Download as PDF, PPTX











































![78
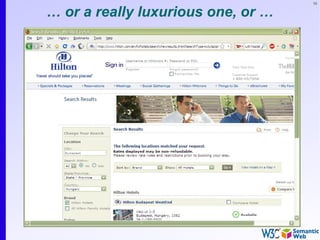
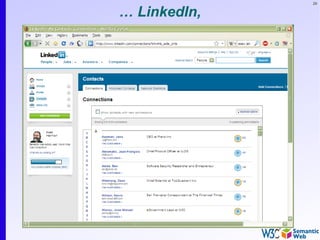
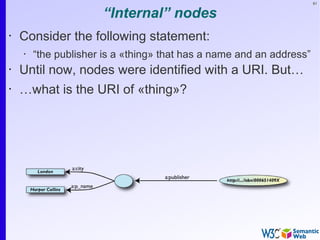
RDF triples (cont.)
• Resources can use any URI, e.g.:
• http://www.example.org/file.xml#element(home)
• http://www.example.org/file.html#home
• http://www.example.org/file2.xml#xpath1(//q[@a=b])
• URI-s can also denote non Web entities:
• http://www.ivan-herman.net/me is me
• not my home page, not my publication list, but me
• RDF triples form a directed, labelled graph](https://image.slidesharecdn.com/swintro-2009-090621120740-phpapp01/85/Introduction-to-Semantic-Web-78-320.jpg)


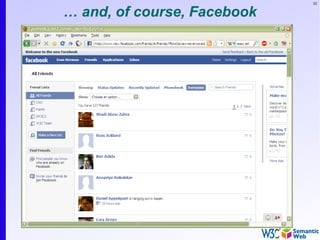
![84
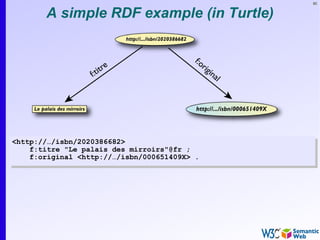
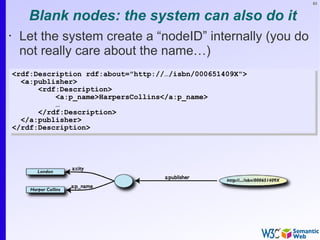
Same in Turtle
<http://…/isbn/000651409X> a:publisher [
<http://…/isbn/000651409X> a:publisher [
a:p_name "HarpersCollins";
a:p_name "HarpersCollins";
……
].
].](https://image.slidesharecdn.com/swintro-2009-090621120740-phpapp01/85/Introduction-to-Semantic-Web-84-320.jpg)







































