Download to read offline











![Unless otherwise indicated, these slides are © 2013-2017 Pivotal Software, Inc. and licensed under a Creative Commons
Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
Cloud Foundry for Spring Boot with JDBC
12
Running Spring Boot JDBC Apps
• Java Buildpack will auto-reconfigure your app injecting its own
DataSource configuration unless:
• You have multiple DataSource beans defined
• You have multiple RDBMS services bound to you app
• Java Buildpack auto-reconfiguration will also inject a symbolic link to it’s
jdbc driver if you don’t provide one in your app jar
• You can turn auto-reconfiguration off with an environment variable:
• JBP_CONFIG_SPRING_AUTO_RECONFIGURATION: '[enabled: false]’
• You probably still want to set the active profile:
• SPRING_PROFILES_ACTIVE: cloud](https://image.slidesharecdn.com/springone2017jdbc-171219174324/85/JDBC-What-Is-It-Good-For-12-320.jpg)





![Unless otherwise indicated, these slides are © 2013-2017 Pivotal Software, Inc. and licensed under a Creative Commons
Attribution-NonCommercial license: http://creativecommons.org/licenses/by-nc/3.0/
The JDBC Function
18
public class JdbcWriter implements Function<Map<String, Object>, String> {
@Autowired
private JdbcTemplate jdbcTemplate;
private SimpleJdbcInsert insert;
@PostConstruct
public void init() {
this.insert = new SimpleJdbcInsert(jdbcTemplate)
.withTableName("data")
.usingColumns("name", "description")
.usingGeneratedKeyColumns("id");
}
@Override
public String apply(Map<String, Object> data) {
logger.info("Received: " + data);
Object name = data.get("name");
Object description = data.get("description");
logger.info("Inserting into data table: [" + name + ", " + description +"]");
SqlParameterSource input = new MapSqlParameterSource("name", name).addValue("description", description);
Number newId = insert.executeAndReturnKey(input);
logger.info("NewId is: " + newId);
return "{ "newId": " + newId + " }";
}
}](https://image.slidesharecdn.com/springone2017jdbc-171219174324/85/JDBC-What-Is-It-Good-For-18-320.jpg)





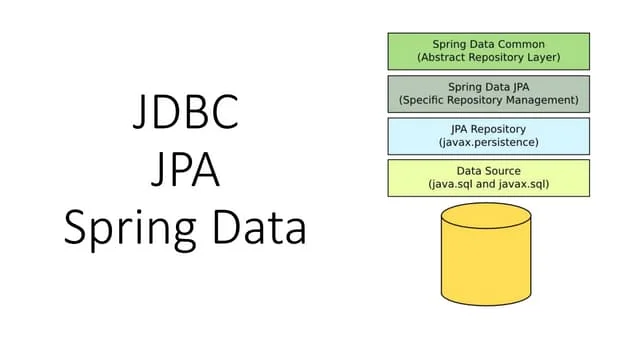
The document discusses the use of JDBC within the Spring framework, highlighting its benefits for simplifying database interactions such as connection management, exception handling, and transaction management. It presents various Spring JDBC components like JdbcTemplate and Spring Data JDBC, detailing their functionalities and applications in modern architectures including microservices, serverless, and cloud environments. Additionally, it touches on deploying Spring Boot applications with JDBC on platforms like Cloud Foundry and Kubernetes, as well as the future potential of JDBC for event sourcing and reactive programming.