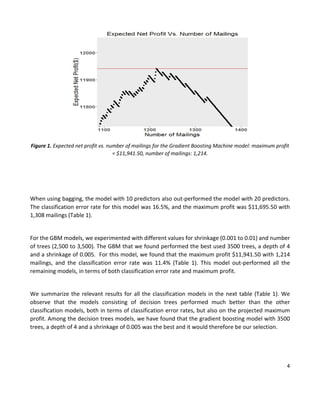
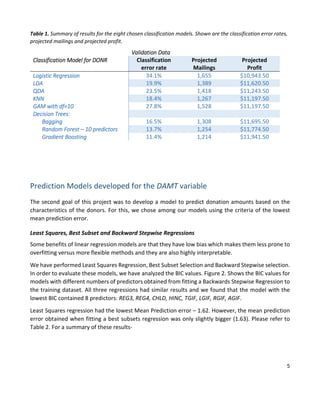
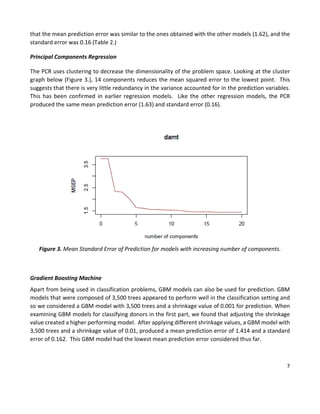
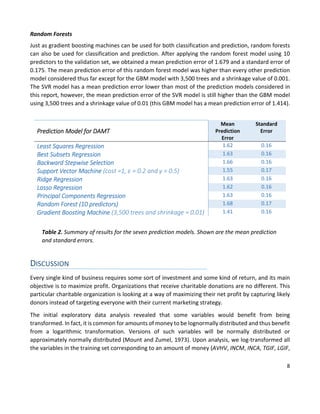
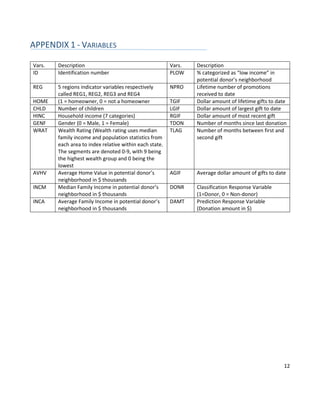
This document summarizes a statistical analysis project using classification and prediction models to analyze charitable donation data. The goals were to 1) build a classification model to identify likely donors to maximize profit, and 2) develop a prediction model for donation amounts based on donor characteristics. Several models were tested on training, validation, and test datasets. The best classification model was a gradient boosting machine with an error rate of 11.4% and projected profit of $11,941.50. The best prediction model was a gradient boosting machine with a mean prediction error of 1.414.






![10
REFERENCES
Gunn SR (1998). Support Vector Machines for Classification and Regression. University of
Southampton.
James G, Witten D, Hastie T, Tibshirani R. (2015). An Introduction to Statistical Learning with
Applications in R. Springer New York Heidelberg Dordrecht London.
Mount J and Zumel N (2014). Practical Data Science With R. Manning Publication Co.
Natekin A and Knoll A (2013). Gradient boosting machines, a tutorial. Frontier in Neurorobotics, Volume
7, Article 21. (Retrieved from: http://doi.org/10.3389/fnbot.2013.00021).