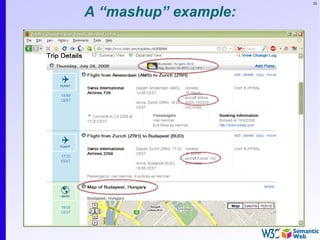
![136
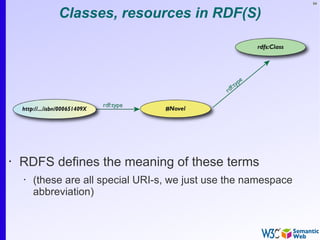
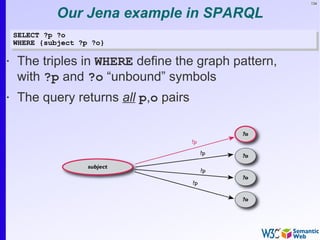
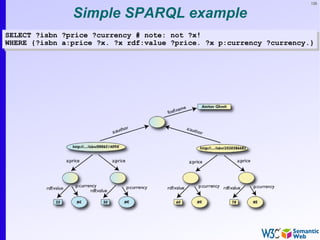
Simple SPARQL example
SELECT ?isbn ?price ?currency # note: not ?x!
SELECT ?isbn ?price ?currency # note: not ?x!
WHERE {?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.}
WHERE {?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.}
• Returns:
[[<..49X>,33,£], [<..49X>,50,€], [<..6682>,60,€],
[<..6682>,78,$]]](https://image.slidesharecdn.com/swintro-2009-090621120740-phpapp01/85/Introduction-to-Semantic-Web-136-320.jpg)
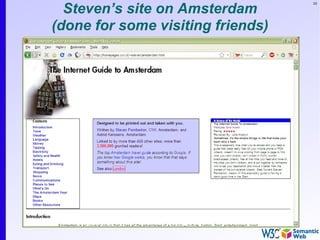
![137
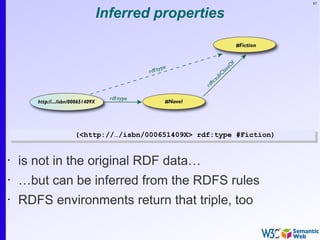
Pattern constraints
SELECT ?isbn ?price ?currency # note: not ?x!
SELECT ?isbn ?price ?currency # note: not ?x!
WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.
WHERE { ?isbn a:price ?x. ?x rdf:value ?price. ?x p:currency ?currency.
FILTER(?currency == € }
FILTER(?currency == € }
• Returns: [[<..409X>,50,€], [<..6682>,60,€]]](https://image.slidesharecdn.com/swintro-2009-090621120740-phpapp01/85/Introduction-to-Semantic-Web-137-320.jpg)





















![161
Restrictions formally
• Defines a class of type owl:Restriction with a
• reference to the property that is constrained
• definition of the constraint itself
• One can, e.g., subclass from this node when
defining a particular class
:Listed_Price rdfs:subClassOf [
:Listed_Price rdfs:subClassOf [
rdf:type
rdf:type owl:Restriction;
owl:Restriction;
owl:onProperty
owl:onProperty p:currency;
p:currency;
owl:allValuesFrom
owl:allValuesFrom :Currency.
:Currency.
].
].](https://image.slidesharecdn.com/swintro-2009-090621120740-phpapp01/85/Introduction-to-Semantic-Web-161-320.jpg)
![162
Possible usage…
If:
:Listed_Price rdfs:subClassOf [
:Listed_Price rdfs:subClassOf [
rdf:type
rdf:type owl:Restriction;
owl:Restriction;
owl:onProperty
owl:onProperty p:currency;
p:currency;
owl:allValuesFrom
owl:allValuesFrom :Currency.
:Currency.
].
].
:price rdf:type :Listed_Price .
:price rdf:type :Listed_Price .
:price p:currency <something> .
:price p:currency <something> .
then the following holds:
<something> rdf:type :Currency .
<something> rdf:type :Currency .](https://image.slidesharecdn.com/swintro-2009-090621120740-phpapp01/85/Introduction-to-Semantic-Web-162-320.jpg)















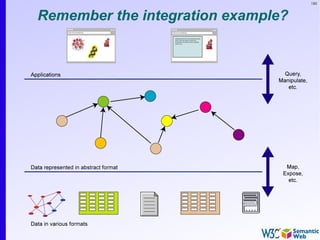
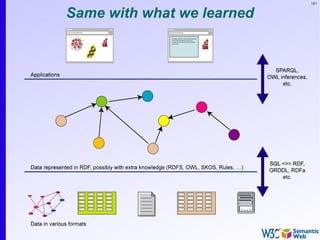











