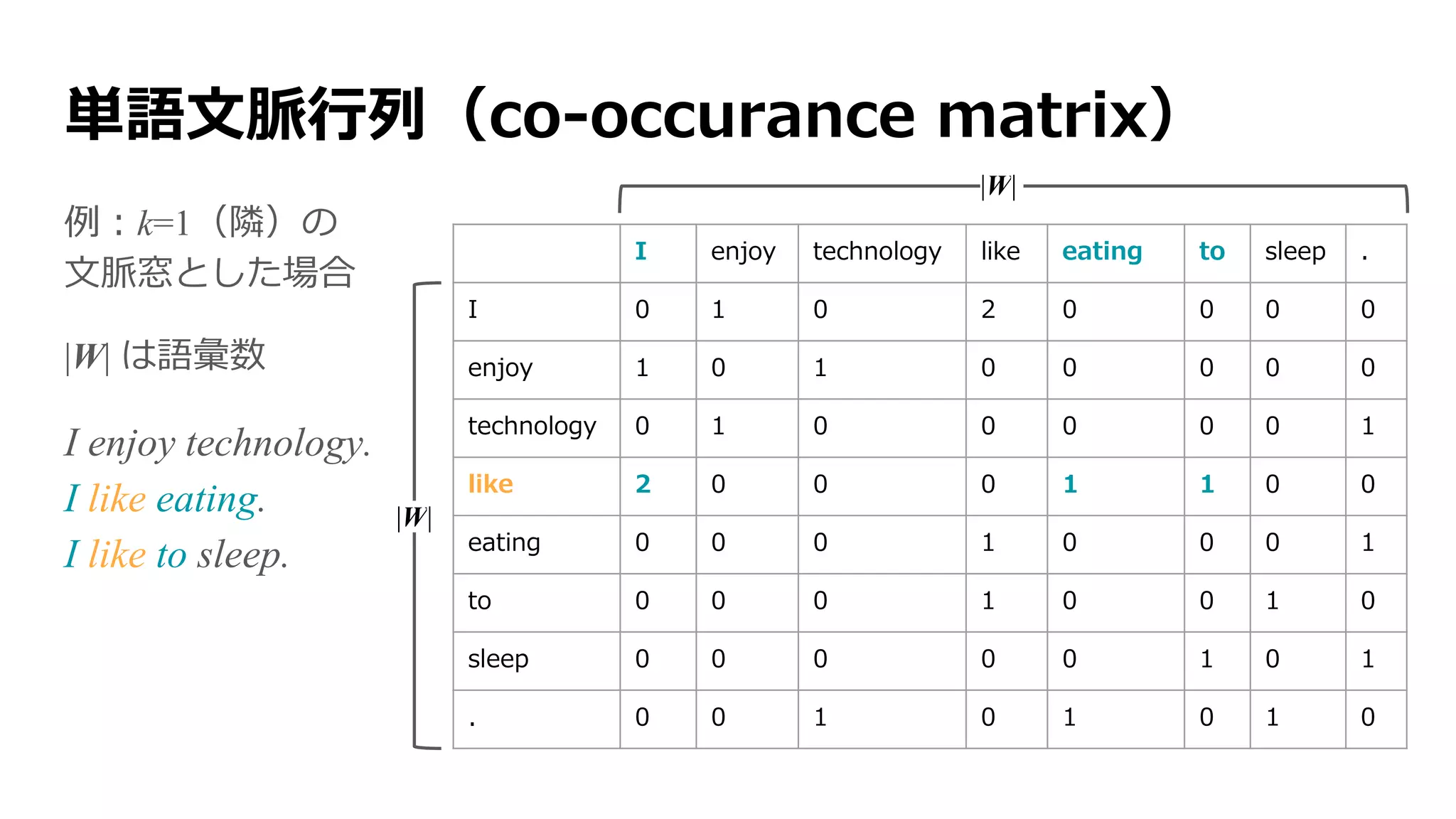
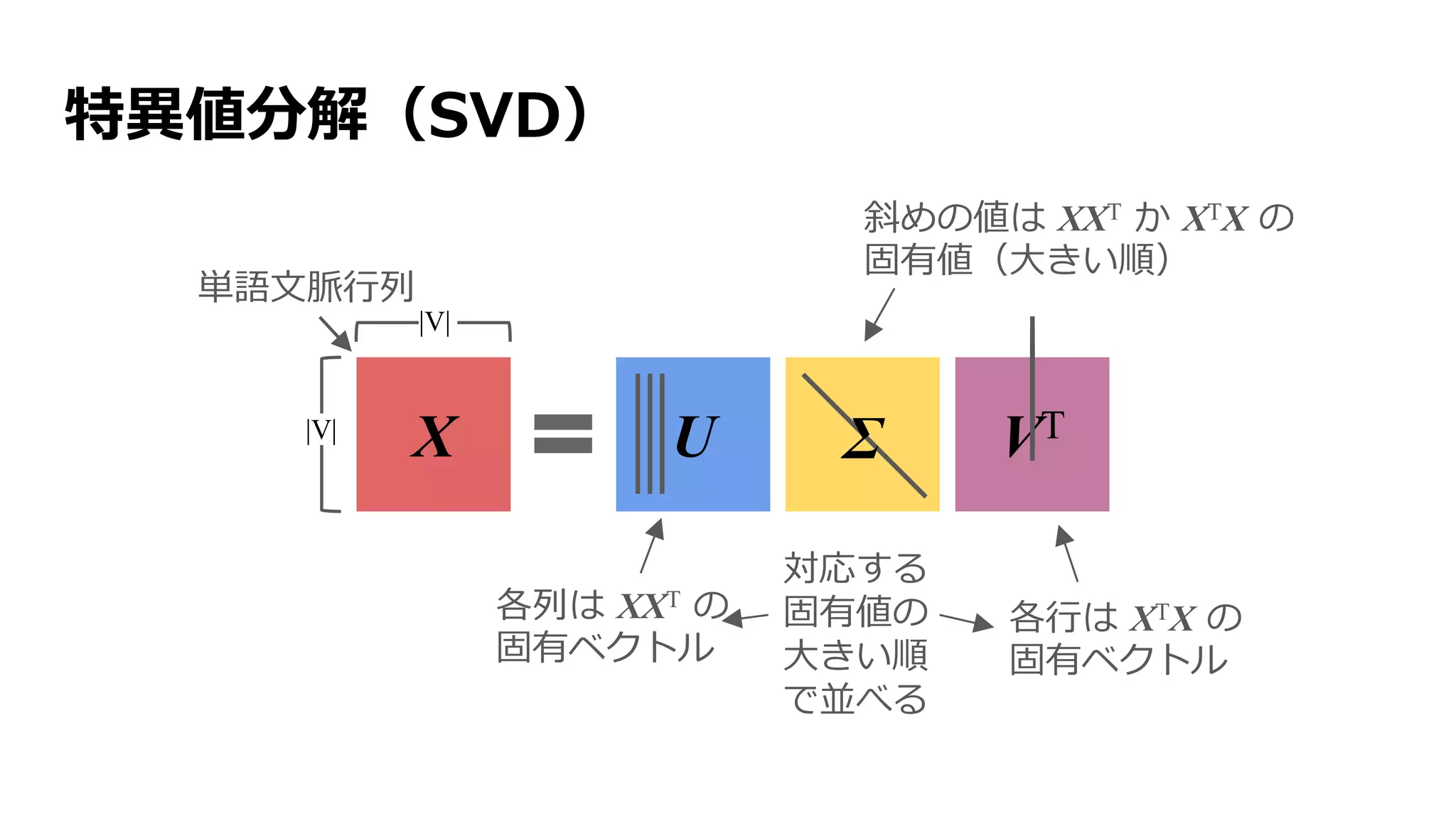
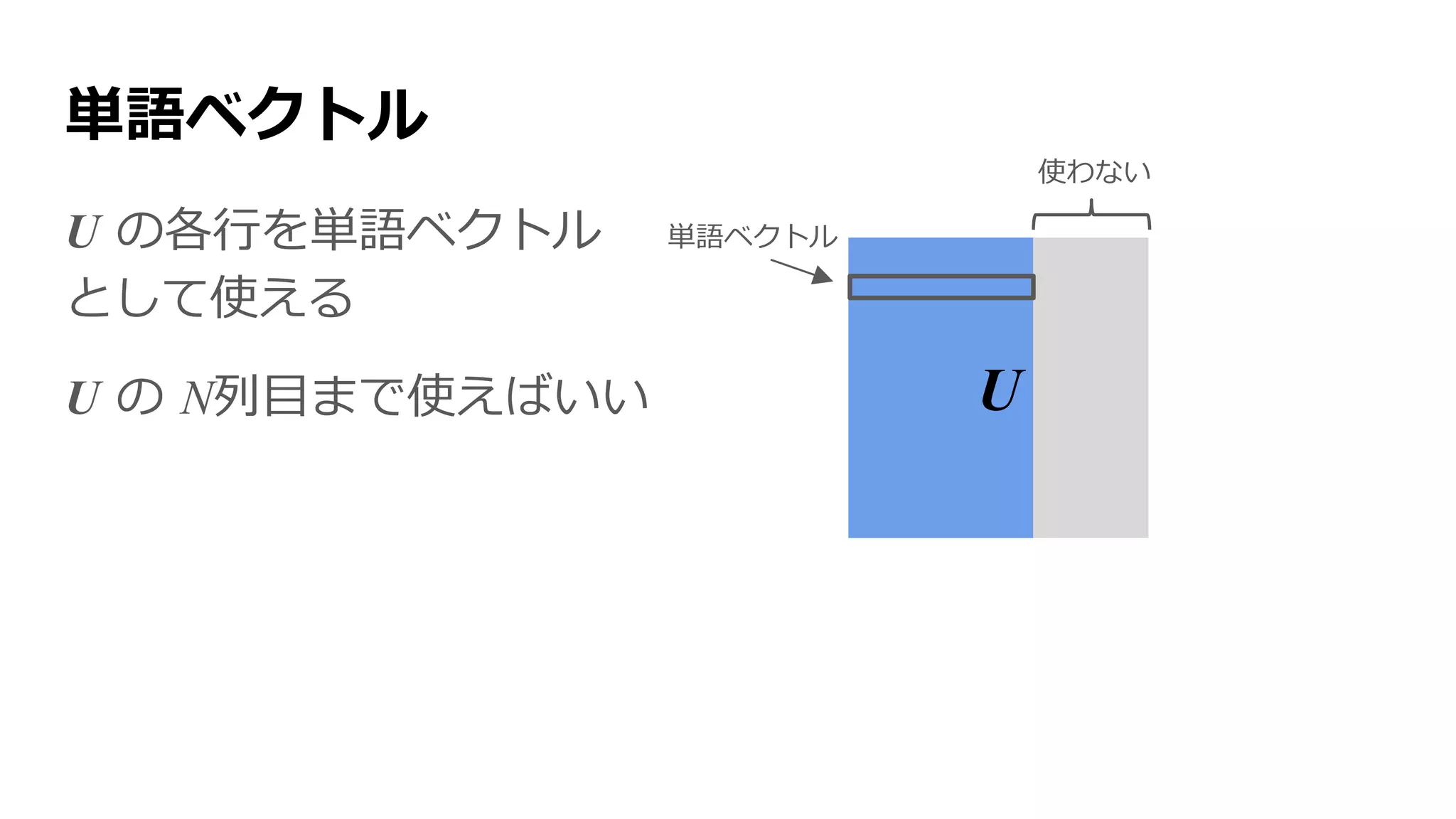
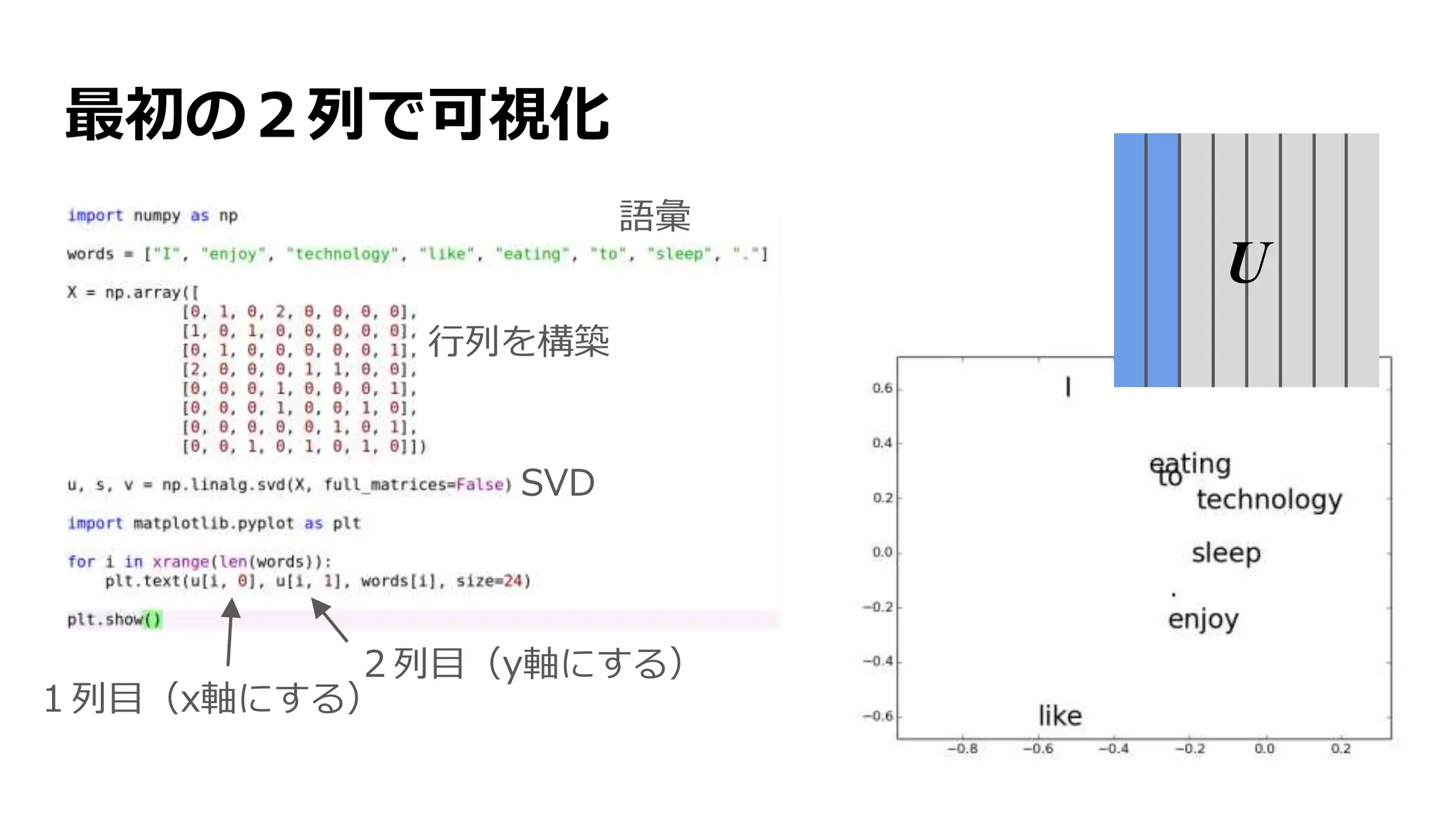
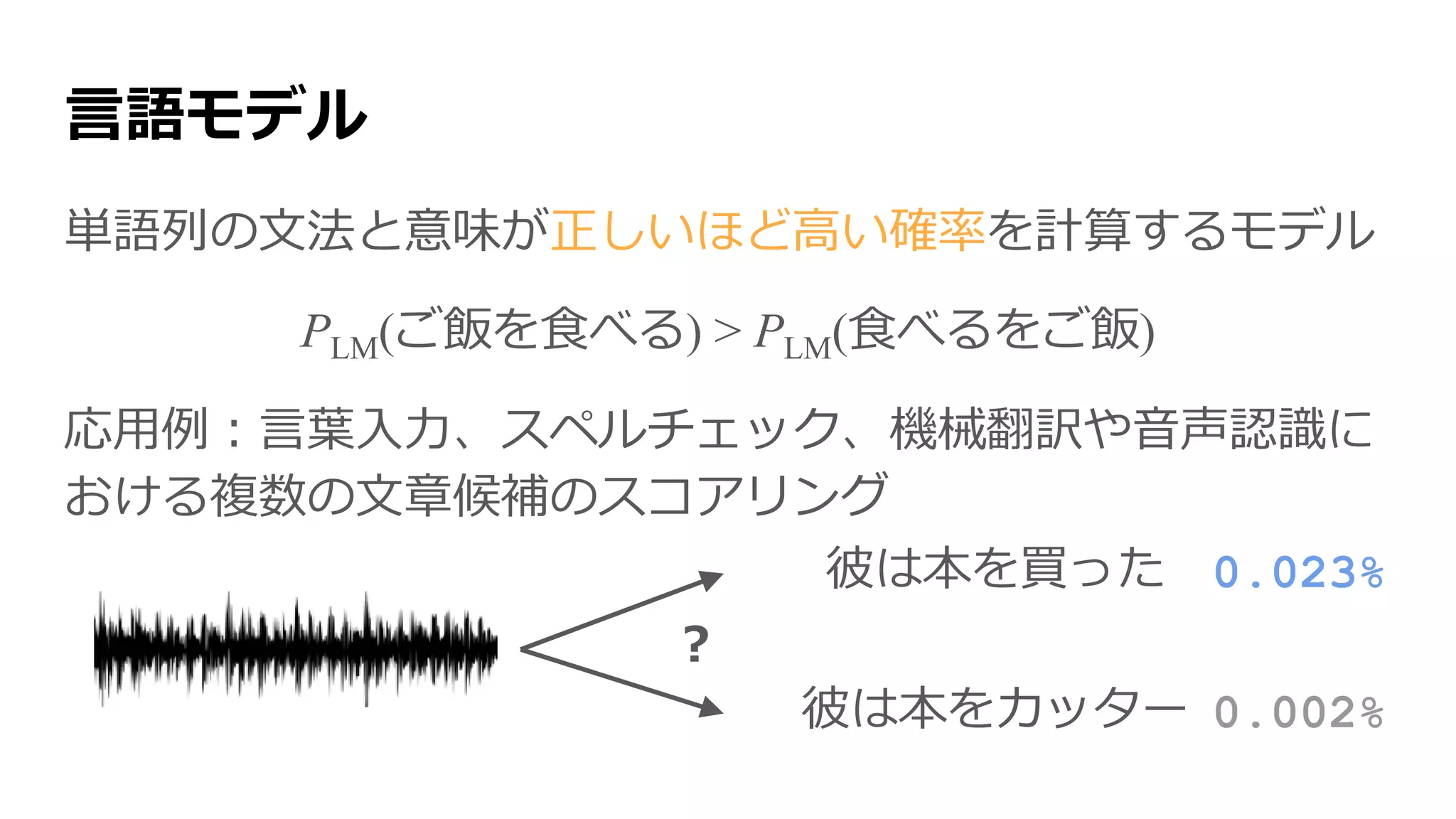
自然言語処理(NLP)
機械に人間の言語を処理させること
...This is justa bunch of
words to explain what
natural language
processing is and is not
meant to be read. All I
want to say is that it’s
