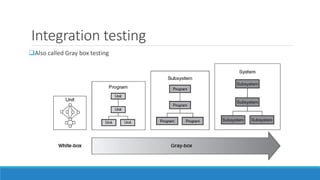
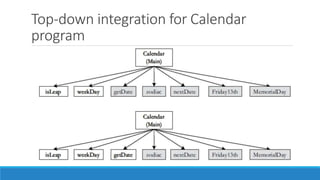
Integration testing involves integrating units or components into larger programs and subsystems. There are several approaches to integration testing, including decomposition-based, call graph-based, pairwise, and neighborhood integration. Decomposition-based integration uses a functional decomposition tree to guide integration from top-down or bottom-up. Call graph-based integration uses the actual calling relationships between units to avoid issues with decomposition-based approaches. Pairwise integration tests all pairs of units that call each other, while neighborhood integration focuses testing within units and their neighboring call units. Both aim to improve on stubs/drivers while maintaining fault isolation.



































































































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)