R Core Team. (2015). R: A Language and Environment for Statistical Computing. R Foundation for
Statistical Computing, Vienna, Austria. (Retrieved from: http://www.R-project.org/)
Course notes for STAT 897D – Applied Data Mining and Statistical Learning. [Online]. [Accessed January
- April 2016]. Available from: < https://onlinecourses.science.psu.edu/stat857/>](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-11-320.jpg)



![library(ggplot2)
library(tree) #Use tree package to create classification tree
library(randomForest)
library(nnet)
library(gbm)
library(caret)
library(ggplot2)
library(pbkrtest)
library(glmnet)
library(lme4)
library(Matrix)
library(gam)
library(MASS)
library(leaps)
library(glmnet)
#charity <- read.csv("~/Penn_State/STAT897D/Projects/Final_Project/charity.csv")
#charity <- read.csv("charity.csv")
charity <- read.csv("~/Penn_State/STAT897D/Projects/Final_Project/charity.csv")
#charity <- read.csv("~/Documents/teaching/psu/charity.csv")
#charity <- read.csv("charity.csv")
#A subset of the data without the donr and damt variables
charitySub <- subset(charity,select = -c(donr,damt))
#Check for missing values in the data excluding the donr and damt variables
sum(is.na(charitySub)) #There are no missing data among the other variables
# predictor transformations
charity.t <- charity
#A log transformed version of "avhv" is approximately normally distributed
# versus the untransformed version of "avhv"
charity.t$avhv <- log(charity.t$avhv)
charity.t$incm <- log(charity.t$incm)
charity.t$inca <- log(charity.t$inca)
charity.t$plow <- charity.t$plow^(1/3)
charity.t$tgif <- log(charity.t$tgif)
charity.t$lgif <- log(charity.t$lgif)
charity.t$rgif <- log(charity.t$rgif)
charity.t$tlag <- log(charity.t$tlag)
charity.t$agif <- log(charity.t$agif)
# add further transformations if desired
# for example, some statistical methods can struggle when predictors are highly skewed
# set up data for analysis
#Training Set Section
data.train <- charity.t[charity$part=="train",]
x.train <- data.train[,2:21]
c.train <- data.train[,22] # donr
n.train.c <- length(c.train) # 3984
y.train <- data.train[c.train==1,23] # damt for observations with donr=1
n.train.y <- length(y.train) # 1995
#Validation Set Section
data.valid <- charity.t[charity$part=="valid",]
x.valid <- data.valid[,2:21]
c.valid <- data.valid[,22] # donr
n.valid.c <- length(c.valid) # 2018
y.valid <- data.valid[c.valid==1,23] # damt for observations with donr=1
n.valid.y <- length(y.valid) # 999
#Test Set Section
data.test <- charity.t[charity$part=="test",]
n.test <- dim(data.test)[1] # 2007
x.test <- data.test[,2:21]
#Training Set Mean and Standard Deviation
x.train.mean <- apply(x.train, 2, mean)
x.train.sd <- apply(x.train, 2, sd)
#Standardizing the Variables in the Training Set
x.train.std <- t((t(x.train)-x.train.mean)/x.train.sd) # standardize to have zero mean and unit sd](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-16-320.jpg)
![apply(x.train.std, 2, mean) # check zero mean
apply(x.train.std, 2, sd) # check unit sd
#Data Frame for the "donr" variable in the Training Set
data.train.std.c <- data.frame(x.train.std, donr=c.train) # to classify donr
data.train.std.y <- data.frame(x.train.std[c.train==1,], damt=y.train) # to predict damt when donr=1
#Standardizing the Variables in the Validation Set
x.valid.std <- t((t(x.valid)-x.train.mean)/x.train.sd) # standardize using training mean and sd
data.valid.std.c <- data.frame(x.valid.std, donr=c.valid) # to classify donr
#Data Frame for the "donr" variable in the Validation Set
data.valid.std.y <- data.frame(x.valid.std[c.valid==1,], damt=y.valid) # to predict damt when donr=1
#Standardizing the Variables in the Test Set
x.test.std <- t((t(x.test)-x.train.mean)/x.train.sd) # standardize using training mean and sd
data.test.std <- data.frame(x.test.std)
# logistic Regression Model 3 is best
library(MASS)
boxplot(data.train)
model.logistic <- glm(donr ~ reg1 + +reg2 + reg3 + reg4 + home + chld + hinc + I(hinc^2)+genf + wrat +
avhv + incm + inca + plow + npro + tgif + lgif + rgif + tdon + tlag + agif, data.train,
family=binomial("logit"))
summary(model.logistic)
model.logistic1 <- glm(donr ~ reg1 + +reg2 + reg3 + reg4 + home + chld + hinc + I(hinc^2)+genf + wrat +
avhv + incm + inca + npro + tgif + lgif + rgif + tdon + tlag + agif, data.train,
family=binomial("logit"))
summary(model.logistic1)
model.logistic2 <- glm(donr ~ reg1 + +reg2 + reg3 + home + chld + hinc + I(hinc^2)+genf + wrat +
avhv + incm + inca + npro + tgif + lgif + rgif + tdon + tlag + agif, data.train,
family=binomial("logit"))
summary(model.logistic2)
