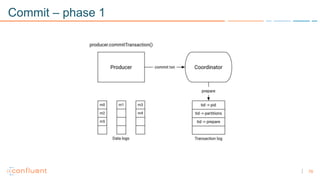
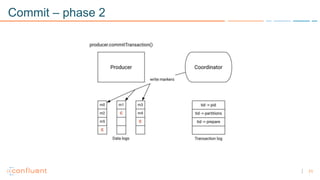
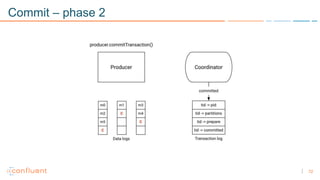
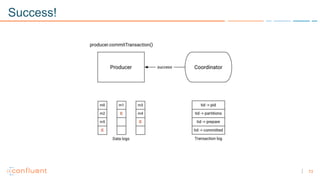
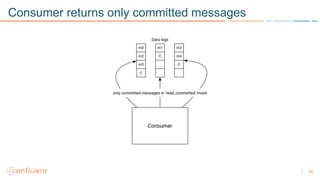


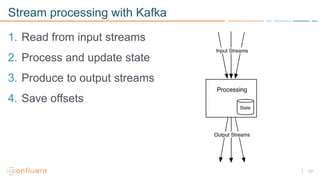
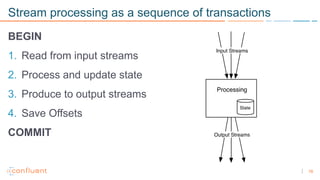









1) Apache Kafka is a distributed streaming platform that allows for continuous stream processing. It provides APIs for producers and consumers to read and write streams, as well as connectors and stream processing capabilities. 2) Kafka faces two main problems: duplicate writes and ensuring exactly-once processing. It solves duplicate writes through an idempotent producer that assigns unique IDs to each message. 3) Kafka solves exactly-once processing through transactions. Producers can initiate transactions to send multiple records atomically, and consumers only see committed transactions, ensuring exactly-once semantics for stream processing applications.































































