Downloaded 10 times







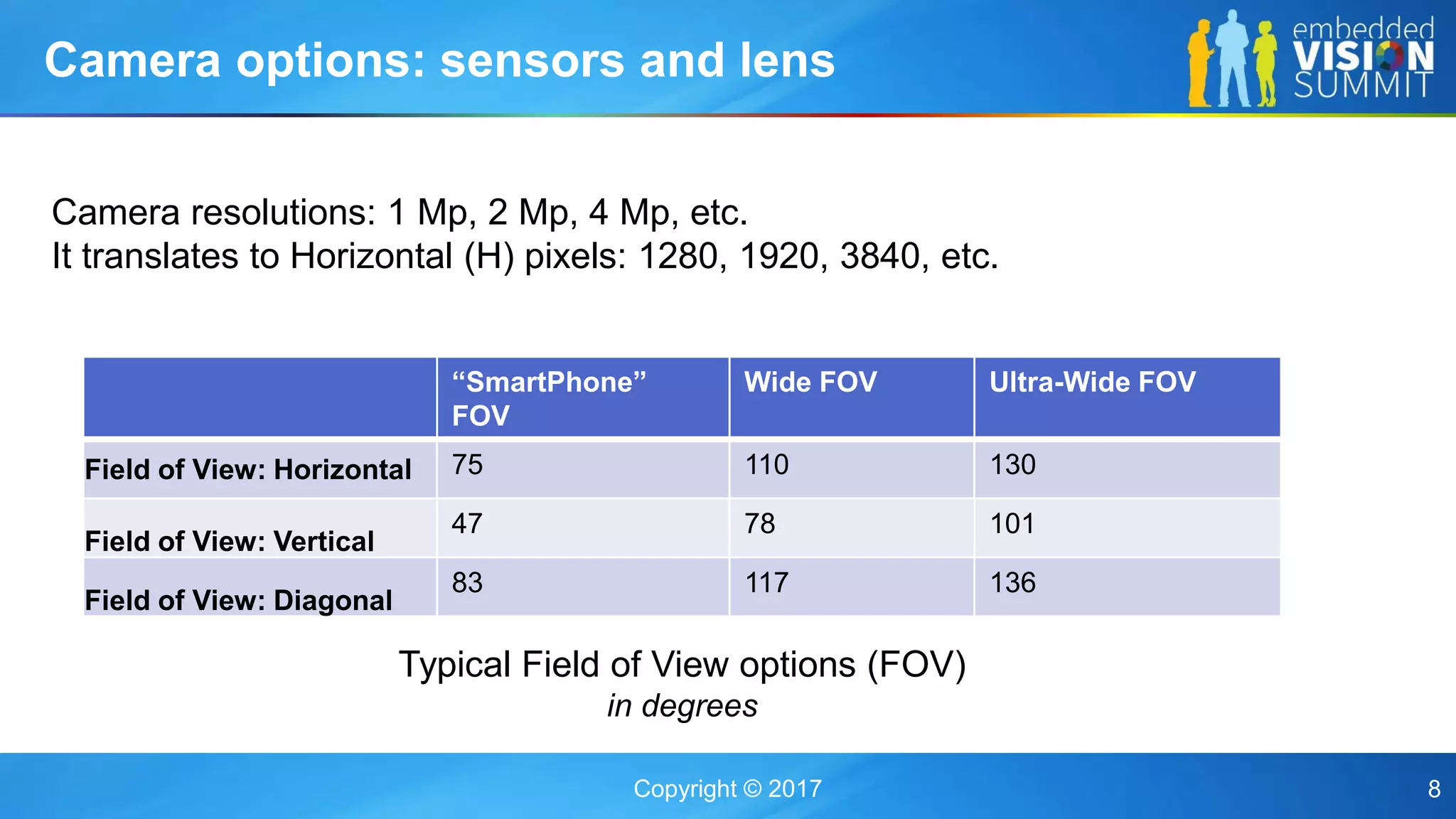
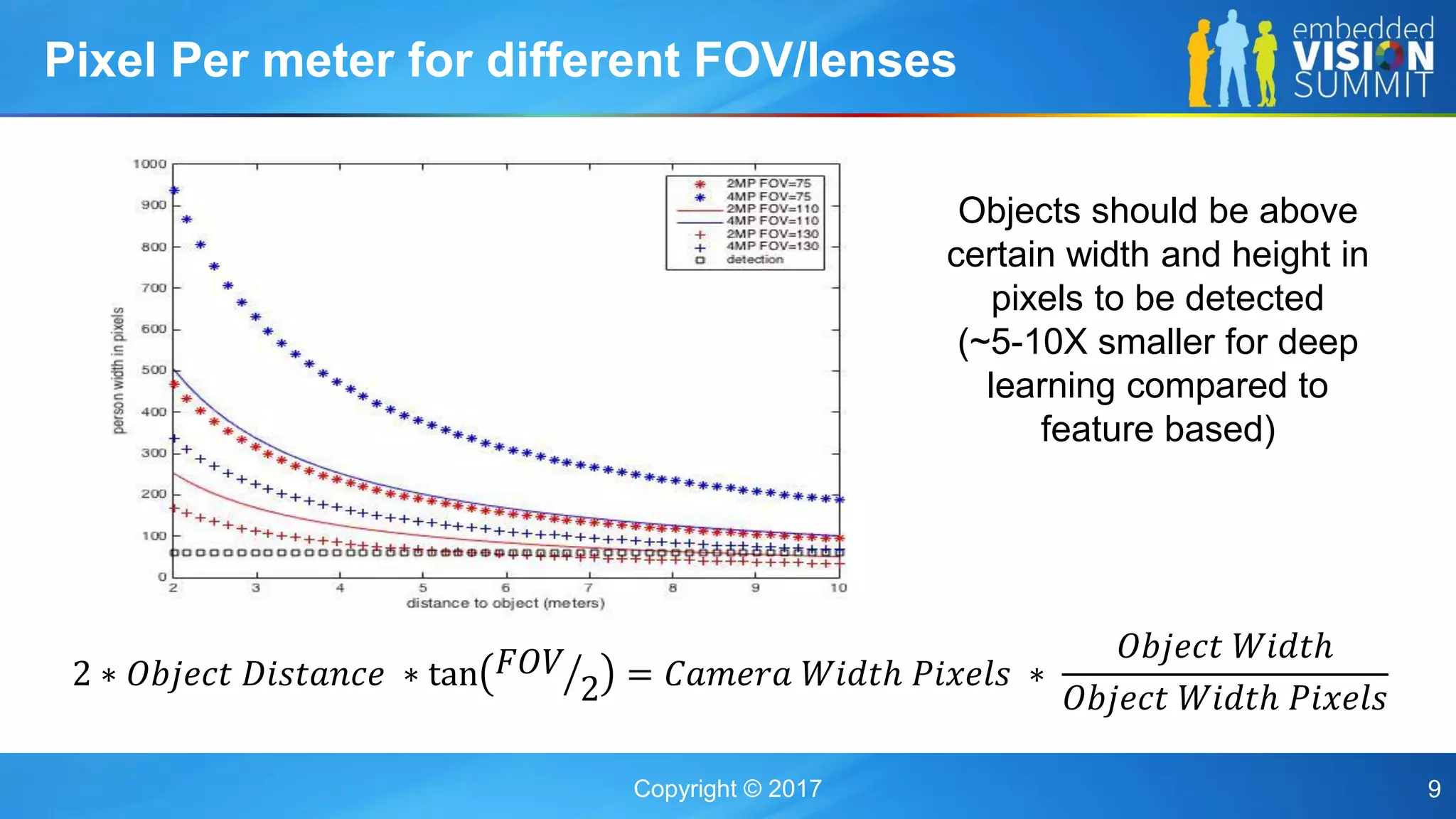

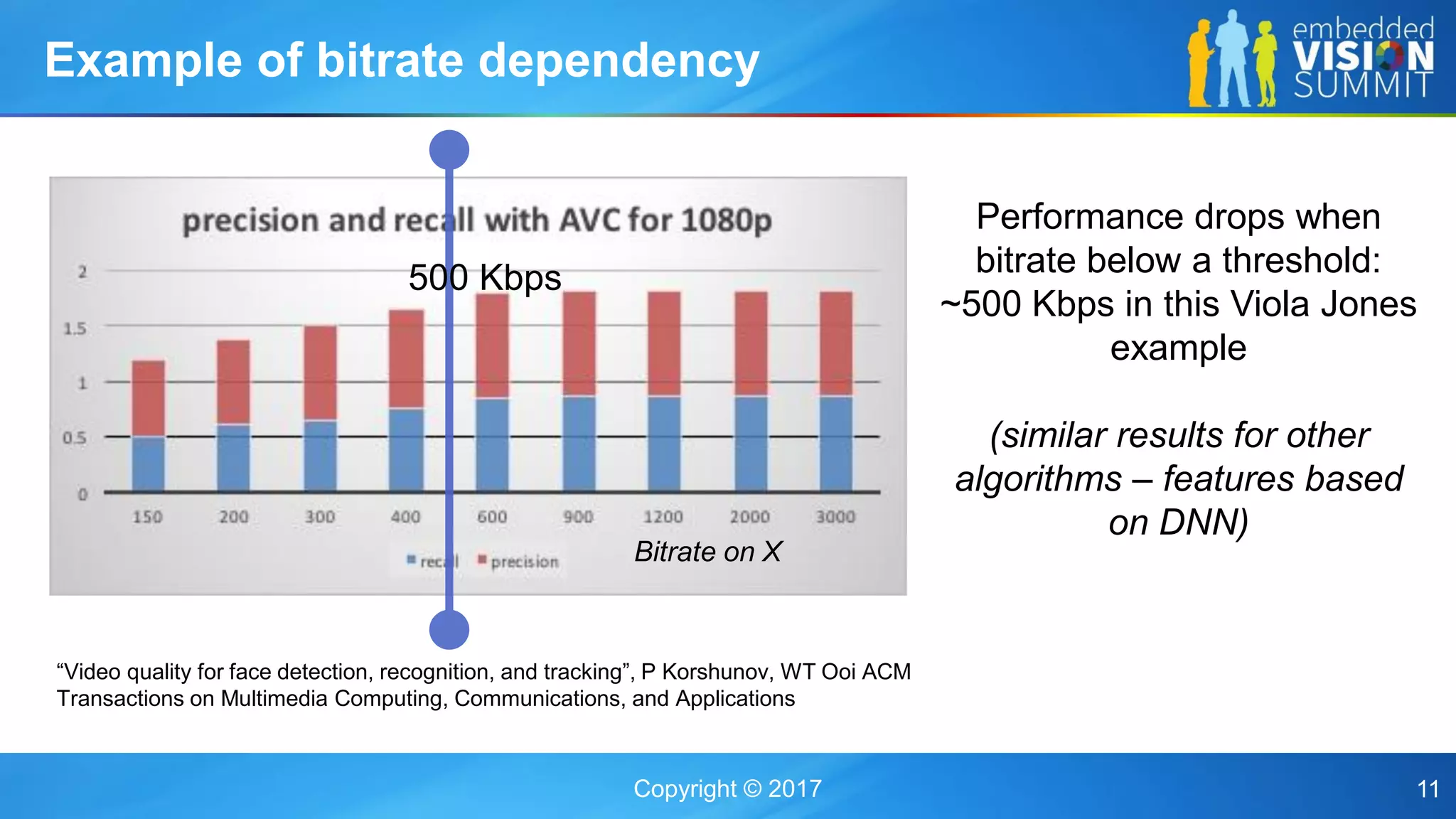
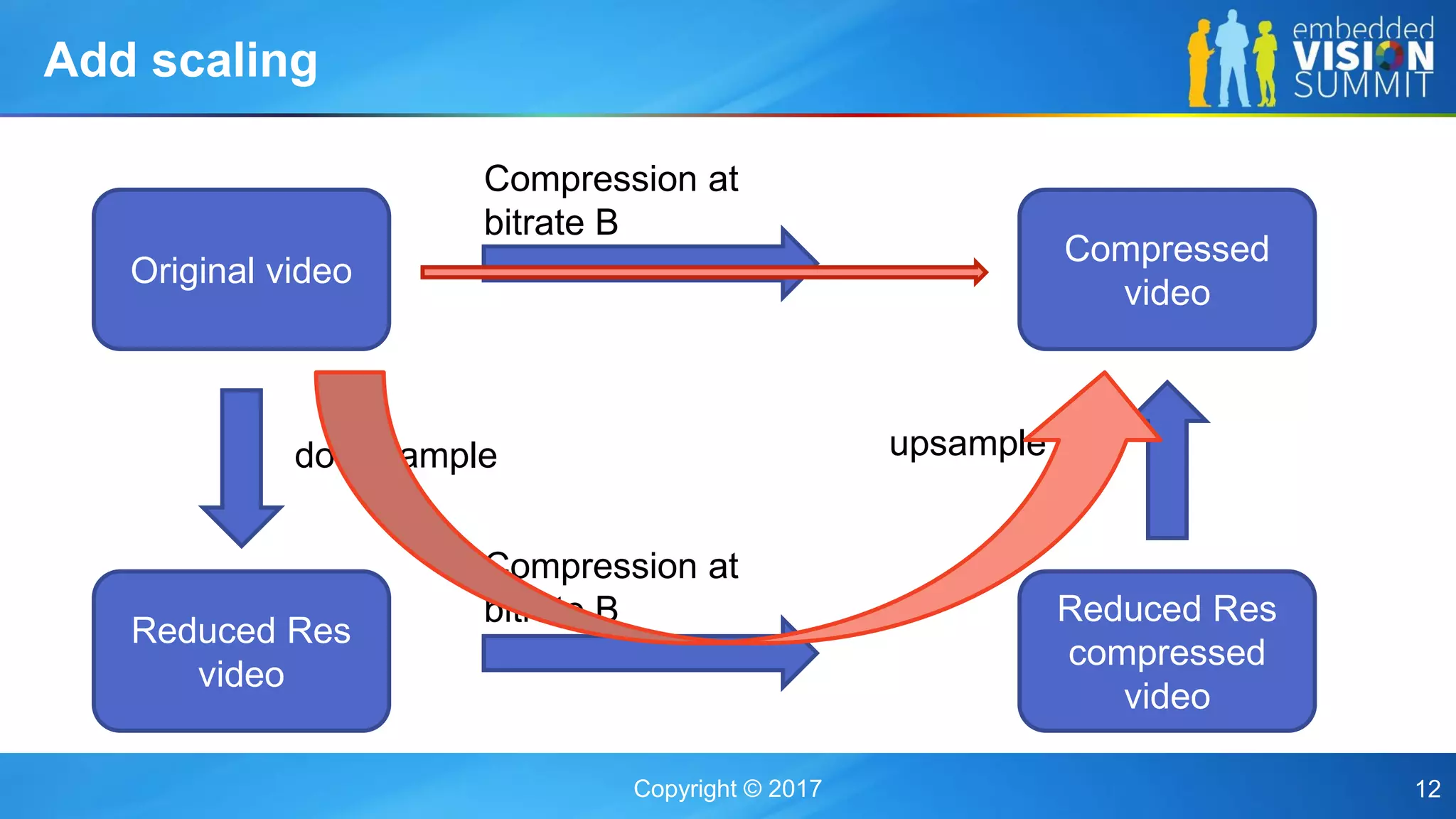






The document discusses the influence of image sensor and video compression parameters on computer vision algorithms, particularly in the context of object detection accuracy. It covers various algorithms, their performance under different conditions, and strategies for improving detection through better model training and feedback loops. Key points include the significance of camera specifications, compression impact on performance, and the importance of suitable resolution and bitrate for effective recognition tasks.



































