model.logistic3 <- glm(donr ~ reg1 + +reg2 + reg3 + home + chld + hinc + I(hinc^2)+genf + wrat +
rgif + incm + inca + npro + tgif + lgif + tdon + tlag + agif, data.train,
family=binomial("logit"))
summary(model.logistic3)
model.logistic4 <- glm(donr ~ reg1 + +reg2 + home + chld + hinc + I(hinc^2)+genf + wrat +
rgif + incm + inca + npro + tgif + lgif + tdon + tlag + agif, data.train,
family=binomial("logit"))
summary(model.logistic4)
model.logistic5 <- glm(donr ~ reg1 + +reg2 + home + chld + hinc + I(hinc^2)+genf + wrat +
rgif + incm + inca + npro + tgif + tdon + tlag + agif, data.train, family=binomial("logit"))
summary(model.logistic5)
model.logistic6 <- glm(donr ~ reg1 + +reg2 + home + chld + hinc + I(hinc^2)+genf + wrat +
rgif + incm + inca + tgif + tdon + tlag + agif, data.train, family=binomial("logit"))
summary(model.logistic6)
model.logistic7 <- glm(donr ~ reg1 + +reg2 + home + chld + hinc + I(hinc^2)+genf + wrat +
rgif + incm + inca + tgif + tdon + tlag, data.train, family=binomial("logit"))
summary(model.logistic7)
post.valid.logistic <- predict(model.logistic,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic1 <- predict(model.logistic1,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic2 <- predict(model.logistic2,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic3 <- predict(model.logistic3,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic4 <- predict(model.logistic4,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic5 <- predict(model.logistic5,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic6 <- predict(model.logistic6,data.valid.std.c,type="response") # n.valid.c post probs
post.valid.logistic7 <- predict(model.logistic7,data.valid.std.c,type="response") # n.valid.c post probs
# calculate ordered profit function using average donation = $14.50 and mailing cost = $2
profit.logistic <- cumsum(14.5*c.valid[order(post.valid.logistic, decreasing=T)]-2)
plot(profit.logistic) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic)) # report number of mailings and maximum profit
cutoff.logistic <- sort(post.valid.logistic, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic <- ifelse(post.valid.logistic>cutoff.logistic, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic, c.valid) # classification table
1-mean(chat.valid.logistic==c.valid)
# True Neg 345 True Pos 983 Miss 34.19% Profit 10937.5
profit.logistic1 <- cumsum(14.5*c.valid[order(post.valid.logistic1, decreasing=T)]-2)
plot(profit.logistic1) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic1) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic1)) # report number of mailings and maximum profit
cutoff.logistic1 <- sort(post.valid.logistic1, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic1 <- ifelse(post.valid.logistic1>cutoff.logistic1, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic1, c.valid) # classification table
1-mean(chat.valid.logistic1==c.valid)](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-17-320.jpg)
![# True Neg 345 True Pos 983 Miss 34.19% Profit 10939.5
profit.logistic2 <- cumsum(14.5*c.valid[order(post.valid.logistic2, decreasing=T)]-2)
plot(profit.logistic2) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic2) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic2)) # report number of mailings and maximum profit
cutoff.logistic2 <- sort(post.valid.logistic2, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic2 <- ifelse(post.valid.logistic2>cutoff.logistic2, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic2, c.valid) # classification table
1-mean(chat.valid.logistic2==c.valid)
# True Neg 345 True Pos 983 Miss 34.19% Profit 10939.5
profit.logistic3 <- cumsum(14.5*c.valid[order(post.valid.logistic3, decreasing=T)]-2)
plot(profit.logistic3) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic3) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic3)) # report number of mailings and maximum profit
cutoff.logistic3 <- sort(post.valid.logistic3, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic3 <- ifelse(post.valid.logistic3>cutoff.logistic3, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic3, c.valid) # classification table
1-mean(chat.valid.logistic3==c.valid)
# True Neg 347 True Pos 983 Miss 34.09% Profit 10943.5
profit.logistic4 <- cumsum(14.5*c.valid[order(post.valid.logistic4, decreasing=T)]-2)
plot(profit.logistic4) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic4) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic4)) # report number of mailings and maximum profit
cutoff.logistic4 <- sort(post.valid.logistic4, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic4 <- ifelse(post.valid.logistic4>cutoff.logistic4, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic4, c.valid) # classification table
