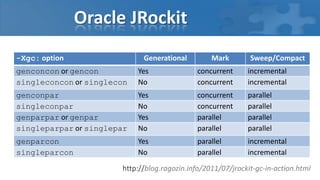
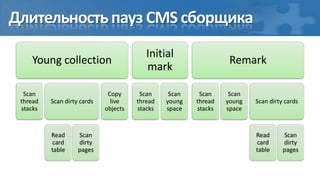
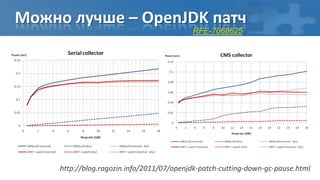
Доклад Алексея Рагозина посвящён сборке мусора в Java и автоматическому управлению памятью, охватывающий методы, алгоритмы и проблемы, связанные с паузами и параллельной обработкой. Обсуждается необходимость остановки потоков во время сборки мусора и использование барьеров для отслеживания ссылок, а также различные сборщики, такие как CMS и G1, с их настройками для оптимизации производительности. В завершение подчеркивается, что эффективность сборки мусора зависит от особенностей приложения и выделенной памяти.








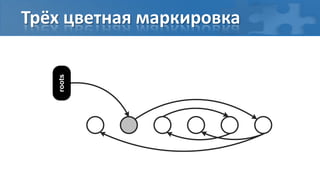
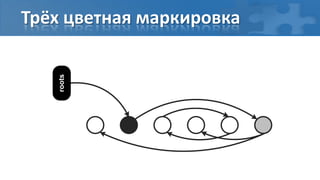
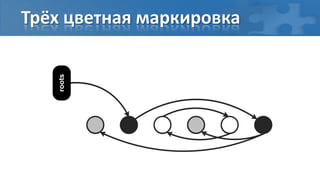
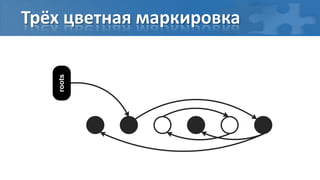
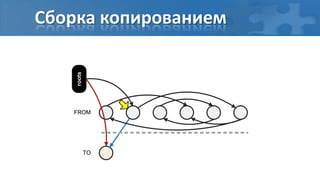
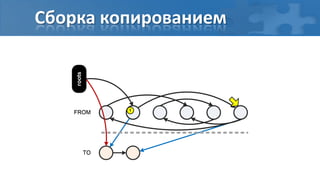
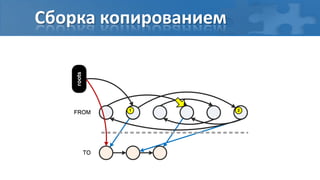
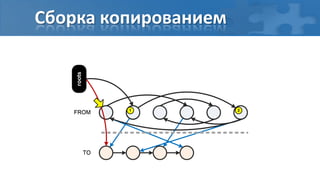
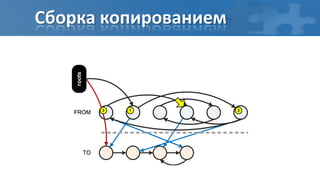
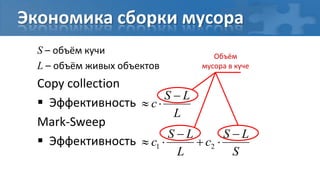

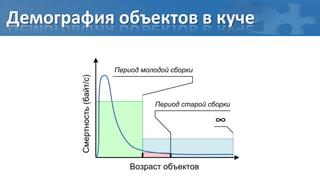


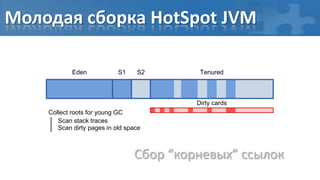





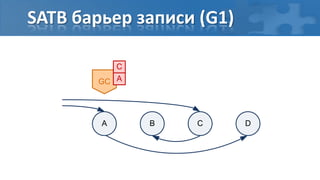
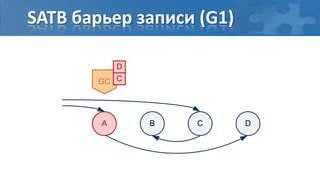
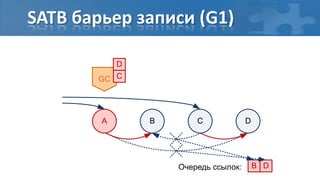
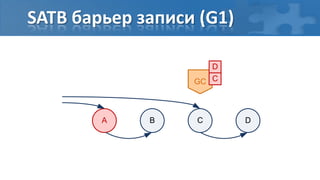
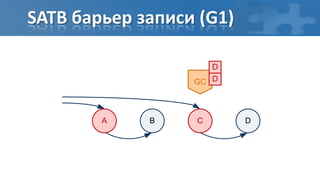
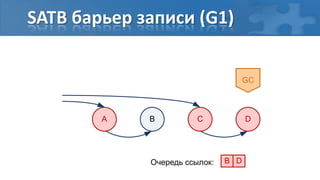
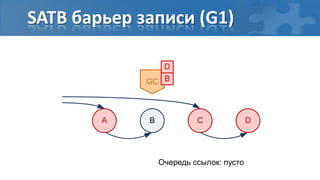
![“Card marking” барьер записи
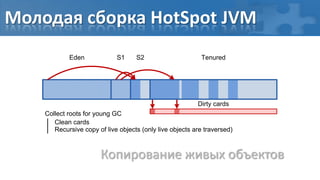
[пауза] Сбор корневых ссылок
[фон] Обход графа объектов
[фон] Перемаркирова “грязных” страниц
[паузa] Финальная перемаркирова](https://image.slidesharecdn.com/secretsofgarbagecollectioninjava-dump2012-120525130043-phpapp01/85/Java-DUMP-IT-2012-37-320.jpg)