all about having
machines do useful
stuff with language...
!
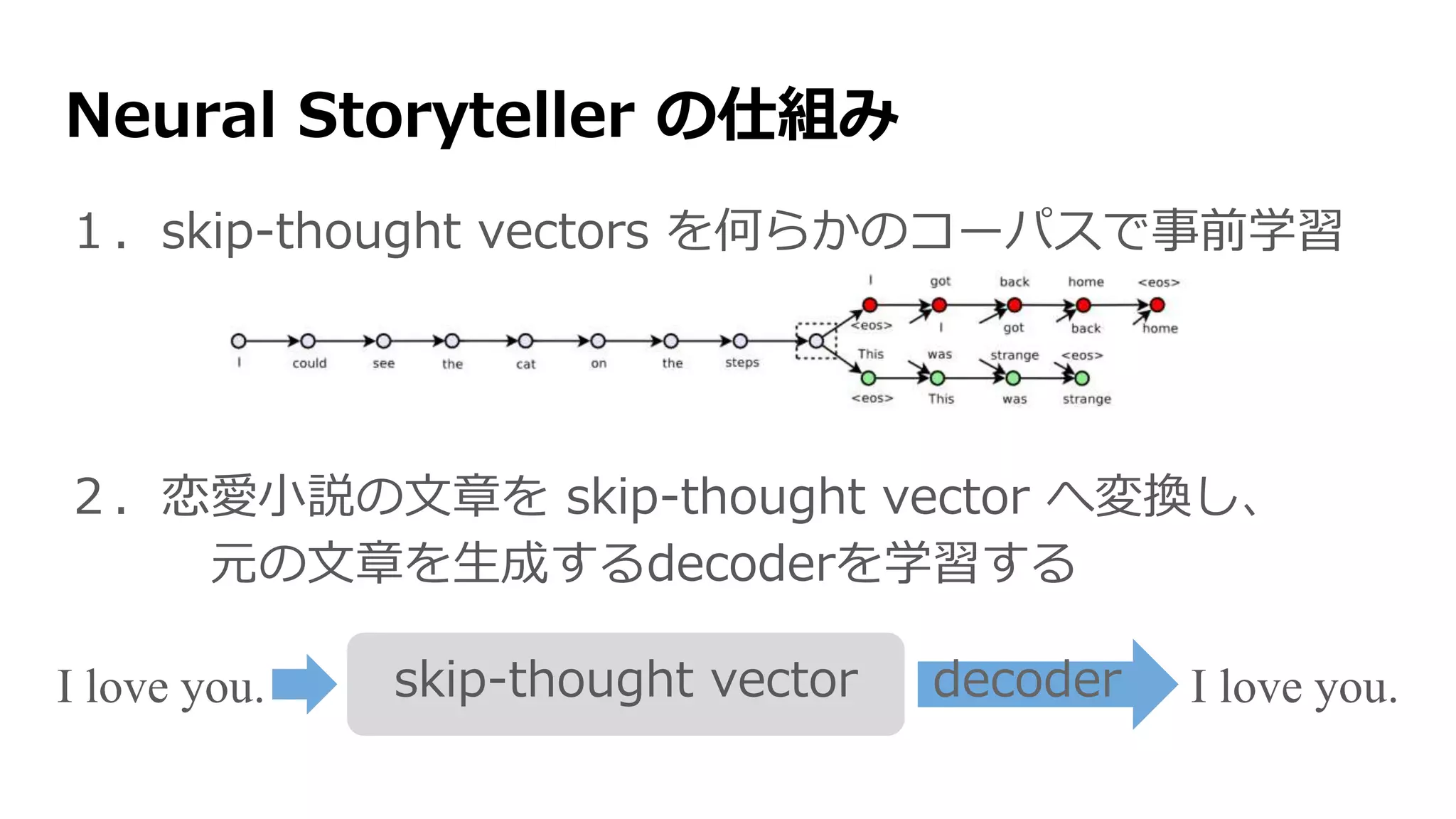
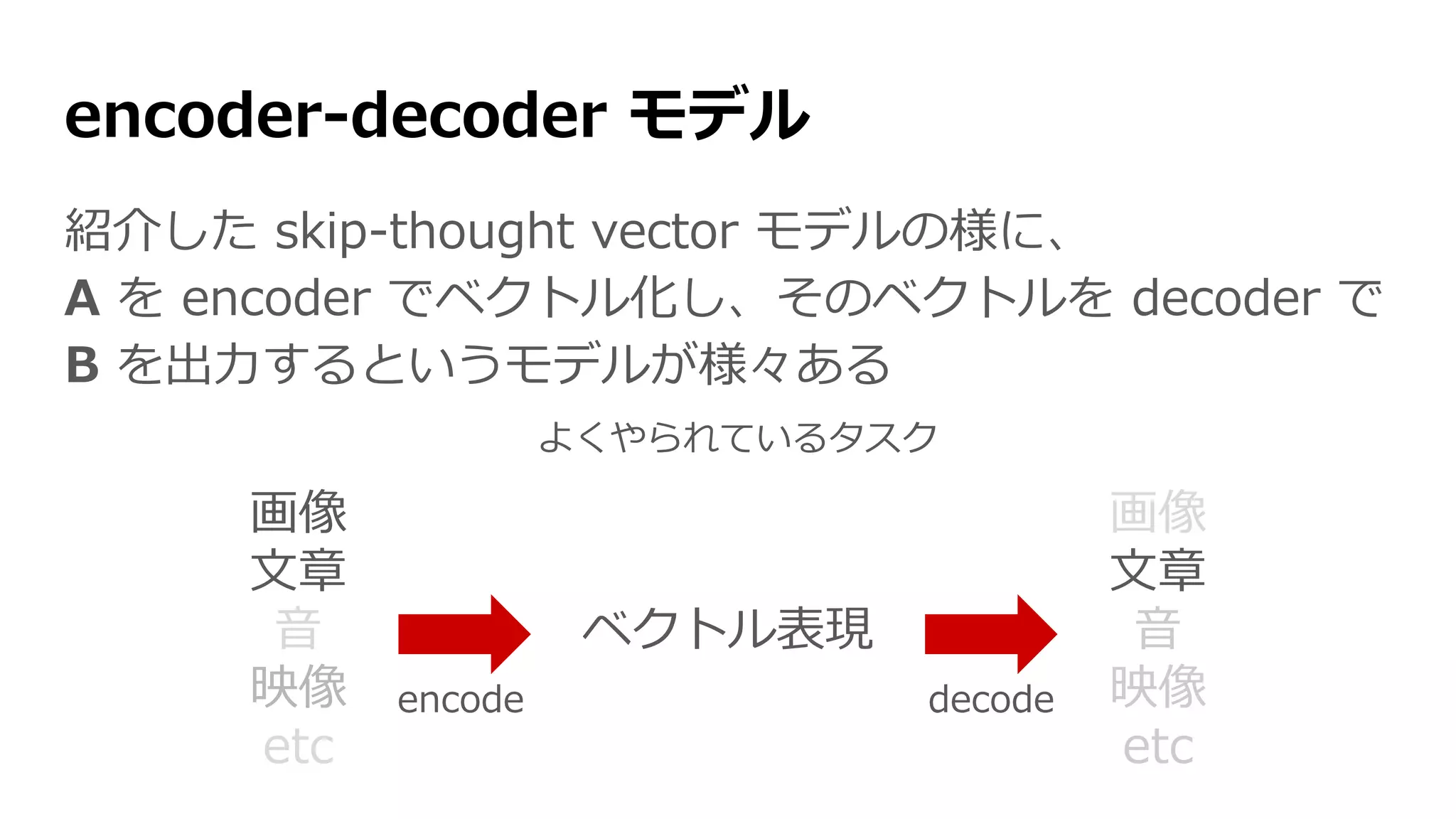
Skip-Thought Vectors [Kiros+2015]
skip-gram の文章版(文章→前後の文章)
... I got back home. I could see the cat on the steps. This was strange. …
encoder RNNが文章の単語ベクトル
を一つずつ読み込んでいく
内部状態を文章のベクトルとして使う
2つの decoder RNNがそのベクトルか
ら前後の文章を生成
72.