1-mean(chat.valid.logistic4==c.valid)
# True Neg 346 True Pos 983 Miss 34.14% Profit 10941.5
profit.logistic5 <- cumsum(14.5*c.valid[order(post.valid.logistic5, decreasing=T)]-2)
plot(profit.logistic5) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic5) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic5)) # report number of mailings and maximum profit
cutoff.logistic5 <- sort(post.valid.logistic5, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic5 <- ifelse(post.valid.logistic5>cutoff.logistic5, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic5, c.valid) # classification table
1-mean(chat.valid.logistic5==c.valid)
# True Neg 345 True Pos 982 Miss 34.24% Profit 10927
profit.logistic6 <- cumsum(14.5*c.valid[order(post.valid.logistic6, decreasing=T)]-2)
plot(profit.logistic6) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic6) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic6)) # report number of mailings and maximum profit
cutoff.logistic6 <- sort(post.valid.logistic6, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic6 <- ifelse(post.valid.logistic6>cutoff.logistic6, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic6, c.valid) # classification table
1-mean(chat.valid.logistic6==c.valid)
# True Neg 323 True Pos 986 35.13%
profit.logistic7 <- cumsum(14.5*c.valid[order(post.valid.logistic7, decreasing=T)]-2)
plot(profit.logistic7) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.logistic7) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.logistic7)) # report number of mailings and maximum profit
cutoff.logistic7 <- sort(post.valid.logistic7, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.logistic7 <- ifelse(post.valid.logistic7>cutoff.logistic7, 1, 0) # mail to everyone above the cutoff
table(chat.valid.logistic7, c.valid) # classification table
1-mean(chat.valid.logistic7==c.valid)
# True Neg 324, True Pos 986 35.08% miss
# linear discriminant analysis
library(MASS)
model.lda1 <- lda(donr ~ reg1 +reg2 + reg3 + reg4 + home + chld + hinc + I(hinc^2) + genf + wrat +
avhv + incm + inca + plow + npro + tgif + lgif + rgif + tdon + tlag + agif,
data.train.std.c) # include additional terms on the fly using I()](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-18-320.jpg)
![# Note: strictly speaking, LDA should not be used with qualitative predictors,
# but in practice it often is if the goal is simply to find a good predictive model
post.valid.lda1 <- predict(model.lda1, data.valid.std.c)$posterior[,2] # n.valid.c post probs
# calculate ordered profit function using average donation = $14.50 and mailing cost = $2
profit.lda1 <- cumsum(14.5*c.valid[order(post.valid.lda1, decreasing=T)]-2)
plot(profit.lda1) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.lda1) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.lda1)) # report number of mailings and maximum profit
# 1389.0 11620.5
cutoff.lda1 <- sort(post.valid.lda1, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.lda1 <- ifelse(post.valid.lda1>cutoff.lda1, 1, 0) # mail to everyone above the cutoff
table(chat.valid.lda1, c.valid) # classification table
# c.valid
#chat.valid.lda1 0 1
# 0 623 6
# 1 396 993
1-mean(chat.valid.lda1==c.valid) #Error rate
# Quadratic Discriminant Analysis
model.qda <- qda(donr ~ reg1 +reg2 + reg3 + reg4 + home + chld + hinc + I(hinc^2) + genf + wrat +
avhv + incm + inca + plow + npro + tgif + lgif + rgif + tdon + tlag + agif,
data.train.std.c) # include additional terms on the fly using I()
post.valid.qda <- predict(model.qda, data.valid.std.c)$posterior[,2] # n.valid.c post probs
# calculate ordered profit function using average donation = $14.50 and mailing cost = $2
profit.qda <- cumsum(14.5*c.valid[order(post.valid.qda, decreasing=T)]-2)
plot(profit.qda) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.qda) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.qda)) # report number of mailings and maximum profit
# 1418.0 11243.5
cutoff.qda <- sort(post.valid.qda, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.qda <- ifelse(post.valid.qda>cutoff.qda, 1, 0) # mail to everyone above the cutoff
table(chat.valid.qda, c.valid) # classification table
# c.valid
#chat.valid.qda 0 1
# 0 572 28
# 1 447 971
1-mean(chat.valid.qda==c.valid) #Error rate
#K Nearest Neighbors
library(class)
set.seed(1)
post.valid.knn=knn(x.train.std,x.valid.std,c.train,k=13)
# calculate ordered profit function using average donation = $14.50 and mailing cost = $2
profit.knn <- cumsum(14.5*c.valid[order(post.valid.knn, decreasing=T)]-2)
