Download to read offline








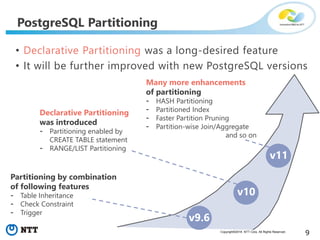

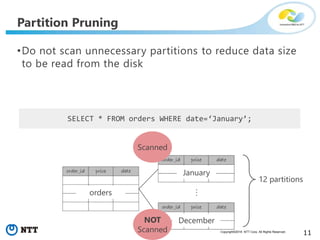
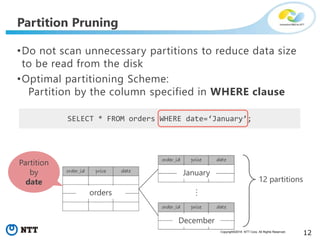
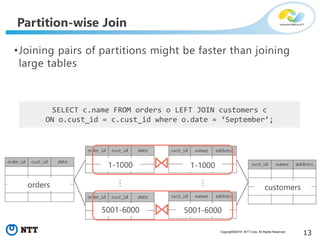






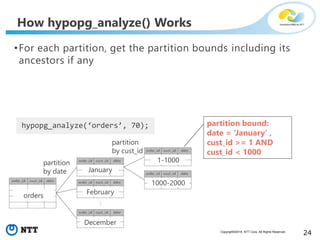
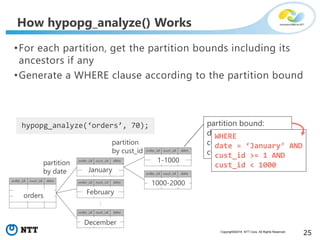
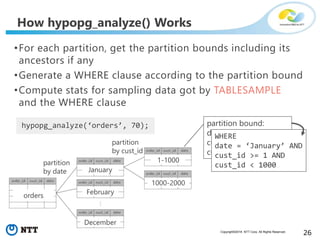

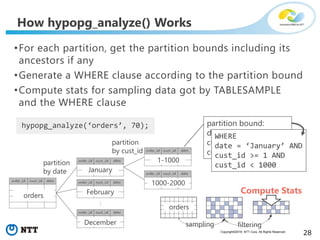
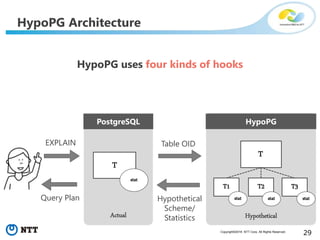
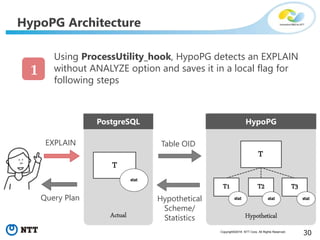
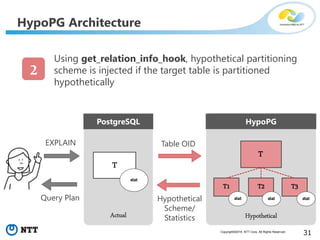
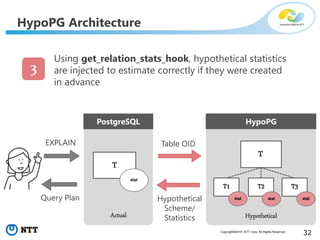
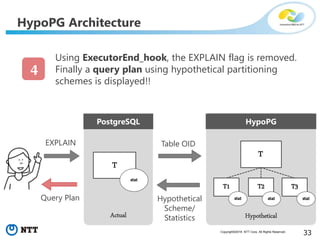








The document discusses hypothetical partitioning, which allows users to define and test different partitioning schemes on tables without actually partitioning them. It introduces HypoPG, an open source tool that enables hypothetical partitioning in PostgreSQL. Key points include: - HypoPG 2 will support defining and testing hypothetical partitioning schemes to help with partitioning design. - It allows examining query plans and costs as if different partitioning strategies were applied, without modifying real tables. - This helps users quickly try different schemes to optimize for queries involving partitioning, pruning, joins, and aggregation. - Future work includes better PostgreSQL integration and an automated advisor for partitioning design.















