最大対数尤度
... I gotback home. I could see the cat on the steps. This was strange. …
中心の文章が「I could see the cat on the steps.」の場合、
前文decoder が「I got back home.」と
後文decoder が「This was strange.」の出力確率を高くする
目標関数
後の文章 前の文章
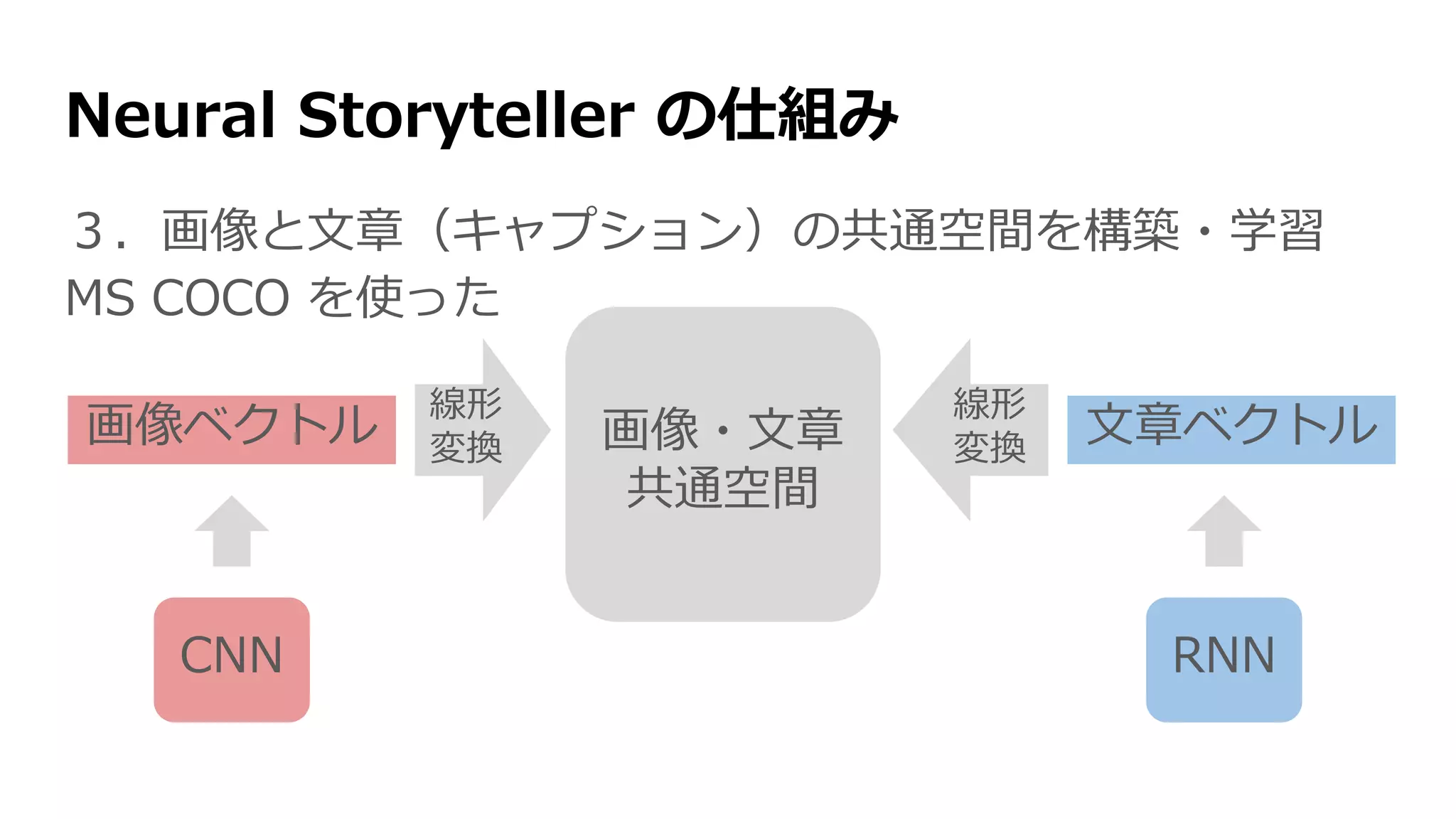
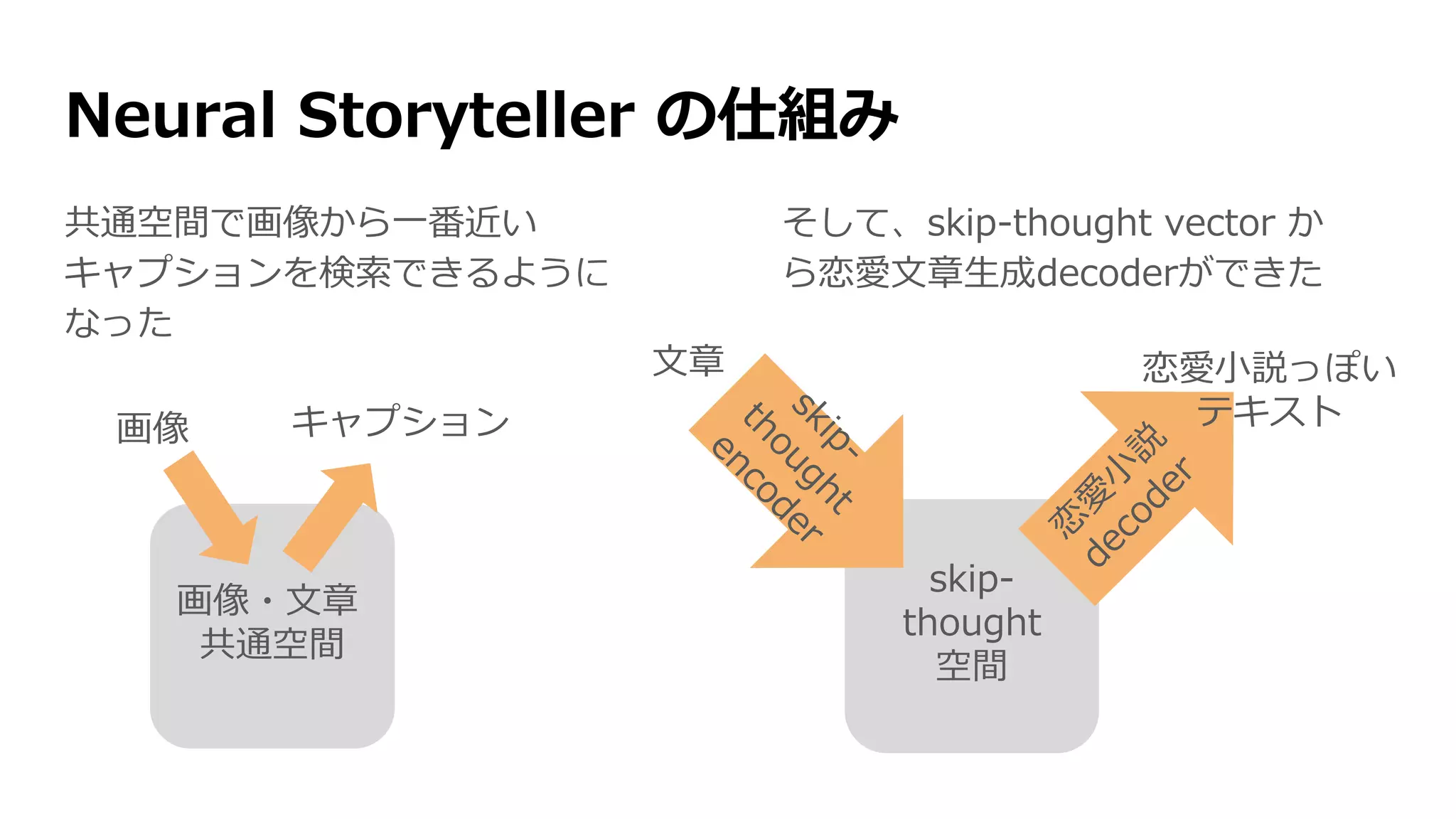
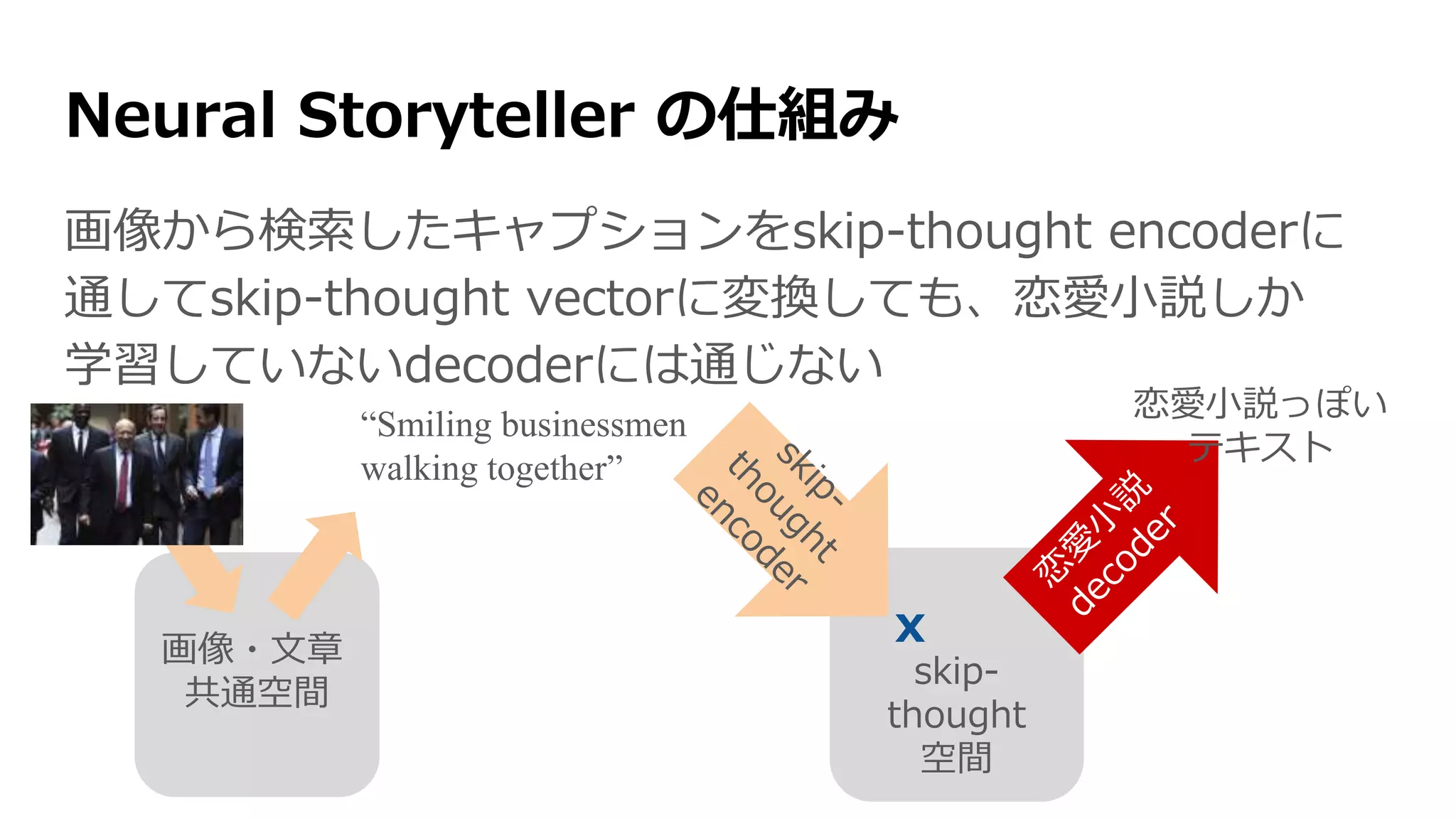
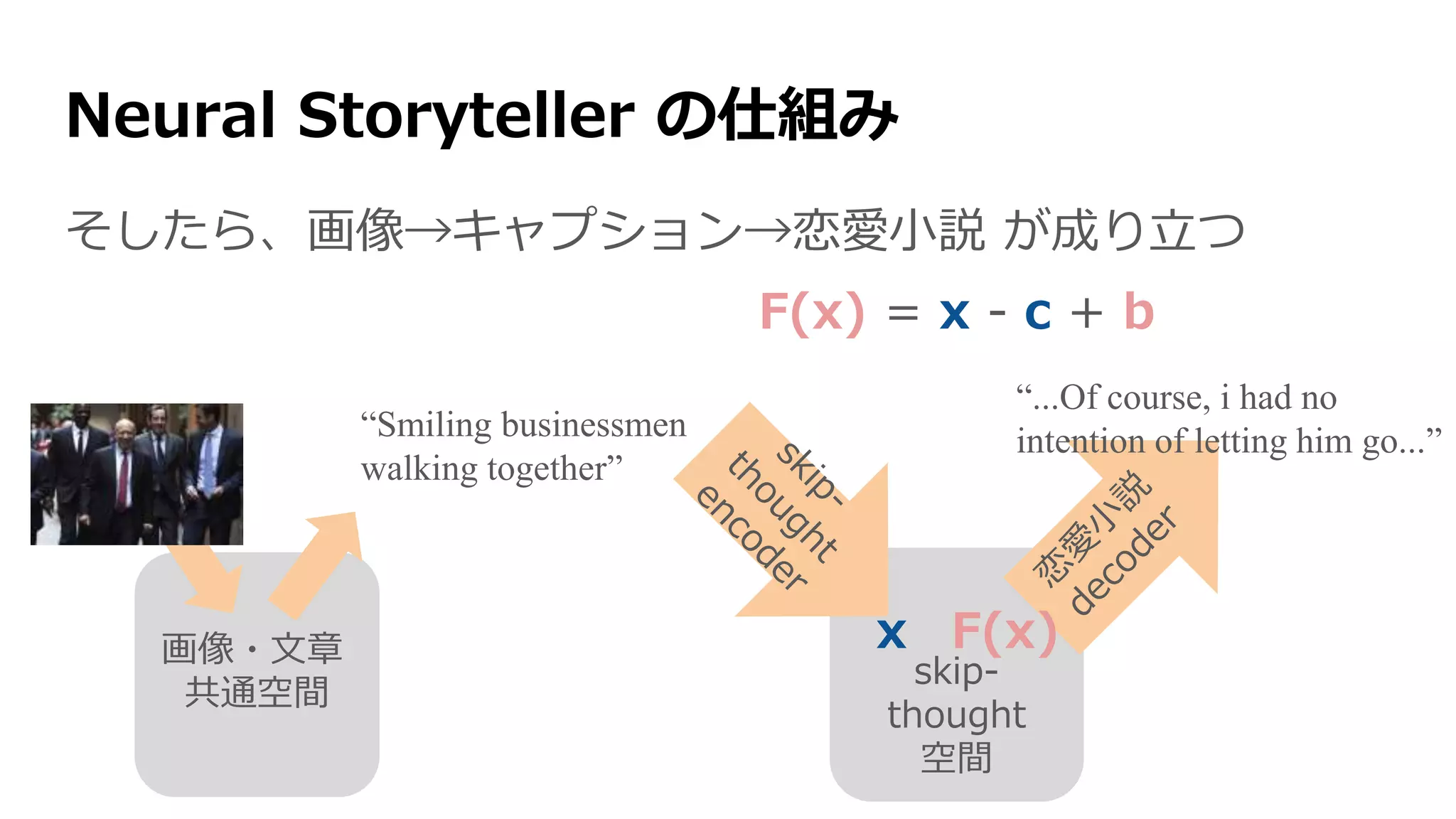
Neural Storyteller の仕組み
そしたら、画像→キャプション→恋愛小説が成り立つ
skip-
thought
空間
画像・文章
共通空間
x
F(x) = x - c + b
F(x)
“Smiling businessmen
walking together”
“...Of course, i had no
intention of letting him go...”
