Downloaded 11 times



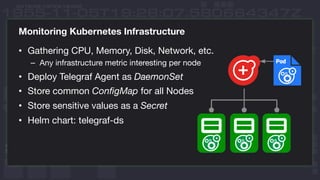



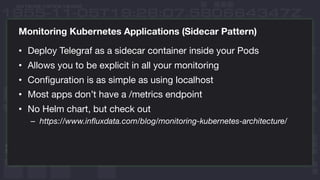





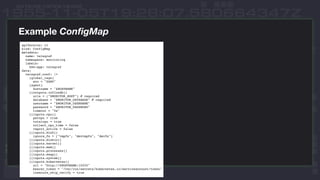

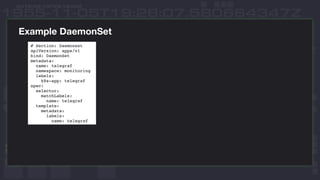
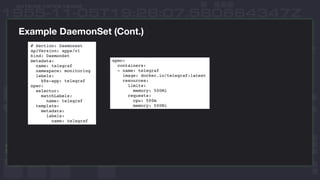
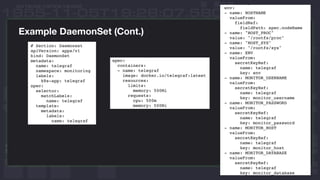

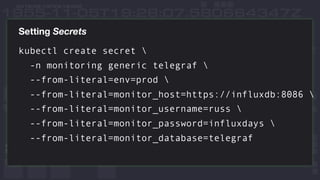

This document discusses using InfluxDB and Kubernetes for monitoring. It provides an overview of deploying InfluxDB and Chronograf using Helm charts. It also describes monitoring Kubernetes infrastructure by deploying Telegraf as a DaemonSet to collect metrics from nodes. Additionally, it covers monitoring applications by deploying Telegraf as a single pod to scrape metrics or as a sidecar. Lastly, it discusses future plans for an InfluxData operator and running InfluxEnterprise outside Kubernetes clusters.






























![Nicolas Steinmetz [CérénIT] | Sustain Your Observability from Bare Metal TICK...](https://cdn.slidesharecdn.com/ss_thumbnails/sustainable-observability-from-bare-metal-to-k8s-world-nicolas-steinmetz-200623205020-thumbnail.jpg?width=640&height=640&fit=bounds)
































![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)