Downloaded 27 times




![©2016 Couchbase Inc. 9
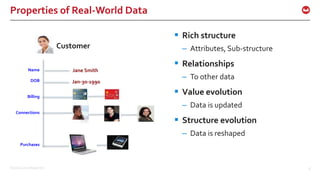
Transform: Relational to JSON
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
DocumentKey: CBL2015
CustomerID Name DOB
CBL2015 Jane Smith 1990-01-30
Customer
ID
Type Cardnum Expiry
CBL2015 visa 5827… 2019-03
CBL2015 maste
r
6274… 2018-12
CustomerID ConnId Name
CBL2015 XYZ987 Joe Smith
CBL2015 SKR007 Sam Smith
CustomerID item amt
CBL2015 mac 2823.52
CBL2015 ipad2 623.52
CustomerID ConnId Name
CBL2015 XYZ987 Joe Smith
CBL2015 SKR007 Sam
Smith
Contacts
Customer
Billing
ConnectionsPurchases](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-9-320.jpg)
![©2016 Couchbase Inc. 10
JSON
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
JSON is a means to the end and not the end itself
– JSON is the representation of the enterprise data model for applications
– JSON flexibility translates to application flexibility
• Simple flattened data can be represented
• Entities with complex data, always accessed analyzed together should belong
together
– Applications are designed to handle the flexible data model.](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-10-320.jpg)


![©2016 Couchbase Inc. 13
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo ResultDocuments
Orders
CUSTOMER
Built Manually; Expensive](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-13-320.jpg)
![©2016 Couchbase Inc. 14
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo ResultDocuments
Orders
CUSTOMER](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-14-320.jpg)











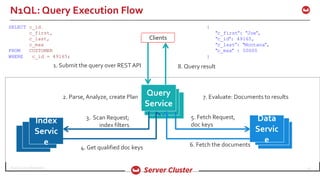

![©2016 Couchbase Inc. 30
Prepare Phase: Parse & Semantic Check
Analyzes the Query for syntax & grammar
Only verifies for existence of referenced buckets
Flexible schema means, you can refer to arbitrary attribute
names. N1QL key names are CaSe SENSitive.
A key is NULL if it’s a known null. {“location”:null}
A key is MISSING if not present in the document
Use IS NULL and IS MISSING to check for each condition
Full reference to JSON structure
– Nested reference: CUSTOMER.contact.address.state
– Array Reference: CUSTOMER.c_contact.phone_number[0]
SQL is enhanced to access & manipulateArrays
Fetch
Parse
Plan
Join
Filter
Offset
Limit
Project
Sort
Aggre
gate
Scan](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-30-320.jpg)

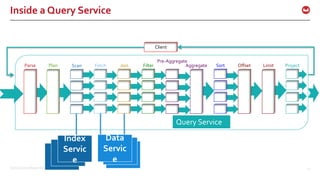
![©2016 Couchbase Inc. 32
PREPARE
Fetch
Parse
Plan
Join
Filter
Offset
Limit
Project
Sort
Aggre
gate
Scan
Ever statement executed in the engine is PREPARED
When you have same statement executed millions of
times, you can save prepare time
Prepare statement can use simple adhoc statement
PREPARE p1 FROM SELECT * from `beer-sample` LIMIT 1;
EXECUTE p1;
Compare the execution time
Prepare Statement can exploit parameters to bind
PREPARE p2 FROM SELECT * from `beer-sample` WHERE abv = $1;
$ curl http://localhost:8093/query/service -H "Content-
Type: application/json" -d '{"prepared":"p2",
"args":[5.0]}’
$ curl http://localhost:8093/query/service -d 'prepared
="mp"&args=[5.0]’](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-32-320.jpg)
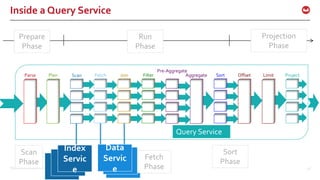
![©2016 Couchbase Inc. 33
PREPARE
Fetch
Parse
Plan
Join
Filter
Offset
Limit
Project
Sort
Aggre
gate
Scan
Ever statement executed in the engine is PREPARED
When you have same statement executed millions of
times, you can save prepare time
Prepare statement can use simple adhoc statement
PREPARE p1 FROM SELECT * from `beer-sample` LIMIT 1;
EXECUTE p1;
Compare the execution time
Prepare Statement can exploit parameters to bind
PREPARE p2 FROM SELECT * from `beer-sample` WHERE abv = $1;
$ curl http://localhost:8093/query/service -H "Content-
Type: application/json" -d '{"prepared":"p2",
"args":[5.0]}’
$ curl http://localhost:8093/query/service -d 'prepared
="mp"&args=[5.0]’](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-33-320.jpg)

