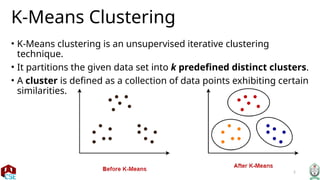
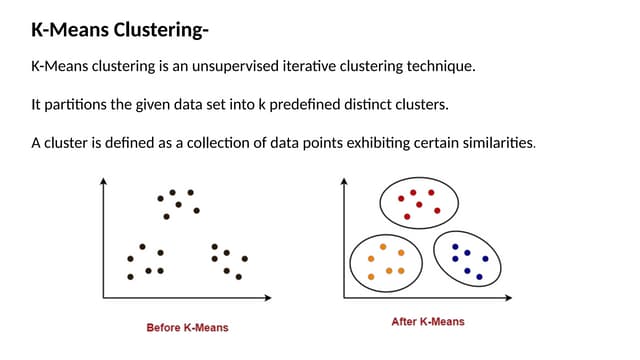
The document provides a comprehensive overview of the k-means clustering algorithm, an unsupervised technique that partitions data into k distinct clusters based on similarity. It details the algorithm's steps, advantages, and disadvantages, including the requirement to specify the number of clusters in advance. The document also includes practical problems and solutions illustrating the application of the algorithm on specific datasets.
























![28
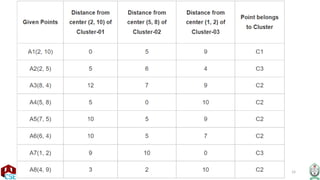
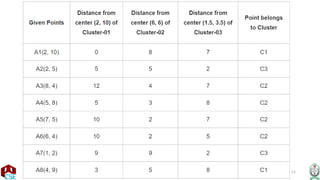
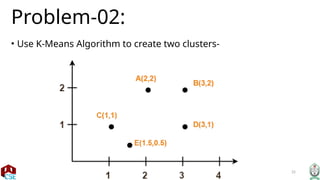
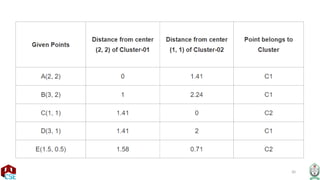
• Calculating Distance Between A(2, 2) and C1(2, 2)-
• Ρ(A, C1)
= sqrt [ (x2 – x1)^2 + (y2 – y1)^2 ]
= sqrt [ (2 – 2)^2 + (2 – 2)^2 ]
= sqrt [ 0 + 0 ]
= 0
• Calculating Distance Between A(2, 2) and C2(1, 1)-
• Ρ(A, C2)
= sqrt [ (x2 – x1)^2 + (y2 – y1)^2 ]
= sqrt [ (1 – 2)^2 + (1 – 2)^2 ]
= sqrt [ 1 + 1 ]
= sqrt [ 2 ]
= 1.41
• In the similar manner, we calculate the distance of other points from each of the
center of the two clusters.](https://image.slidesharecdn.com/k-meansclustering-240825175053-2eb9a6c6/85/k-means-clustering-machine-learning-pptx-28-320.jpg)








































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)








![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
