Download as PDF, PPTX







![8
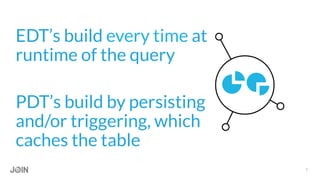
“I love ephemeral derived tables because they
feel light-weight and focused, but they make
the most sense when you're doing something
small and quick and/or if what you're doing is
sensitive to frequent ETL. If you don't mind the
[computation] cost and redoing the
computation each time, then I'd say don't
persist.”
Maxie Corbin
Looker Data Analyst, Customer Support](https://image.slidesharecdn.com/join2017deepdivetouseornotusepdts-170918191600/85/Join-2017_Deep-Dive_To-Use-or-Not-Use-PDT-s-8-320.jpg)


![How much
usage per
customer?
How has our
retention rate
changed over
the past 6
years?
None of the
queries
appear to be
working?
Select
margin
of error?
[SQL
ERROR]:
Table lock?
Table lock.](https://image.slidesharecdn.com/join2017deepdivetouseornotusepdts-170918191600/85/Join-2017_Deep-Dive_To-Use-or-Not-Use-PDT-s-11-320.jpg)

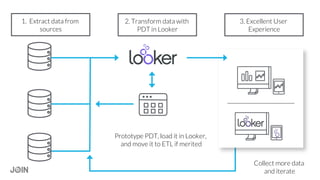
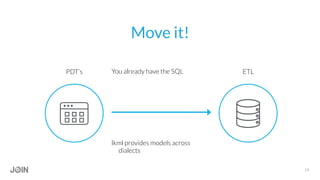
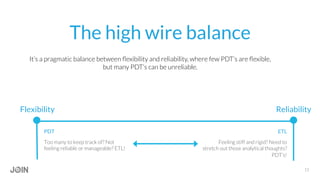
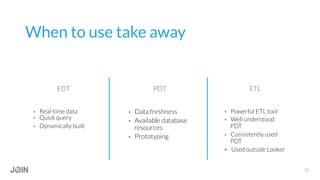


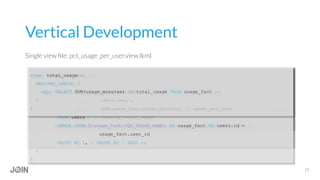



Jonathon Miller-Girvetz discusses best practices for using persistent derived tables (PDTs) in Looker. He covers when to use ephemeral derived tables versus PDTs, as well as when to move PDT logic to an ETL process. Some key points include: use PDTs for historical summaries and aggregations, but EDTs for quick or dynamic queries; consider data freshness, computational resources, and use outside of Looker when deciding between PDTs and ETL; and follow conventions like consistent naming when developing PDTs.