plot(profit.knn) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.knn) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.knn)) # report number of mailings and maximum profit
# 1267.0 11197.5
table(post.valid.knn, c.valid) # classification table
# c.valid
#chat.valid.knn 0 1
# 0 699 52
# 1 320 947
# check n.mail.valid = 320+947 = 1267
# check profit = 14.5*947-2*1267 = 11197.5
1-mean(post.valid.knn==c.valid) #Error rate
#Mailings and Profit values for different values of k
# k=3 1231 10617](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-19-320.jpg)
![# k=8 1248 11018
# k=10 1261.0 11151.5
# k=13 1267.0 11197.5
# k=14 1268.0 11137.5
#GAM
library(gam)
model.gam <- gam(donr ~ reg1 + reg2 + reg3 + reg4 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ genf + s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(lgif,df=5) + s(rgif,df=5) + s(tdon,df=5) + s(tlag,df=5) + s(agif,df=5), data.train,
family=binomial)
summary(model.gam)
model.gam <- gam(donr ~ reg1 + reg2 + reg3 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ genf + s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(lgif,df=5) + s(rgif,df=5) + s(tdon,df=5) + s(tlag,df=5) + s(agif,df=5), data.train,
family=binomial)
summary(model.gam)
model.gam <- gam(donr ~ reg1 + reg2 + reg3 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(lgif,df=5) + s(rgif,df=5) + s(tdon,df=5) + s(tlag,df=5) + s(agif,df=5), data.train,
family=binomial)
summary(model.gam)
model.gam <- gam(donr ~ reg1 + reg2 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(lgif,df=5) + s(rgif,df=5) + s(tdon,df=5) + s(tlag,df=5) + s(agif,df=5), data.train,
family=binomial)
summary(model.gam)
model.gam <- gam(donr ~ reg1 + reg2 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(lgif,df=5) + s(tdon,df=5) + s(tlag,df=5) + s(agif,df=5), data.train, family=binomial)
summary(model.gam)
model.gam <- gam(donr ~ reg1 + reg2 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(lgif,df=5) + s(tdon,df=5) + s(tlag,df=5), data.train, family=binomial)
summary(model.gam)
model.gam <- gam(donr ~ reg1 + reg2 + home + s(chld,df=5)+ s(hinc,df=5) +s(I(hinc^2), df=5)
+ s(wrat,df=5) + s(avhv,df=5) + s(inca,df=5)+ s(plow,df=5) + s(npro,df=5) + s(tgif,df=5)
+ s(tdon,df=5) + s(tlag,df=5), data.train, family=binomial)
summary(model.gam)
post.valid.gam <- predict(model.gam,data.valid.std.c,type="response") # n.valid.c post probs
profit.gam <- cumsum(14.5*c.valid[order(post.valid.gam, decreasing=T)]-2)
plot(profit.gam) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.gam) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.gam)) # report number of mailings and maximum profit
cutoff.gam <- sort(post.valid.gam, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.gam <- ifelse(post.valid.gam>cutoff.gam, 1, 0) # mail to everyone above the cutoff
table(chat.valid.gam, c.valid) # classification table
1-mean(chat.valid.gam==c.valid)
# error rate 21.6% Profit 10461.5 mailings 2012
#GAM df=10
library(gam)
model.gam2 <- gam(donr ~ reg1 + reg2 + home + s(chld,df=10) + s(hinc,df=10) +s(I(hinc^2), df=10)
+ s(wrat,df=10) + s(avhv,df=10) + s(inca,df=10)+ s(plow,df=10) + s(npro,df=10) + s(tgif,df=10)
+ s(tdon,df=10) + s(tlag,df=10), data.train, family=binomial)
summary(model.gam2)
post.valid.gam2 <- predict(model.gam2,data.valid.std.c,type="response") # n.valid.c post probs
profit.gam2 <- cumsum(14.5*c.valid[order(post.valid.gam2, decreasing=T)]-2)
plot(profit.gam2) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.gam2) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.gam2)) # report number of mailings and maximum profit
cutoff.gam2 <- sort(post.valid.gam2, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.gam2 <- ifelse(post.valid.gam2>cutoff.gam2, 1, 0) # mail to everyone above the cutoff
table(chat.valid.gam2, c.valid) # classification table
1-mean(chat.valid.gam2==c.valid)
# 27.8% Profit 11197.5 Mailing 1528
#GAM df=15
library(gam)](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-20-320.jpg)
![model.gam <- gam(donr ~ reg1 + reg2 + home + s(chld,df=15)+ s(hinc,df=15)+s(I(hinc^2),df=10)
+ s(wrat,df=15) + s(avhv,df=15) + s(inca,df=15)+ s(plow,df=15) + s(npro,df=15) + s(tgif,df=15)
+ s(tdon,df=15) + s(tlag,df=15), data.train, family=binomial)
summary(model.gam)
post.valid.gam <- predict(model.gam,data.valid.std.c,type="response") # n.valid.c post probs
profit.gam <- cumsum(14.5*c.valid[order(post.valid.gam, decreasing=T)]-2)
plot(profit.gam) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.gam) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.gam)) # report number of mailings and maximum profit
cutoff.gam <- sort(post.valid.gam, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.gam <- ifelse(post.valid.gam>cutoff.gam, 1, 0) # mail to everyone above the cutoff