文献
• Y Bengio,R Ducharme, P Vincent, C Jauvin. 2003. A Neural Probabilistic Model. Journal of
Machine Learning Research 3 (2003) 1137-1155.
• J Firth. 1957. A synopsis of linguistic theory 1930-1955. In Studies in Linguistic Analysis
pp. 1-32
• A Frome, G Corrado, J Shlens, S Bengio, J Dean, M Ranzato, T Mikolov. 2013. DeViSE: A
Deep Visual-Semantic Embedding Model
• Z Harris. 1954. Distributional structure. Word, 10(23):146-162
• G Hinton, J McClelland, D Rumelhart. 1986. Distributed Representations. In Parallel
distributed processing: Explorations in the microstructure of cognition, Volume I. Chapter
3, pp. 77-109, Cambridge, MA: MIT Press.
• N Kalchbrenner, E Grefenstette, P Blunsom. A convolutional neural network for modelling
sentences. ACL, 2014.
115.
文献
• R Kiros,R Salakhutdinov, R Zemel. 2014. Unifying Visual-Semantic Embeddings with
Multimodal Neural Language Models.
• R Kiros, Y Zhu, R Salakhutdinov, R Zemel, A Torralba, R Urtasun, S Fidler. 2015. Skip-
Thought Vectors.
• Q Le, T Mikolov. Distributed representations of sentences and documents. ICML, 2014.
• H Lee, R Grosse, R Ranganath, A Ng. 2009. Convolutional Deep Belief Networks for
Scalable Unsupervised Learning of Hierarchical Representations.
• O Levy, Y Goldberg, I Dagan. 2014. Improving Distributional Similarity with Lessons
Learned from Word Embeddings.
• T Mikolov, K Chen, G Corrado, J Dean. 2013. Efficient Estimation of Word Representations
in Vector Space.
116.
文献
• M Norouzi,T Mikolov, S Bengio, Y Singer, J Shlens, A Frome, G Corrado, J Dean. 2013.
Zero-shot Learning by Convex Combination of Semantic Embeddings
• J Pennington, R Socher, C Manning. 2014. GloVe: Global Vectors for Word Representation.
• R Richens. 1956. Preprogramming for Mechanical Translation. Mechanical Translation,
vol.3, no.1, July 1956; pp. 20-25.
