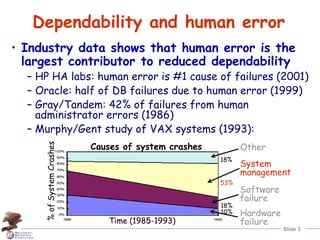
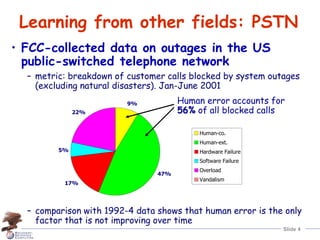
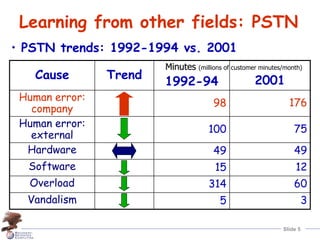
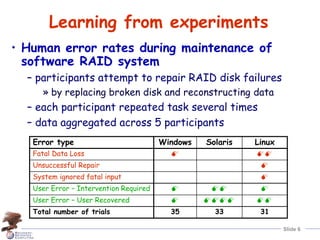
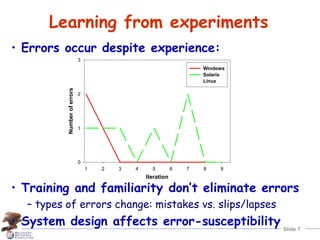
Human error is the largest contributor to reduced system dependability, according to industry data. A theory of human error categorizes errors as slips, lapses, or mistakes occurring during planning, storage, or execution of tasks. Major systems accidents are often caused by an accumulation of latent human errors. Addressing human error requires making systems more error-tolerant through approaches like providing "undo" mechanisms to allow operators to safely detect, correct, and learn from errors.