Downloaded 10 times





![Example of a Manual Test:
nextLine()
public static void main(String[] args) {
String text = "first linensecond line";
Scanner scanner = new Scanner(text);
System.out.println(scanner.nextLine()); // prints
"first line"
System.out.println(scanner.nextLine()); // prints
"second line”
}
Code:](https://image.slidesharecdn.com/andreafrancia-introduzione-al-tdd-webtechcon-101110104054-phpapp02/85/Introduzione-al-TDD-10-320.jpg)







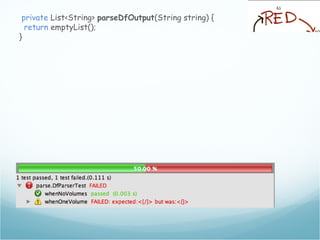
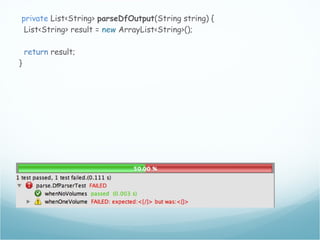
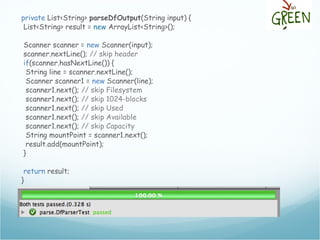
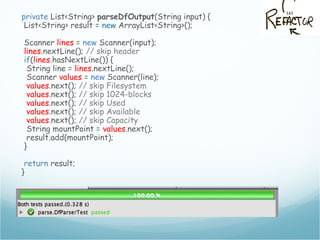
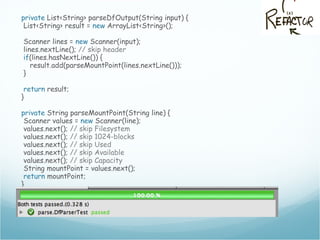
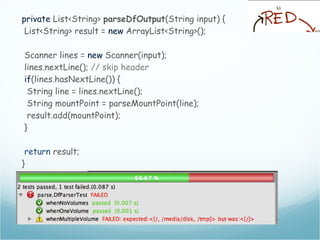
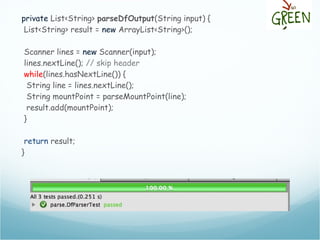
![The df output
[andreafrancia@deneb Dropbox]$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/disk0s2 243862672 135971832 107634840 56% /
/dev/disk0s1 243862672 135971832 107634840 56% /tmp
/dev/disk1s2 243862672 135971832 107634840 56% /opt
devfs 109 109 0 100% /dev
Mount Points](https://image.slidesharecdn.com/andreafrancia-introduzione-al-tdd-webtechcon-101110104054-phpapp02/85/Introduzione-al-TDD-20-320.jpg)





























![Estrazione del comportamento
public class MemoryDivinationRepo {
Divination lastDivinationForSign(String sign);
void saveDivinationFromPronounce(String sign,
String pronounce);
};
public interface Divination {
String asText();
byte[] asMp3();
};](https://image.slidesharecdn.com/andreafrancia-introduzione-al-tdd-webtechcon-101110104054-phpapp02/85/Introduzione-al-TDD-58-320.jpg)





![Example of an Automated Test
@Test public void shouldParsePath() {
String content =
"[Trash Info]n"
+ "Path=/home/andrea/foo.txtn"
+ "DeletionDate=2010-08-23T12:59:14n";
String path = Parser.parsePath(content);
assertEquals("/home/andrea/foo.txt”,
path);
}](https://image.slidesharecdn.com/andreafrancia-introduzione-al-tdd-webtechcon-101110104054-phpapp02/85/Introduzione-al-TDD-64-320.jpg)


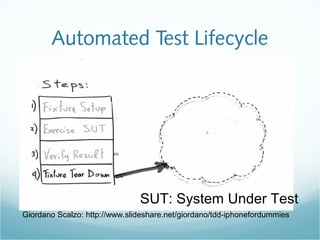
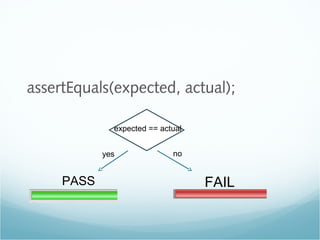
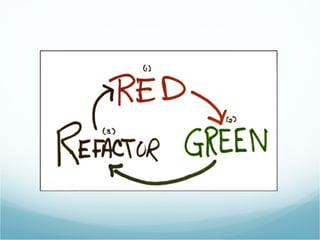
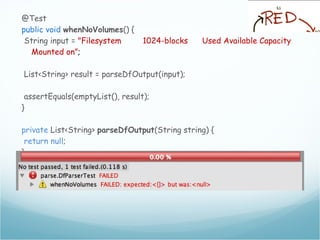
This document provides an introduction to Test Driven Development (TDD) in Italian. It defines key TDD concepts like "test first" and automating tests. It then provides examples of using TDD to develop a parser for the "df" command output and features for an astrology horoscope application. The examples demonstrate the TDD process of writing a failing test, then code to pass the test, and refactoring. Rules for TDD like keeping tests passing and writing tests for all features are also outlined.


























































































