Download as PDF, PPTX







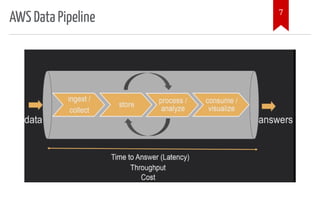


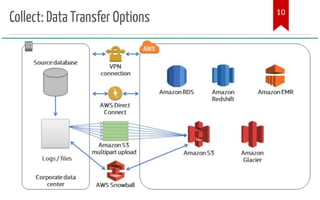


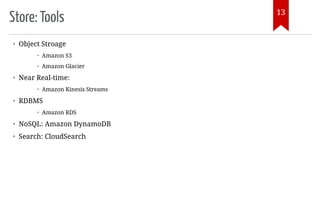

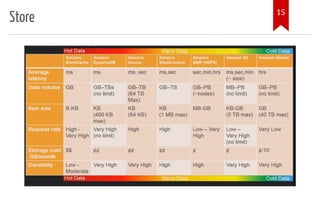

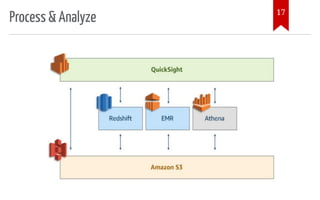


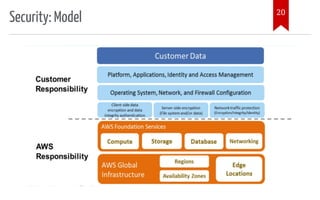
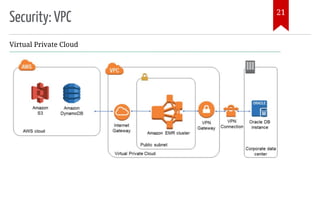
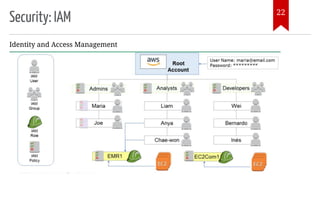








The document introduces AWS Data Pipeline services, outlining key goals such as problem identification and tool implementation. It discusses big data characteristics, AWS advantages, storage types, processing tools, security measures, and cost considerations. A demonstration using AWS services like Glue, Athena, and QuickSight is also included.

































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








