Download to read offline






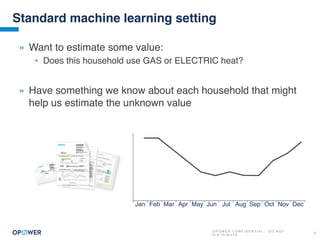

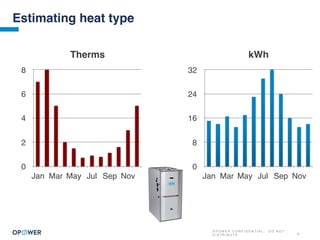
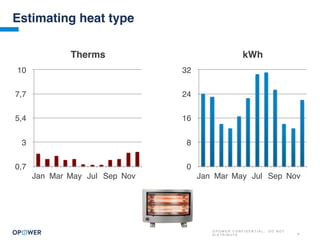
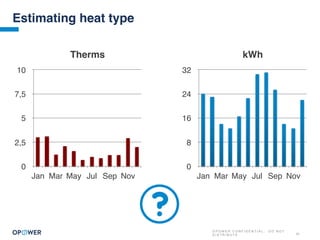
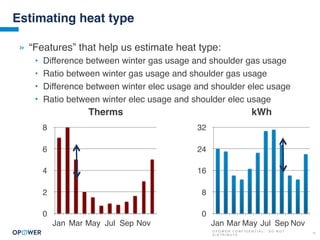
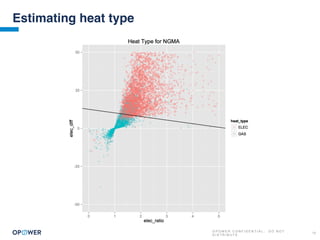


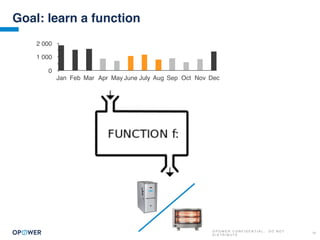
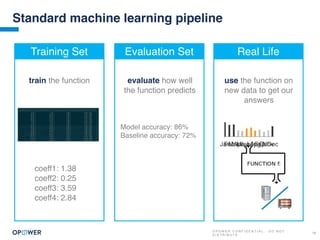

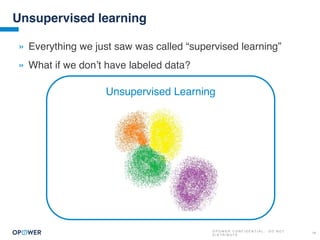

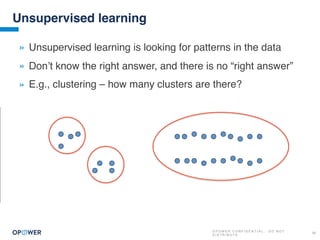
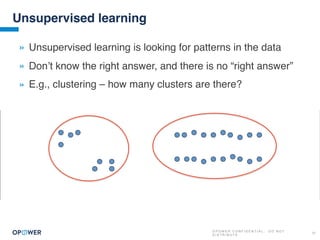
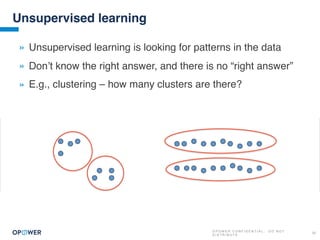
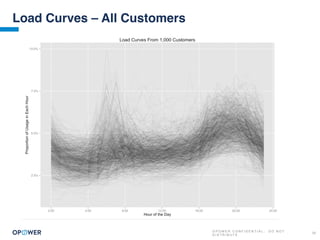
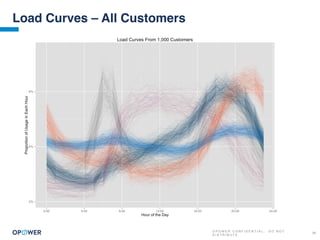
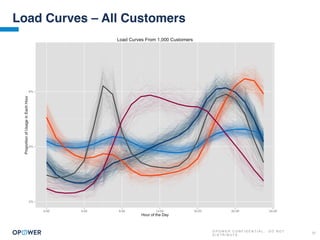
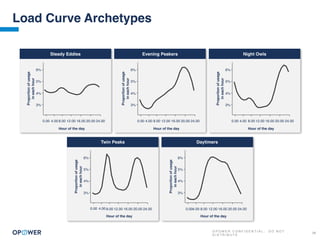
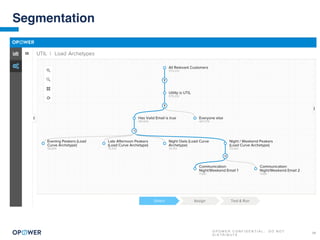