• X Rong. 2014. word2vec Parameter Learning Explained.
• R Socher, M Ganjoo, C Manning, A Ng. 2013. Zero-Shot Learning Through Cross-Modal
Transfer
• R Socher, A Perelygin, J Wu, J Chuang, C Manning, A Ng, C Potts. Recursive deep models
for semantic compositionality over a sentiment treebank. In EMNLP, 2013.
117.
文献
• I Sutskever,O Vinyals, Q Le. 2014. Sequence to Sequence Learning with Neural Networks.
• O Vinyals, A toshev, S Bengio, D Erhan. 2014. Show and Tell: A Neural Image Caption
Generator.
• W Zou. 2013. Bilingual Word Embeddings for Phrase-Based Machine Translation.
Editor's Notes
#9 Elman, Jeffrey L.; et al. (1996). "Preface". Rethinking Innateness: A Connectionist Perspective on Development (Neural Network Modeling and Connectionism). A Bradford Book. ISBN 978-0262550307. connectionism (a term introduced by Donald Hebb in 1940s, and the name we adopt here)





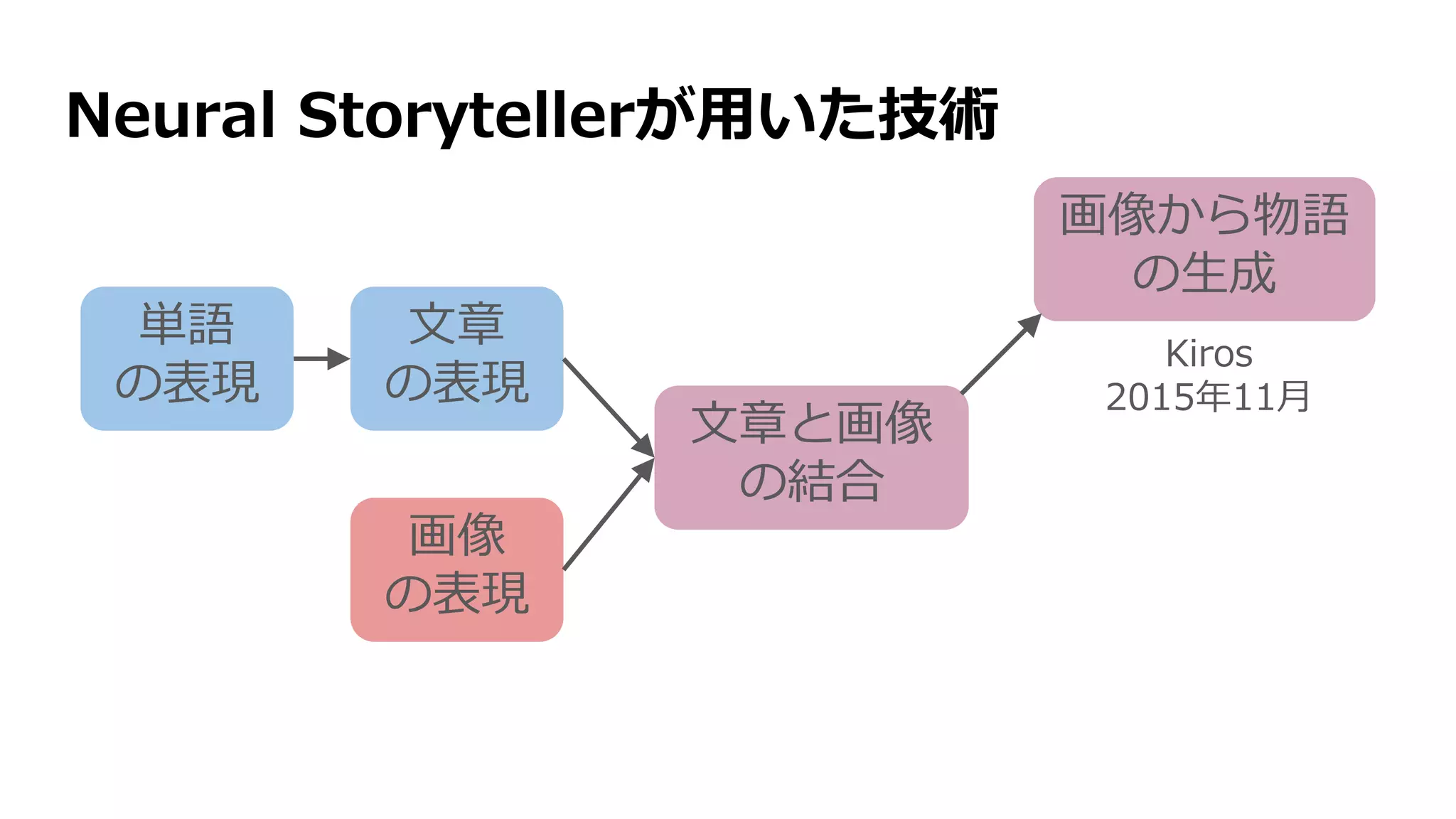
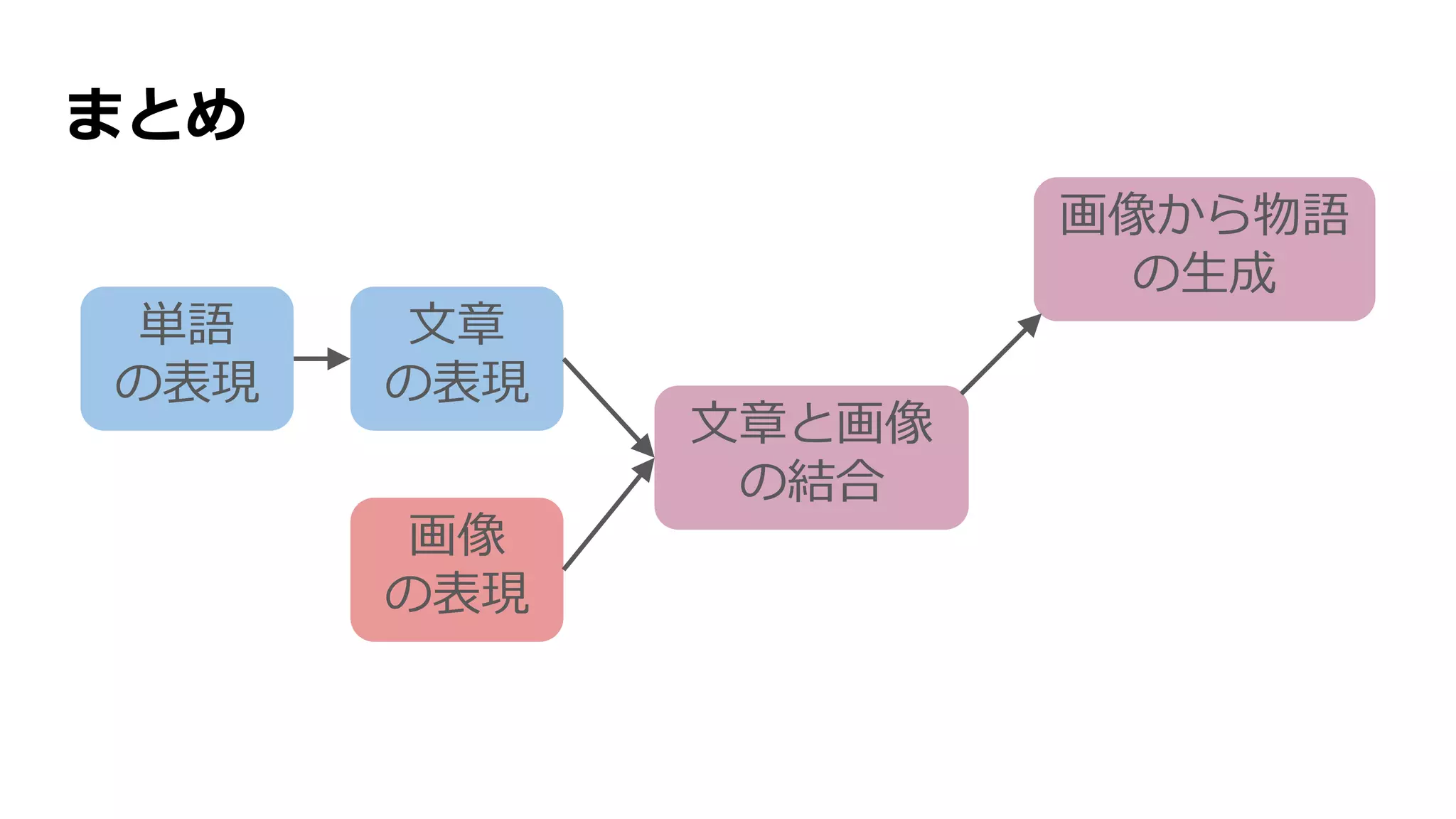
![Neural Storytellerで用いられている技術
単語
の表現
文章
の表現
画像
の表現
文章と画像
の結合
画像から物語
の生成
Kiros
2015年11月
ニューラルネットワーク(NN)が支える
[Mikolov+ 13] [Kiros+ 15]
[Kiros+ 14]
[Simonyan+ 14]](https://image.slidesharecdn.com/13-2-160308052302/75/slide-6-2048.jpg)

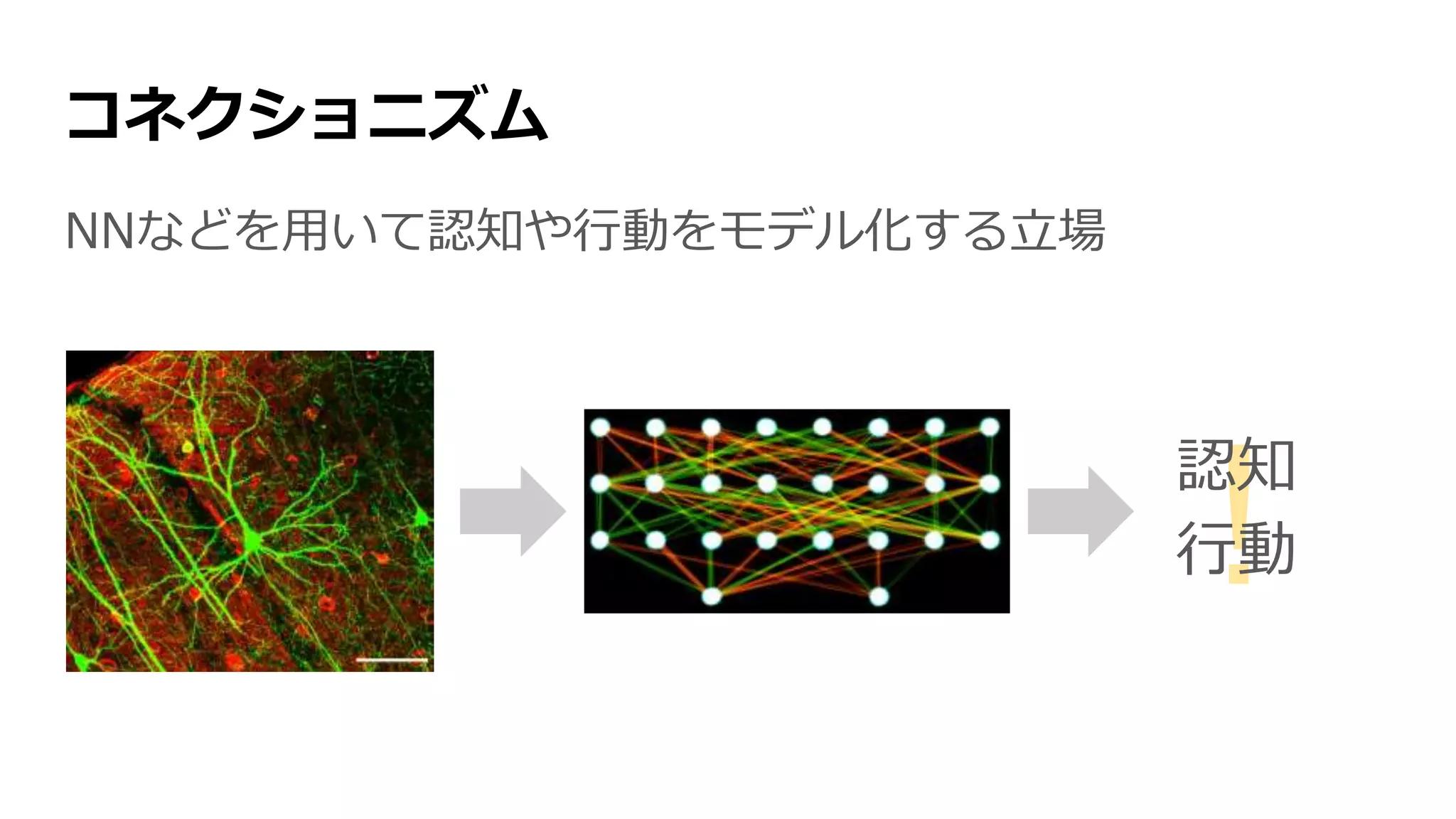
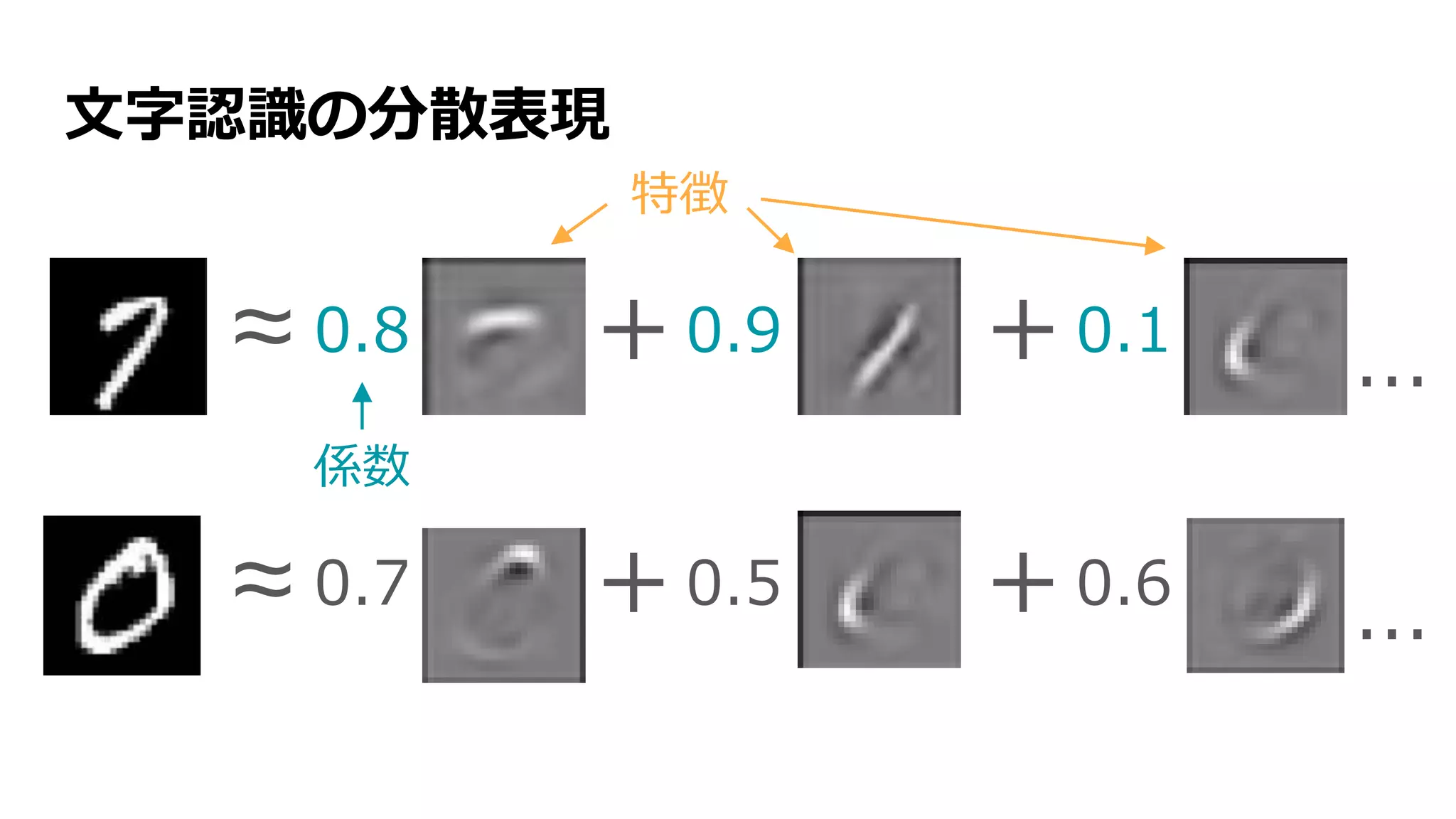
![分散表現 [Hinton+ 1986]
1986年、「コネクショニスト」の一人、Geoffrey Hintonが、
ニューロンがどう概念を表しているかを説明するため、
分散表現(distributed representation)を提唱
分散表現](https://image.slidesharecdn.com/13-2-160308052302/75/slide-9-2048.jpg)


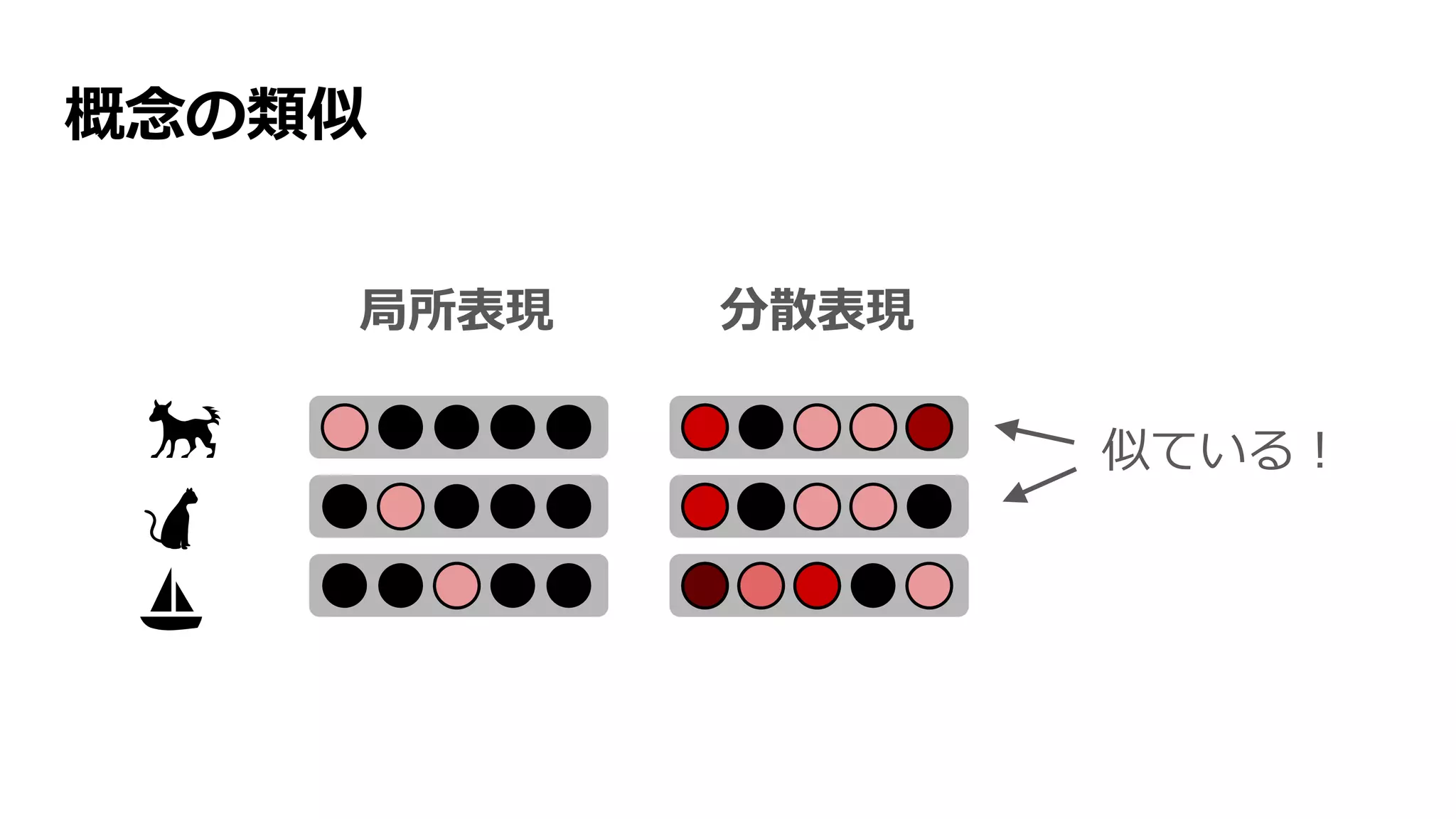
![局所表現
一つのニューロン(の発火)で一つの概念を表す
ベクトルで表すと one-hot vector
🐕
🐈
⛵
[1, 0, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 0, 1, 0, 0]
...
...
...](https://image.slidesharecdn.com/13-2-160308052302/75/slide-12-2048.jpg)
![分散表現
複数のニューロン(の発火)で一つの概念を表す
🐕
🐈
⛵
[0.5, 0.0, 1.0, 1.0, 0.3]
[0.5, 0.0, 1.0, 1.0, 0.0]
[0.2, 0.9, 0.5, 0.0, 1.0]
...
...