table(chat.valid.gam, c.valid) # classification table
1-mean(chat.valid.gam==c.valid)
# errror rate 41.1 Profit 10764.5 Mailings 1817
#GAM df=15
library(gam)
model.gam <- gam(donr ~ reg1 + reg2 + reg3 + reg4 + home + s(chld,df=20)+ s(hinc,df=20)
+ genf + s(wrat,df=20) + s(avhv,df=20) + s(inca,df=20)+ s(plow,df=20) + s(npro,df=20) +
s(tgif,df=20)
+ s(lgif,df=20) + s(rgif,df=20) + s(tdon,df=20) + s(tlag,df=20) + s(agif,df=20), data.train,
family=binomial)
summary(model.gam)
post.valid.gam <- predict(model.gam,data.valid.std.c,type="response") # n.valid.c post probs
profit.gam <- cumsum(14.5*c.valid[order(post.valid.gam, decreasing=T)]-2)
plot(profit.gam) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.gam) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.gam)) # report number of mailings and maximum profit
cutoff.gam <- sort(post.valid.gam, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.gam <- ifelse(post.valid.gam>cutoff.gam, 1, 0) # mail to everyone above the cutoff
table(chat.valid.gam, c.valid) # classification table
1-mean(chat.valid.gam==c.valid)
#error rate 48.6% Profit 10517 Mailing 1977
#############################
#Random Forests for Classification
#############################
library(randomForest)
#Possible Predictors for the random forest
data.train.std.c.predictors <- data.train.std.c[,names(data.train.std.c)!="donr"]
#This code evaluates the performance of random forests using different numbers
#of predictors by means of 10 fold cross-validation
rf.cv.results <- rfcv(data.train.std.c.predictors, as.factor(data.train.std.c$donr), cv.fold=10)
with(rf.cv.results,plot(n.var,error.cv,main = "Random Forest CV Error Vs. Number of Predictors", xlab = "Number of
Predictors",
ylab = "CV Error",
type="b",lwd=5,col="red"))
#Table of number of the number of predictors versus errors in random forest
random.forest.error <- rbind(rf.cv.results$n.var,rf.cv.results$error.cv)
rownames(random.forest.error) <- c("Number of Predictors","Random Forest Error")
random.forest.error
#The minimum cross-validated error for a random forest is the random forest
#with 20 predictors. The CV error for a random forest using 20 predictors is 0.11
# and the CV error for a random forest using 10 predictors is 0.12. Since the](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-21-320.jpg)
![# CV error is not that much higher for the random forest with 10 predictors
# than the random forest using 20 predictors, we will first use a random forest
# using 10 predictors.
################################
#Random Forest Using 10 Predictors
################################
require(randomForest)
set.seed(1) #Seed for the random forest that uses 10 predictors
rf.charity.10 <- randomForest(x = data.train.std.c.predictors
,y=as.factor(data.train.std.c$donr),
mtry=10)
rf.charity.10.posterior.valid <- predict(rf.charity.10, data.valid.std.c, type="prob")[,2] # n.valid post probs
profit.charity.RF.10 <- cumsum(14.5*c.valid[order(rf.charity.10.posterior.valid, decreasing=T)]-2)
n.mail.valid <- which.max(profit.charity.RF.10 ) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.charity.RF.10)) # report number of mailings and maximum profit
cutoff.charity.10 <- sort(rf.charity.10.posterior.valid, decreasing=T)[n.mail.valid+1] # set cutoff based on
n.mail.valid
chat.valid.charity.10 <- ifelse(rf.charity.10.posterior.valid>cutoff.charity.10, 1, 0) # mail to everyone above the
cutoff
table(chat.valid.charity.10, c.valid) # classification table
#Classification Matrix
#0 1
#0 760 18
#1 259 981
################################
#Bag - (Random Forest using all 20 possible predictors)
################################
require(randomForest)
set.seed(1)
bag.charity <- randomForest(x = data.train.std.c.predictors
,y=as.factor(data.train.std.c$donr),
mtry=20)
bag.charity.posterior.valid <- predict(bag.charity, data.valid.std.c, type="prob")[,2] # n.valid post probs
profit.charity.bag <- cumsum(14.5*c.valid[order(bag.charity.posterior.valid, decreasing=T)]-2)
n.mail.valid <- which.max(profit.charity.bag ) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.charity.bag)) # report number of mailings and maximum profit
#1308 mailings and Maximum Profit $11,695.50
cutoff.bag <- sort(bag.charity.posterior.valid, decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.bag <- ifelse(bag.charity.posterior.valid >cutoff.bag, 1, 0) # mail to everyone above the cutoff
table(chat.valid.bag, c.valid) # classification table
# Classification Matrix
#0 1
#0 699 13
#1 320 986
#Comparision of the random forest that uses all 20 predictors (the bag)
#Versus the random forest that uses 10 predictors.