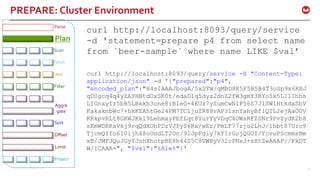







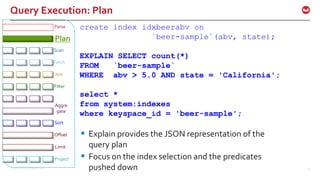
![©2016 Couchbase Inc. 44
Query Execution: Plan
Fetch
Parse
Plan
Join
Filter
Offset
Limit
Project
Sort
Aggre
gate
Scan
create index idxtypeabvstate on `beer-
sample`(abv, state) where type = ‘beer’;
select * from system:indexes where name =
'idxtypeabvstate';
"indexes": {
"condition": "(`type` = "beer")",
"datastore_id": "http://127.0.0.1:8091",
"id": "611ffca1720b7868",
"index_key": [
"`abv`",
"`state`"
],
"keyspace_id": "beer-sample",
"name": "idxtypeabvstate",
"namespace_id": "default",
"state": "online",
"using": "gsi"
}](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-44-320.jpg)









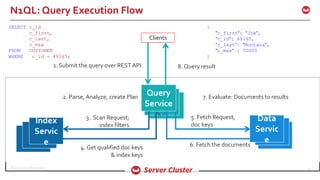
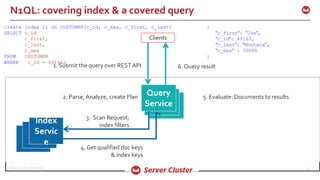

![©2016 Couchbase Inc. 62
create index idxstatecity on `beer-
sample`(state,city) using gsi;
EXPLAIN
SELECT city
FROM`beer-sample`
WHERE state = 'California';
N1QL: Example
{
"requestID": "eef73760-d09e-48e0-a43a-c8da1e0be998
"signature": "json",
"results": [
{
"#operator": "Sequence",
"~children": [
{
"#operator": "IndexScan",
"covers": [
"cover((meta(`beer-sample`).`id`))",
"cover((`beer-sample`.`state`))",
"cover((`beer-sample`.`city`))"
],
"index": "idxstatecity",
"keyspace": "beer-sample",
"namespace": "default",
"spans": [
{
]](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-61-320.jpg)


![©2016 Couchbase Inc. 65
Create index idxstatecountry on `beer-sample(state, country) using gsi;
-- select in insert statement
insert into `travel-sample`(KEY k, value state)
Select country as k, state from `beer-sample b where stat = ‘ca’;
-- Supports Arrays
Create index idxarray on `beer-sample`(a, b);
Select b from `beer-sample` where a = [1, 2, 3, 4];
N1QL: Examples](https://image.slidesharecdn.com/queryv0-160126174928/85/Query-in-Couchbase-N1QL-SQL-for-JSON-64-320.jpg)







The document discusses the evolution from relational databases to NoSQL and highlights Couchbase's N1QL, which enables SQL-like querying of JSON data. It emphasizes the flexible structure of JSON, the complexities handled by N1QL, and the advantages of using prepared statements for improved performance. The material provides insights into data representation, querying methods, and the execution flow within Couchbase systems.


























































