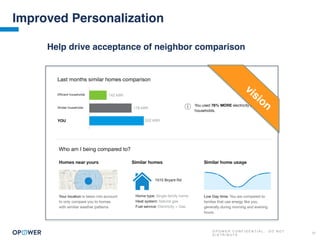




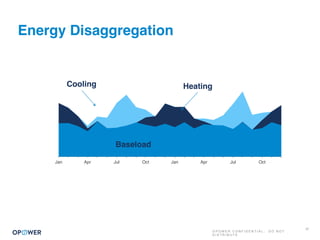
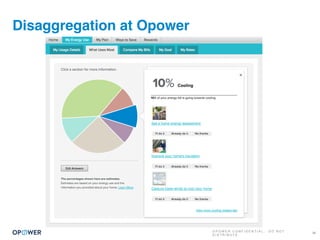

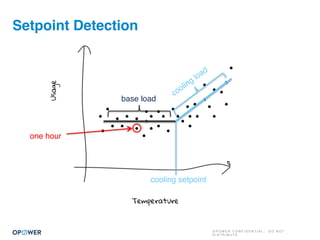
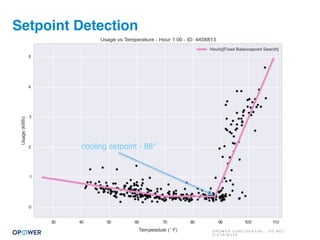
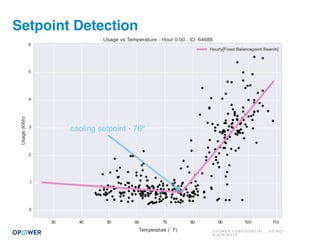
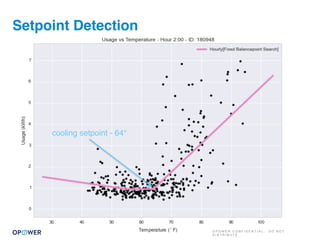
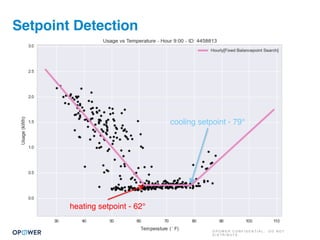
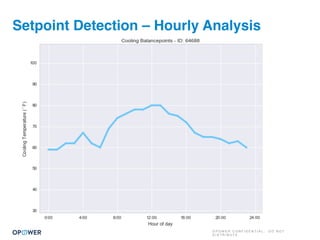
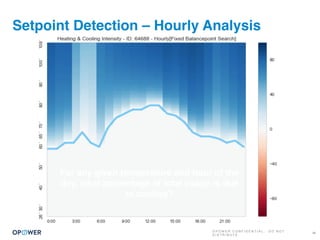
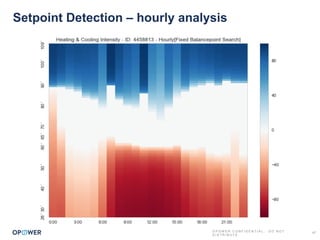
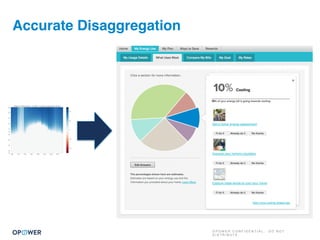

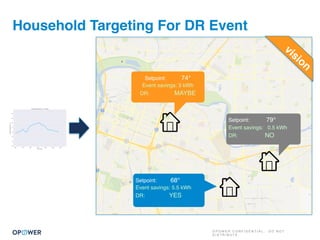
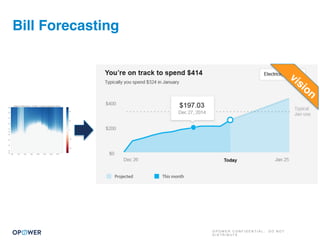


The document discusses machine learning and how it can be applied by a utility company. It explains how machine learning involves using algorithms to find patterns in data to help estimate unknown values or predict future usage. Specific applications discussed include estimating a home's heating type from usage data, creating customer segmentation profiles based on load curve patterns, and using disaggregated load data to estimate customer setpoints for heating and cooling. The goal is to apply these techniques to improve customer personalization, targeting, and participation in utility programs.






































