# The maximum profit produced by the random forest using 10 predictors
# is $11,744.50 while the maximum profit produced by the random forest
# using all 20 predictors is $11,695.50. The number of mailings required
# for the maximum profit produced by the random forest using 10 predictors
# is 1,240 mailings while the number of mailings required for the maximum profit
# produced by the bag model (random forest using all 20 predictors)
# is 1,308 mailings.
#Gradient Boosting Machine (GBM) - Section](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-22-320.jpg)
![library(gbm)
set.seed(1)
#GBM with 2,500 trees
boost.charity <- gbm(donr~.,
data= data.train.std.c,
distribution = "bernoulli",n.trees=2500,interaction.depth=5)
yhat.boost.charity <- predict(boost.charity,newdata=data.valid.std.c,
n.trees=2500)
mean((yhat.boost.charity - data.valid.std.y)^2)
#Validation Set MSE = 12.64
boost.charity.posterior.valid <- predict(boost.charity,n.trees=2500, data.valid.std.c, type="response") # n.valid
post probs
profit.charity.GBM <- cumsum(14.5*c.valid[order(boost.charity.posterior.valid, decreasing=T)]-2)
plot(profit.charity.GBM ) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.charity.GBM ) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.charity.GBM )) # report number of mailings and maximum profit
#Send out 1280 mailing and maximum profit: $11,737
cutoff.gbm <- sort(boost.charity.posterior.valid , decreasing=T)[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.gbm <- ifelse(boost.charity.posterior.valid >cutoff.gbm, 1, 0) # mail to everyone above the cutoff
table(chat.valid.gbm, c.valid) # classification table
#Confusion Matrix for GBM with 2,500 trees
# 0 1
#0 725 13
#1 294 986
#GBM with 3,500 trees
set.seed(1)
boost.charity.3500 <- gbm(donr~.,
data= data.train.std.c,
distribution = "bernoulli",n.trees=3500,interaction.depth=5)
yhat.boost.charity.3500 <- predict(boost.charity.3500,newdata=data.valid.std.c,
n.trees=3500)
mean((yhat.boost.charity.3500 - data.valid.std.y)^2)
#Validation Set MSE = 13.37
boost.charity.posterior.valid.3500 <- predict(boost.charity.3500,n.trees=3500, data.valid.std.c, type="response") #
n.valid post probs
profit.charity.GBM.3500 <- cumsum(14.5*c.valid[order(boost.charity.posterior.valid.3500, decreasing=T)]-2)
plot(profit.charity.GBM.3500 ) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.charity.GBM.3500 ) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.charity.GBM.3500 )) # report number of mailings and maximum profit
#Send out 1300 mailing and maximum profit: $11,784.00
cutoff.gbm.3500 <- sort(boost.charity.posterior.valid.3500 , decreasing=T)[n.mail.valid+1] # set cutoff based on
n.mail.valid
chat.valid.gbm.3500 <- ifelse(boost.charity.posterior.valid.3500 >cutoff.gbm.3500, 1, 0) # mail to everyone above the
cutoff
table(chat.valid.gbm.3500, c.valid) # classification table
#Confusion Matrix for GBM with 3500 trees with shrinkage = 0.001
# 0 1
#0 711 7
#1 308 992
require(gbm)
set.seed(1)
boost.charity.3500.hundreth.Class <- gbm(donr~.,](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-23-320.jpg)
![data= data.train.std.c,
distribution = "bernoulli",n.trees=3500,interaction.depth=4,
shrinkage = 0.005)
yhat.boost.charity.3500.hundreth.Class <- predict(boost.charity.3500.hundreth.Class,newdata=data.valid.std.c,
n.trees=3500)
mean((yhat.boost.charity.3500.hundreth.Class - data.valid.std.y)^2)
#Validation Set MSE = 23.02
boost.charity.posterior.valid.3500.hundreth.Class <- predict(boost.charity.3500.hundreth.Class,n.trees=3500,
data.valid.std.c, type="response") # n.valid post probs
profit.charity.GBM.3500.hundreth.Class <-
cumsum(14.5*c.valid[order(boost.charity.posterior.valid.3500.hundreth.Class, decreasing=T)]-2)