...](https://image.slidesharecdn.com/13-2-160308052302/75/slide-13-2048.jpg)

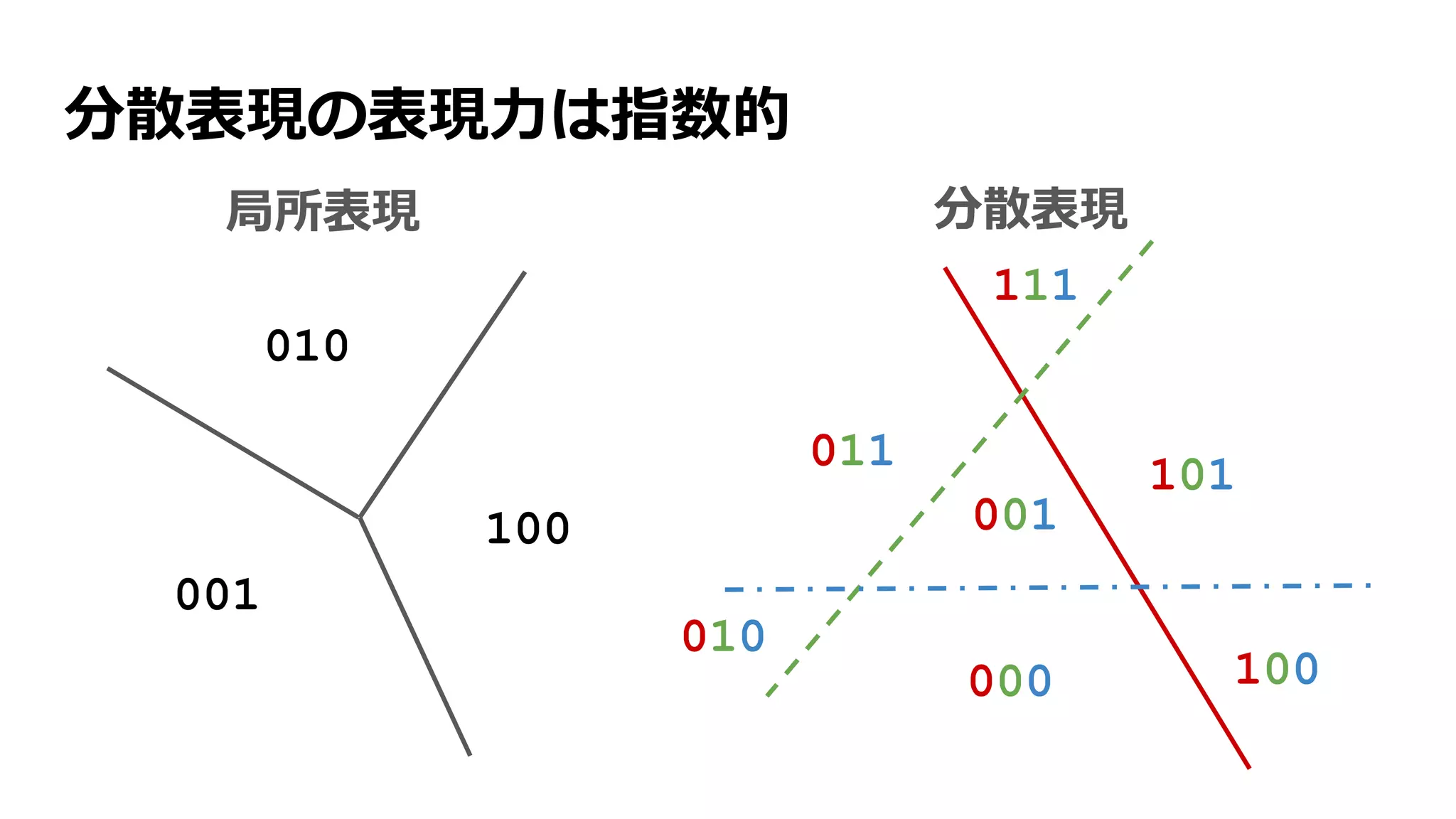
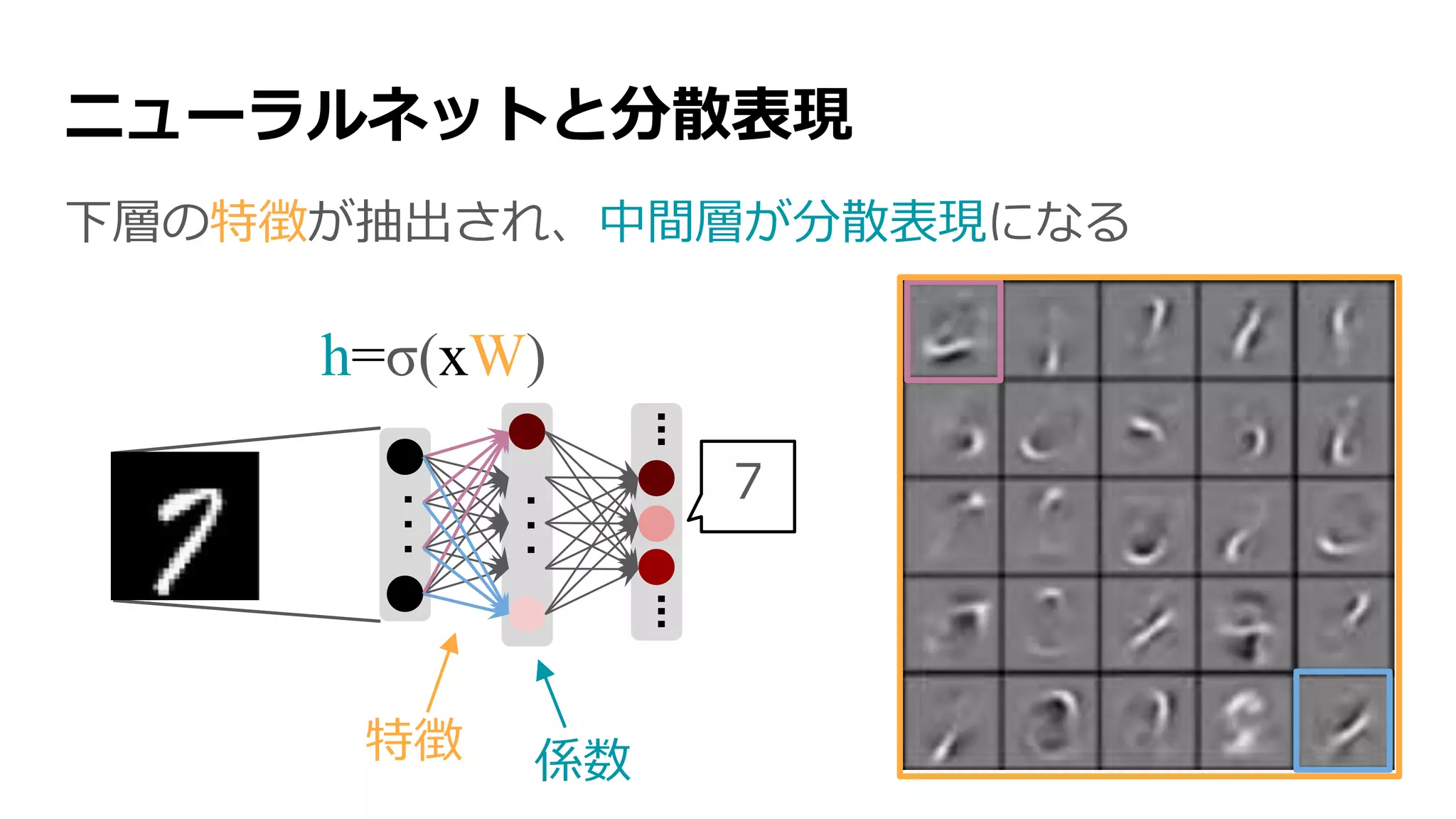
![ディープニューラルネットワーク(DNN)
中間層を重ねて、さらに抽象的な特徴を抽出する
[Lee+ 2009] より](https://image.slidesharecdn.com/13-2-160308052302/75/slide-19-2048.jpg)








![単語の局所表現
これじゃ単語の意味がまったく分からない...
→ 単語の意味を捉えるベクトルが欲しい
[1, 0, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 0, 1, 0, 0]
...
ねこ
いぬ
ひと...](https://image.slidesharecdn.com/13-2-160308052302/75/slide-30-2048.jpg)
![分布仮説 [Harris 1954, Firth 1957]
“You shall know a word by the company it keeps”
- J. R. Firth
似ている文脈を持つ言葉は似ている意味を持つ
現代の統計的自然言語処理で画期的な着想](https://image.slidesharecdn.com/13-2-160308052302/75/slide-31-2048.jpg)







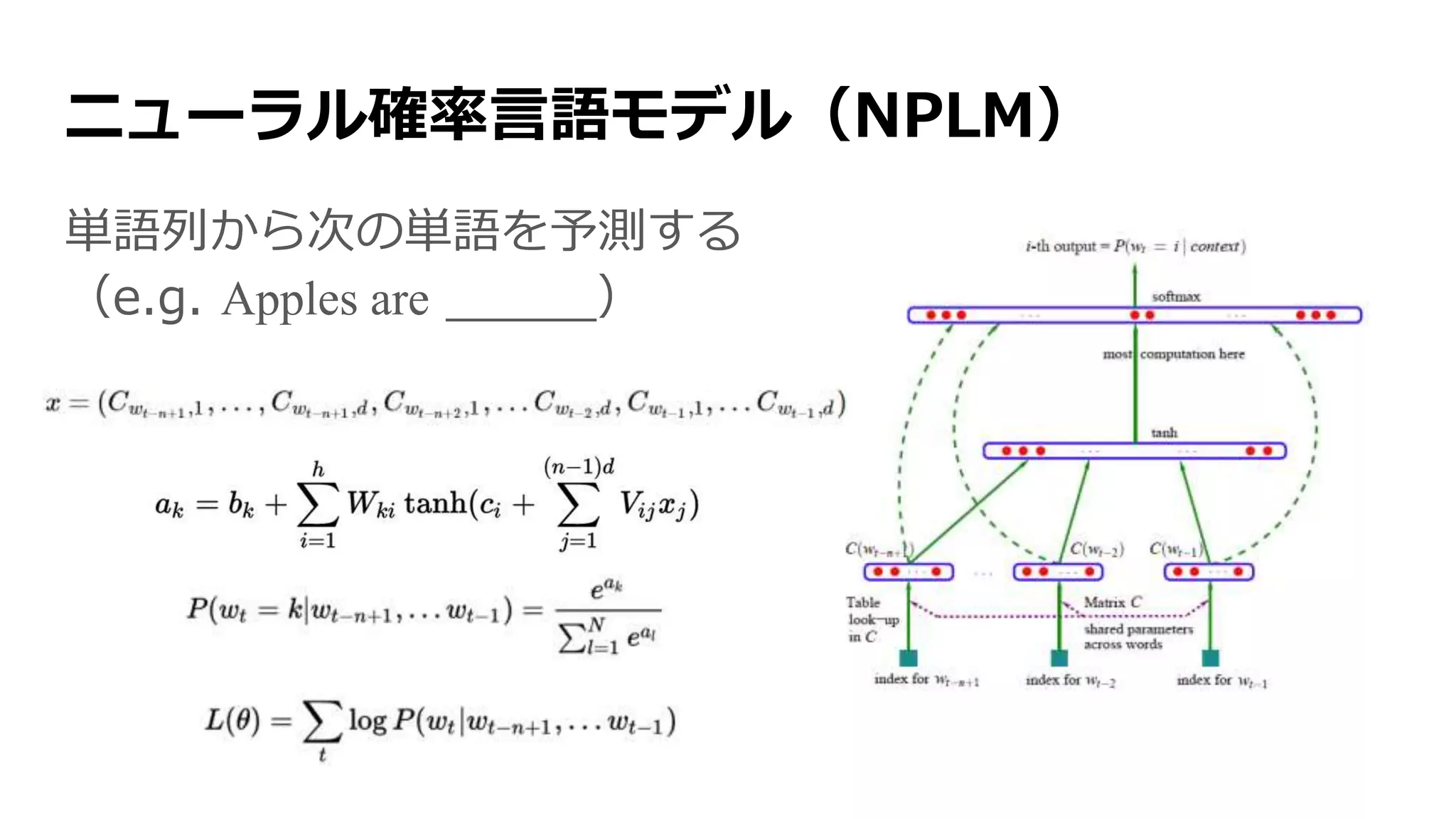
![ニューラル確率言語モデル [Bengio+ 2003]
NNでつくった言語モデル
→ 言語モデルとは何か?](https://image.slidesharecdn.com/13-2-160308052302/75/slide-47-2048.jpg)