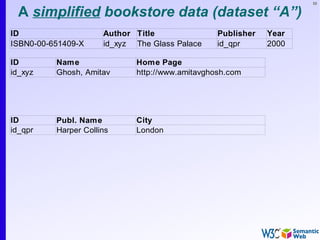
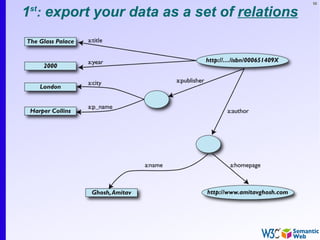
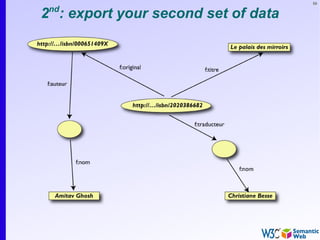
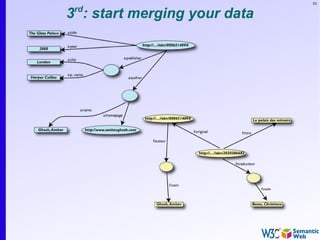
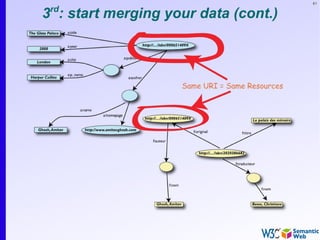
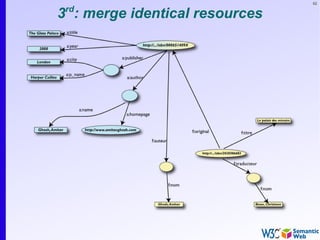
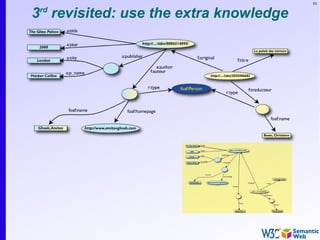
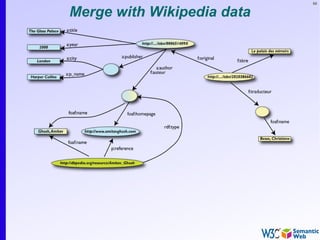
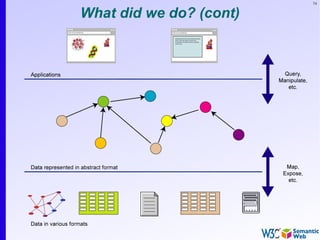
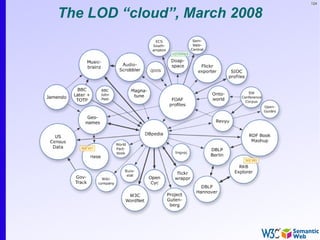
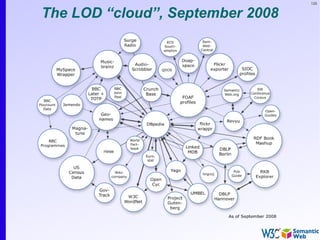
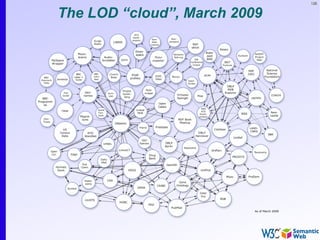
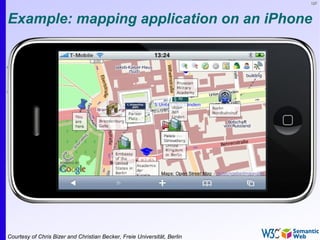
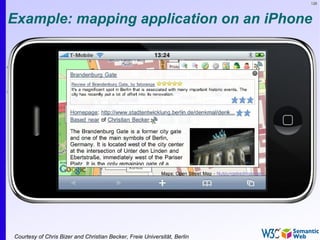
The document provides an introduction to the Semantic Web by using a simplified example of combining bookstore data from different sources. It demonstrates how [1] exporting data as relations, [2] merging the relations based on identical resources, and [3] adding extra knowledge allows for more powerful queries across datasets. The key components that enable this are using URIs to identify resources, representing data as RDF triples, and classifying resources and properties with common terminologies like ontologies. This approach aims to realize a Web of Data where decentralized and heterogeneous data sources can be programmatically integrated and queried.











































































