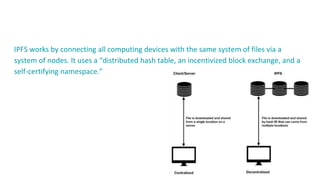
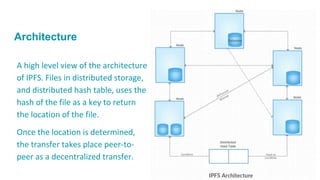
IPFS is a peer-to-peer hypermedia protocol designed to preserve and grow humanity's knowledge by making the web more resilient and open. It uses content addressing to uniquely identify each file in a global namespace, connecting IPFS hosts to transfer data in a decentralized way. Data is stored in IPFS as chunks that are cryptographically hashed and given a content identifier to allow for permanent storage and versioning of files. While IPFS promises advantages over the current HTTP system like bandwidth savings and preservation of data, challenges include a lack of economic incentives, unreliability for private data, and inability to verify data integrity without a solution like Filecoin.