![word2vec [Mikolov+ 2013]
CBOW(連続 bag-of-words)モデル
• 文脈から単語を予測する
• 小規模なデータセットに対して性能がよい
skip-gramモデル
• 単語から文脈を予測する
• 大規模なデータセットにて用いられる
skip-gramは性能がよくて速いので人気](https://image.slidesharecdn.com/13-2-160308052302/75/slide-59-2048.jpg)






![単語から文章へ
文章の表現学習をする手法:
bag-of-words
convolutional NN [Kalchbrenner+ 2014]
recursive NN [Socher+ 2013]
recurrent NN
doc2vec [Le+ 2014]
skip-thought vectors [Kiros+ 2015] (RNNを使う)
教師なし
表現学習
主に教師あり
表現学習
学習の必要なし](https://image.slidesharecdn.com/13-2-160308052302/75/slide-69-2048.jpg)

![Skip-Thought Vectors [Kiros+ 2015]
skip-gram の文章版(文章→前後の文章)
... I got back home. I could see the cat on the steps. This was strange. …
encoder RNNが文章の単語ベクトル
を一つずつ読み込んでいく
内部状態を文章のベクトルとして使う
2つの decoder RNNがそのベクトルか
ら前後の文章を生成](https://image.slidesharecdn.com/13-2-160308052302/75/slide-71-2048.jpg)





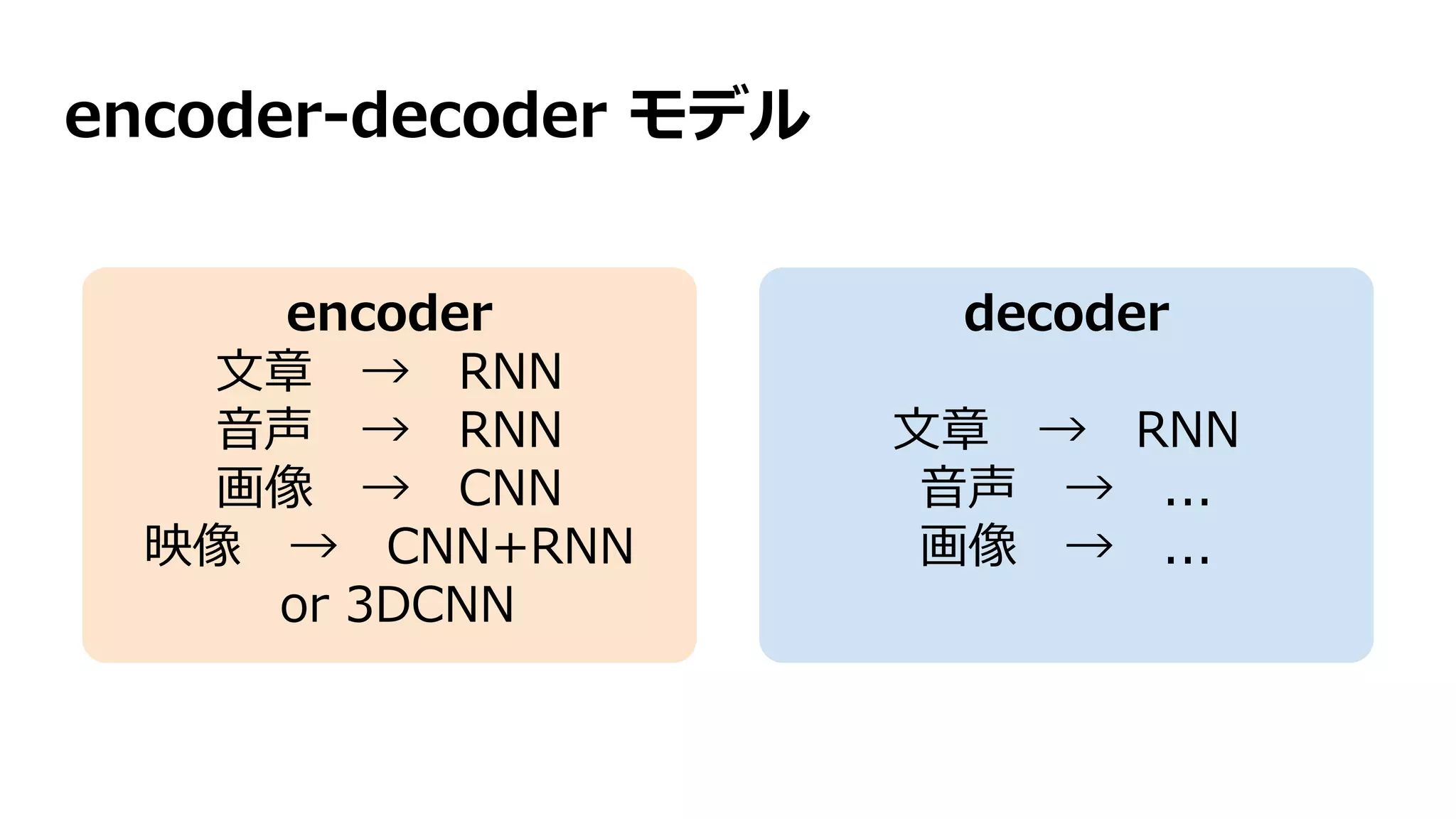
