Download to read offline












![There are several types of Spark RDD. Such as: RDD [int], RDD [long],
RDD [string].
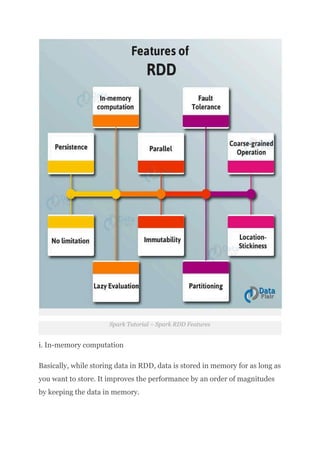
xi. No limitation
There are no limitations to use the number of Spark RDD. We can use any
no. of RDDs. Basically, the limit depends on the size of disk and memory.
In this Apache Spark tutorial, we cover most Features of Spark RDD to
learn more about RDD Features follow this link.
7. Spark Tutorial – Spark
Streaming
While data is arriving continuously in an unbounded sequence is what we
call a data stream. Basically, for further processing, Streaming divides
continuous flowing input data into discrete units. Moreover, we can say it is
a low latency processing and analyzing of streaming data.
In addition, an extension of the core Spark API Streaming was added to
Apache Spark in 2013. That offers scalable, fault-tolerant and
high-throughput processing of live data streams. Although, here we can do
data ingestion from many sources. Such as Kafka, Apache Flume, Amazon
Kinesis or TCP sockets. However, we do processing here by using complex
algorithms which are expressed with high-level functions such as map,
reduce, join and window.
a. Internal working of Spark Streaming](https://image.slidesharecdn.com/introductiontospark-250822034929-3d5f77fb/85/Introduction-to-Spark-for-Beginners-14-320.jpg)

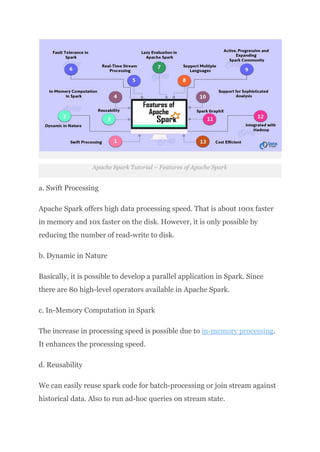
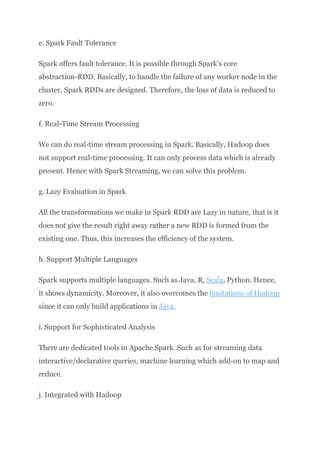

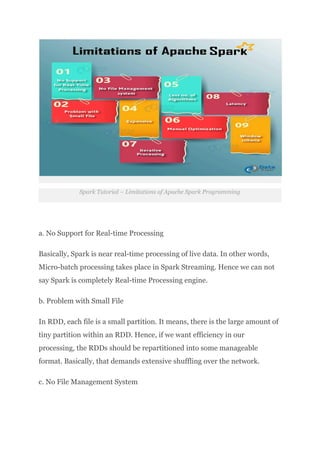

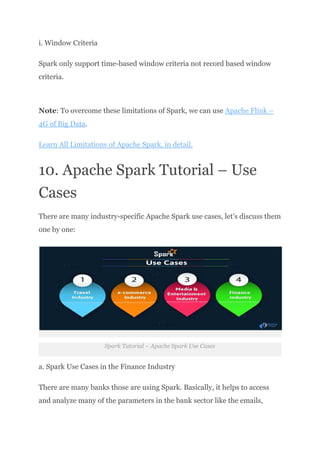



we will see an overview of Spark in Big Data. We will start with an introduction to Apache Spark Programming. Then we will move to know the Spark History. Moreover, we will learn why Spark is needed. Afterward, will cover all fundamental of Spark components.


























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








