Download as PDF, PPTX






























![Linked resources
resource "aws_security_group" "allow_all" {
name = "allow_all"
ingress {
from_port = 0
to_port = 65535
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_instance" "web" {
ami = "ami-12345"
instance_type = "t2.micro"
vpc_security_group_ids = [“${aws_security_group.allow_all.id}”]
tags {
Name = "HelloWorld"
}
}
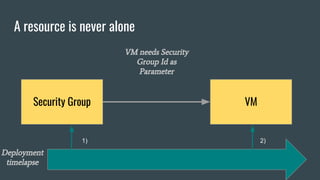
Referenced resource
A resource has output
values like :
● Id
● DNS name
● Ip
● ...](https://image.slidesharecdn.com/conference-180404184933/85/Infrastructure-as-Code-with-Terraform-44-320.jpg)


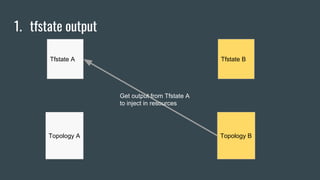


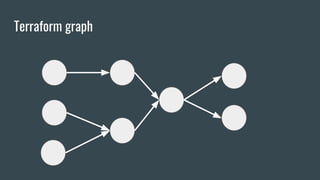
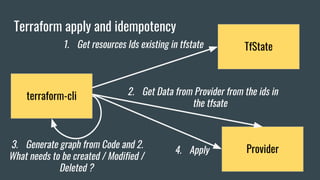
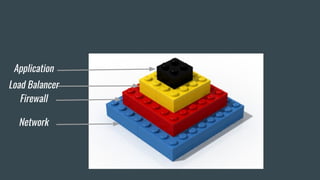
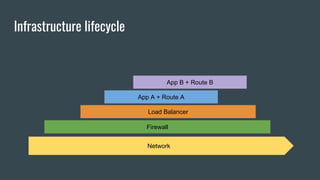
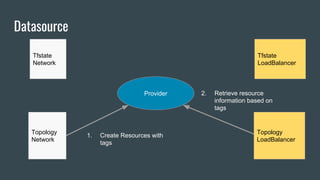
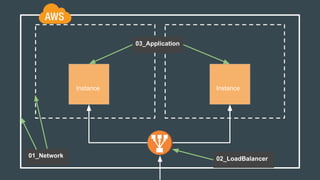
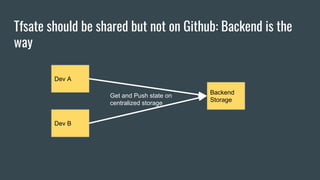
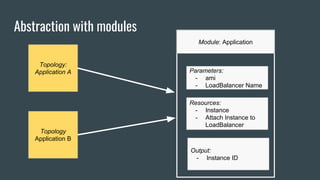
This document discusses using Terraform to manage cloud infrastructure as code. Terraform allows infrastructure to be defined using declarative configuration files that can be treated as code and versioned. It uses a provider model to interact with different cloud APIs to deploy and manage resources. Key features discussed include idempotency, the Terraform graph, modules for abstraction, variables, and linking dependent resources.



















