![seq2seq 機械翻訳 [Sutskever+ 2014]
シンプルな構造にしては精度の高い結果を出した
encoder RNN は 言語Aの文章をベクトル化し、
decoder RNN がそのベクトルから言語Bの文章を生成する
文章ベクトル](https://image.slidesharecdn.com/13-2-160308052302/75/slide-79-2048.jpg)


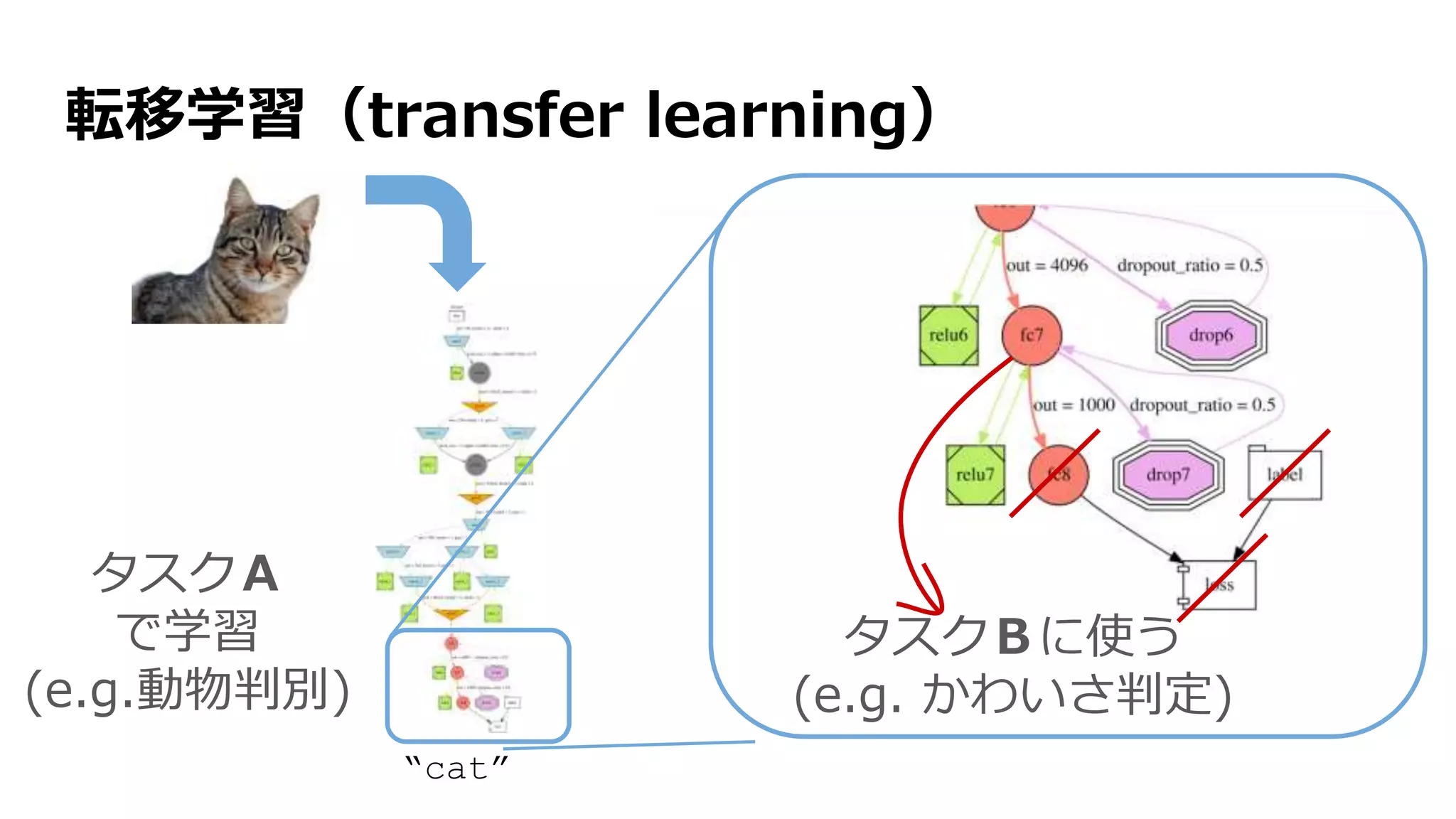
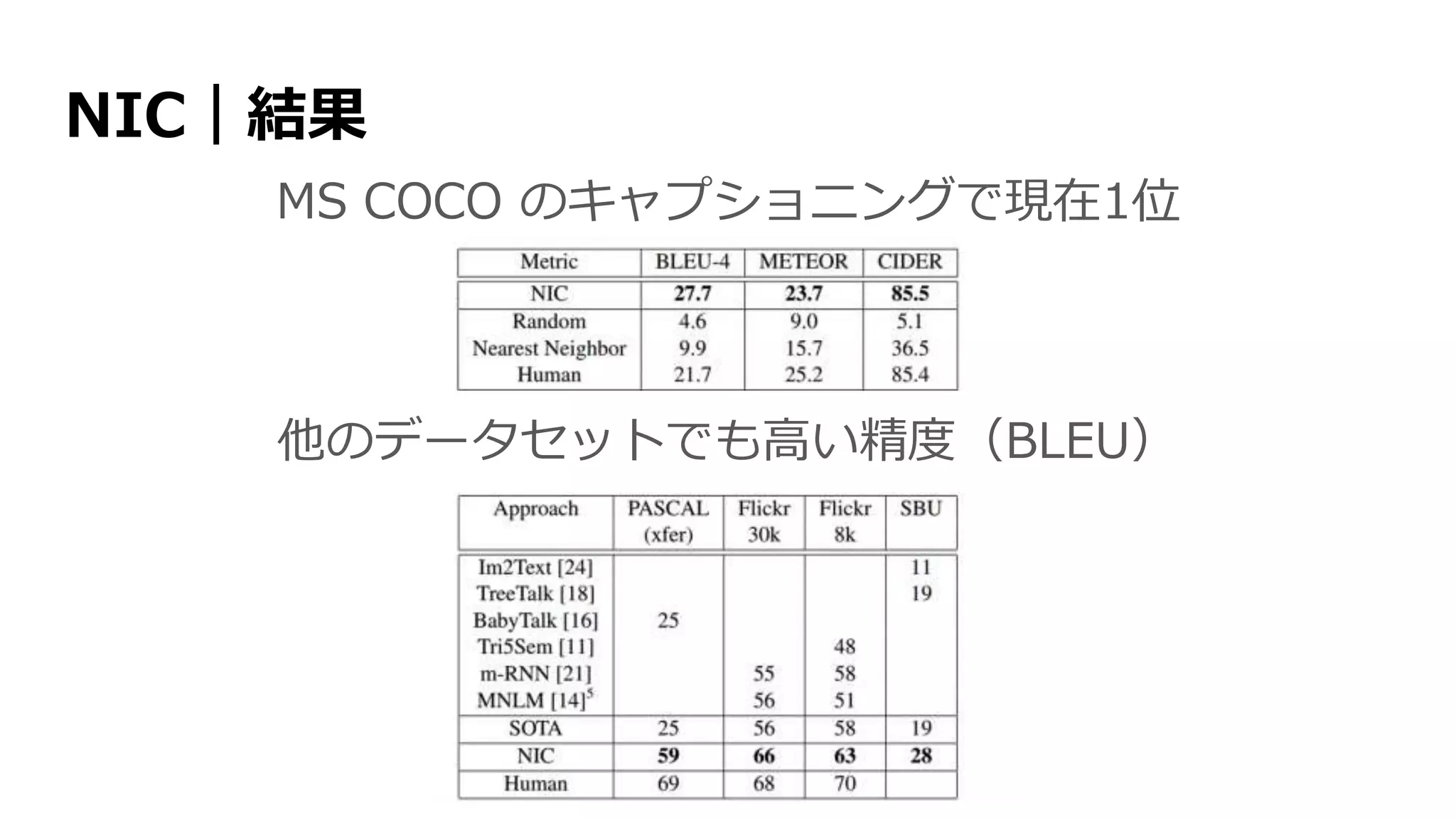
![Show and Tell: NIC [Vinyals+ 2015]
画像から文章への「翻訳」](https://image.slidesharecdn.com/13-2-160308052302/75/slide-83-2048.jpg)



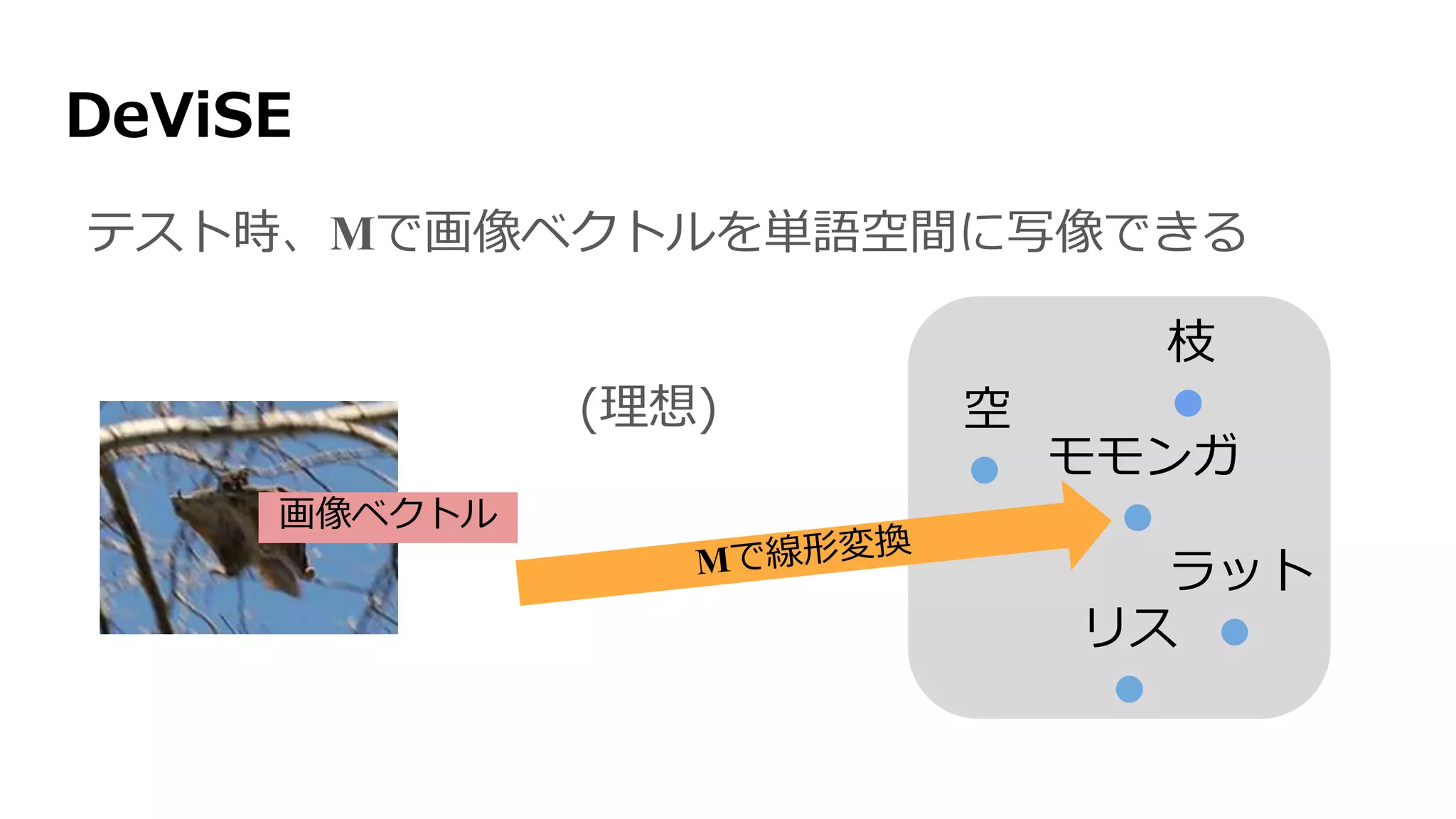
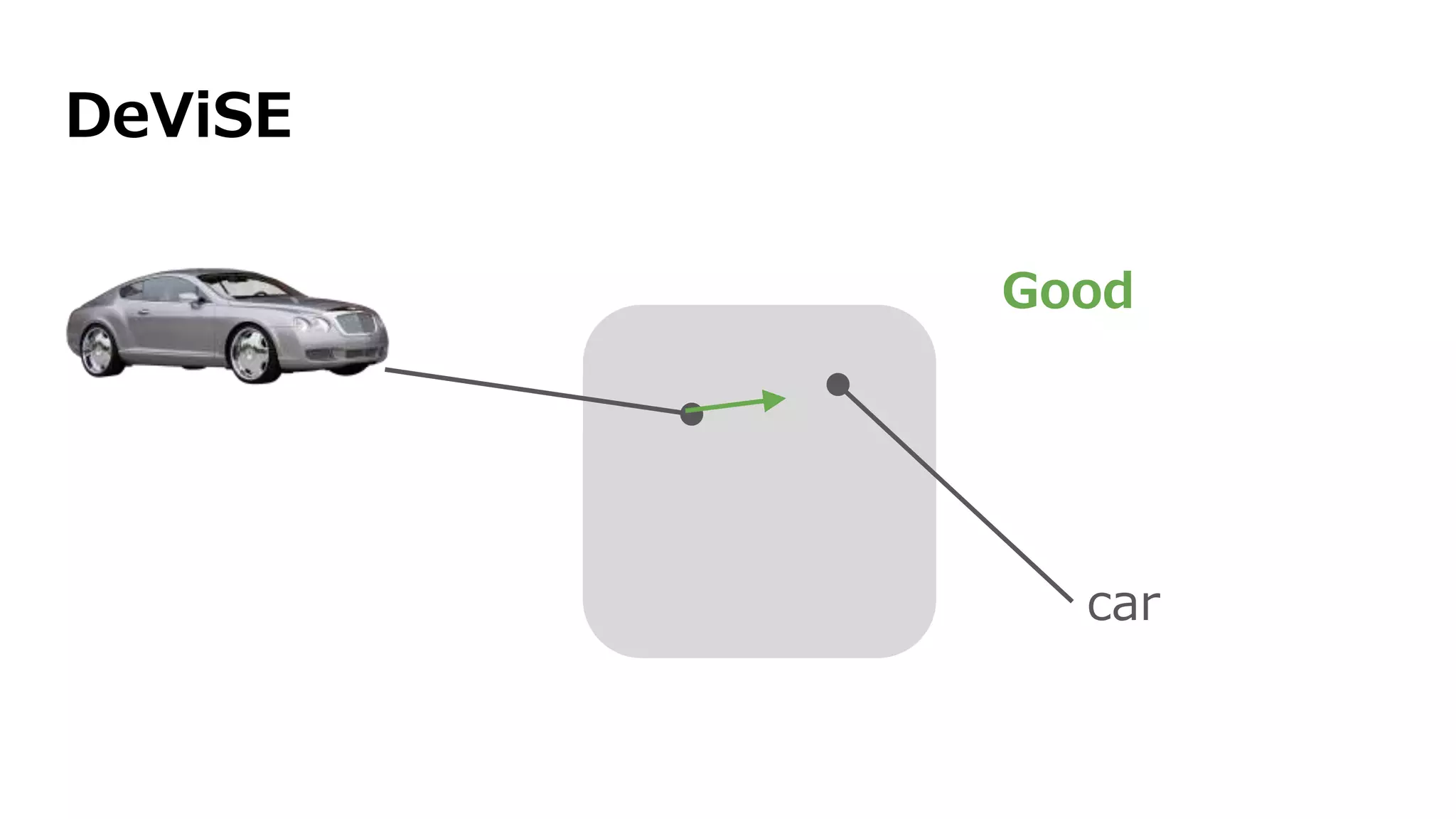
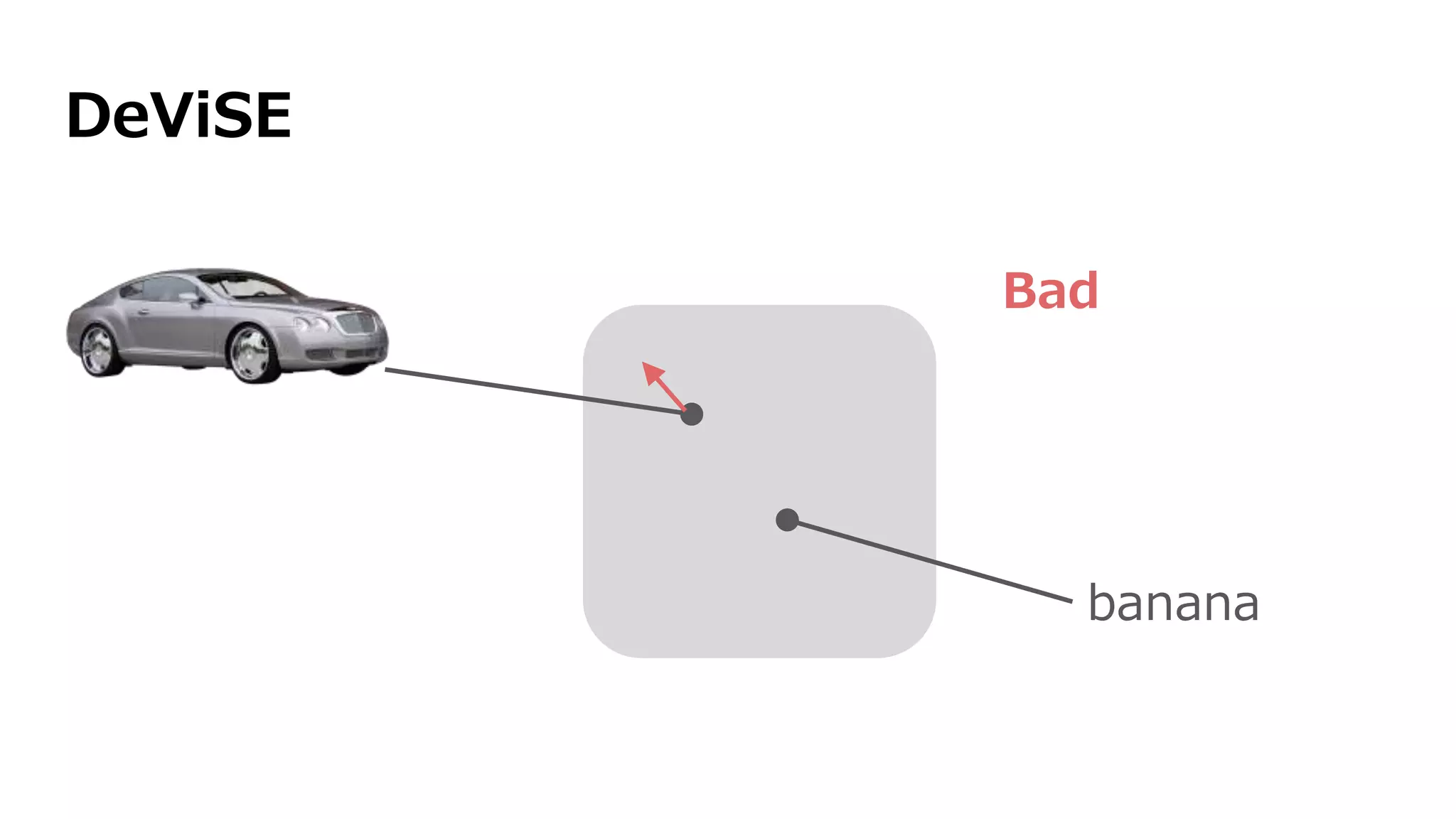
![DeViSE [Frome+ 2013]
空
リス
モモンガ
枝
ラット
画像ベクトル
画像ベクトル
学習時、Mを学習](https://image.slidesharecdn.com/13-2-160308052302/75/slide-88-2048.jpg)






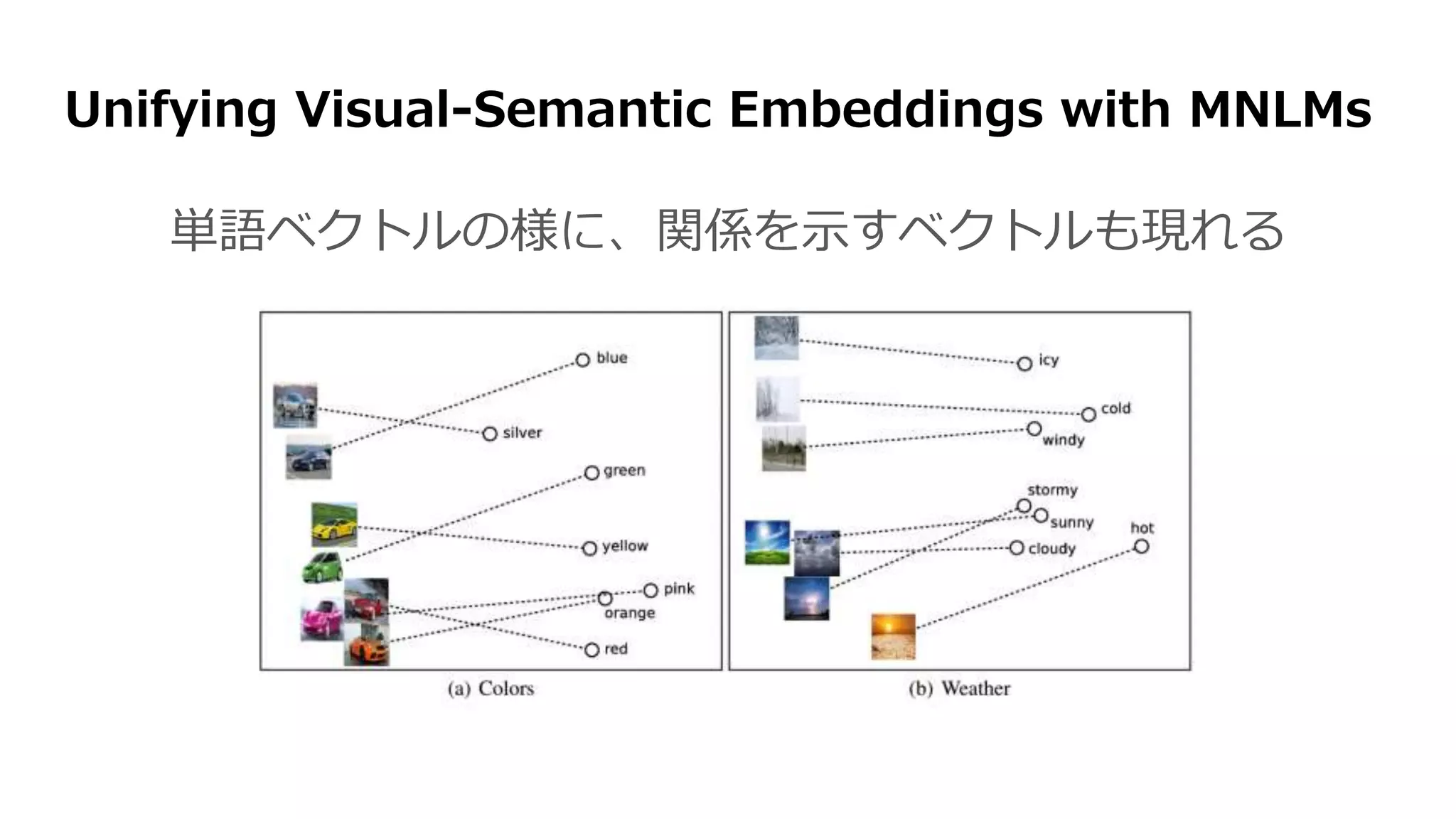
![Unifying Visual-Semantic Embeddings with Multimodal Neural
Language Models [Kiros 2014]
DeViseと似ている仕組み
言語モデル
(文章生成)](https://image.slidesharecdn.com/13-2-160308052302/75/slide-98-2048.jpg)