plot(profit.charity.GBM.3500.hundreth.Class) # see how profits change as more mailings are made
n.mail.valid <- which.max(profit.charity.GBM.3500.hundreth.Class) # number of mailings that maximizes profits
c(n.mail.valid, max(profit.charity.GBM.3500.hundreth.Class)) # report number of mailings and maximum profit
#Send out 1214 mailing and maximum profit: $11,941.50
cutoff.gbm.3500.hundreth.Class <- sort(boost.charity.posterior.valid.3500.hundreth.Class , decreasing=T)
[n.mail.valid+1] # set cutoff based on n.mail.valid
chat.valid.gbm.3500.hundreth.Class <- ifelse(boost.charity.posterior.valid.3500.hundreth.Class
>cutoff.gbm.3500.hundreth.Class, 1, 0) # mail to everyone above the cutoff
table(chat.valid.gbm.3500.hundreth.Class, c.valid) # classification table
#Confusion Matrix for GBM with 3500 trees with shrinkage = 0.01
# 0 1
#0 796 8
#1 223 991
## Prediction Modeling ##
# Multiple regression
model.ls1 <- lm(damt ~ reg1 + reg2 + reg3 + reg4 + home + chld + hinc + genf + wrat +
avhv + incm + inca + plow + npro + tgif + lgif + rgif + tdon + tlag + agif,
data.train.std.y)
pred.valid.ls1 <- predict(model.ls1, newdata = data.valid.std.y) # validation predictions
mean((y.valid - pred.valid.ls1)^2) # mean prediction error
# 1.621358
sd((y.valid - pred.valid.ls1)^2)/sqrt(n.valid.y) # std error
# 0.1609862
# drop wrat, npro, inca
model.ls2 <- lm(damt ~ reg1 + reg2 + reg3 + reg4 + home + chld + hinc + genf +
avhv + incm + plow + tgif + lgif + rgif + tdon + tlag + agif,
data.train.std.y)
pred.valid.ls2 <- predict(model.ls2, newdata = data.valid.std.y) # validation predictions
mean((y.valid - pred.valid.ls2)^2) # mean prediction error
# 1.621898
sd((y.valid - pred.valid.ls2)^2)/sqrt(n.valid.y) # std error
# 0.1608288
# Best Subset, Backwards Stepwise Regression
library(leaps)
charity.sub.reg.back_step <- regsubsets(damt ~.,data.train.std.y,method = "backward", nvmax= 20)
plot(charity.sub.reg.back_step,scale="bic")
#reg3,reg4,home,chld,hinc,incm,tgif, lgif, rgif and agif
#Checked forwards stepwise, same variables returned for minimum bic
#Prediction Model #1
#Least Squares Regression Model - Using predcitors from backward stepwise regression
model.pred.model.1 <- lm(damt ~ reg3 + reg4 + home + chld + hinc + incm + tgif + lgif + rgif + agif,
data = data.train.std.y)
pred.valid.model1 <- predict(model.pred.model.1, newdata = data.valid.std.y) # validation predictions](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-24-320.jpg)


![cutoff.test <- sort(post.test, decreasing=T)[n.mail.test+1] # set cutoff based on n.mail.test
chat.test <- ifelse(post.test>cutoff.test, 1, 0) # mail to everyone above the cutoff
table(chat.test)
# 0 1
# 1719 288
# based on this model we'll mail to the 288 highest posterior probabilities
# See below for saving chat.test into a file for submission
# select GBM with 3,500 trees and shrinkage = 0.01 (with Gaussian Distribution)
#since it has minimum mean prediction error in the validation sample
yhat.test <- predict(boost.charity.3500.hundreth.Pred,n.trees = 3500, newdata = data.test.std) # test predictions
# Save final results for both classification and regression
length(chat.test) # check length = 2007
length(yhat.test) # check length = 2007
chat.test[1:10] # check this consists of 0s and 1s
yhat.test[1:10] # check this consists of plausible predictions of damt
ip <- data.frame(chat=chat.test, yhat=yhat.test) # data frame with two variables: chat and yhat
write.csv(ip, file="JEDM-RR-JF.csv",
row.names=FALSE) # use group member initials for file name
# submit the csv file in Angel for evaluation based on actual test donr and damt values](https://image.slidesharecdn.com/6bf03bb0-08b2-4095-9697-d7796fcd3de7-160517153503/85/JEDM_RR_JF_Final-27-320.jpg)










































