Download as PDF, PPTX












































![SPARQL Extension with QoS
• QoS requirements can be described as part of the SPARQL
query
SELECT ?drug ?keggUrl ?chebiImage
WHERE {
?drug rdf:type drugbank:drugs .
QOSREQ[ qs:ResponseTime < 10 , qs:SizeLimit > 10000]
?drug drugbank:keggCompoundId ?keggDrug .
?keggDrug bio2rdf:u r l ?keggUrl .
{
?drug drugbank:genericName ?drugBankName .
?chebiDrug purl:title ?drugBankName .
}
QOSREQ[ qs:DatasetDescription = 'VoID' ,
qs:MeanUpTime > 80 ]
?chebiDrug chebi:image ?chebiImage . }
30 28/10/2014](https://image.slidesharecdn.com/odbase2014withoutbackup-141028084310-conversion-gate01/75/How-good-is-your-SPARQL-endpoint-A-QoS-Aware-SPARQL-Endpoint-Monitoring-and-Data-Source-Selection-Mechanism-for-Federated-SPARQL-Queries-67-2048.jpg)
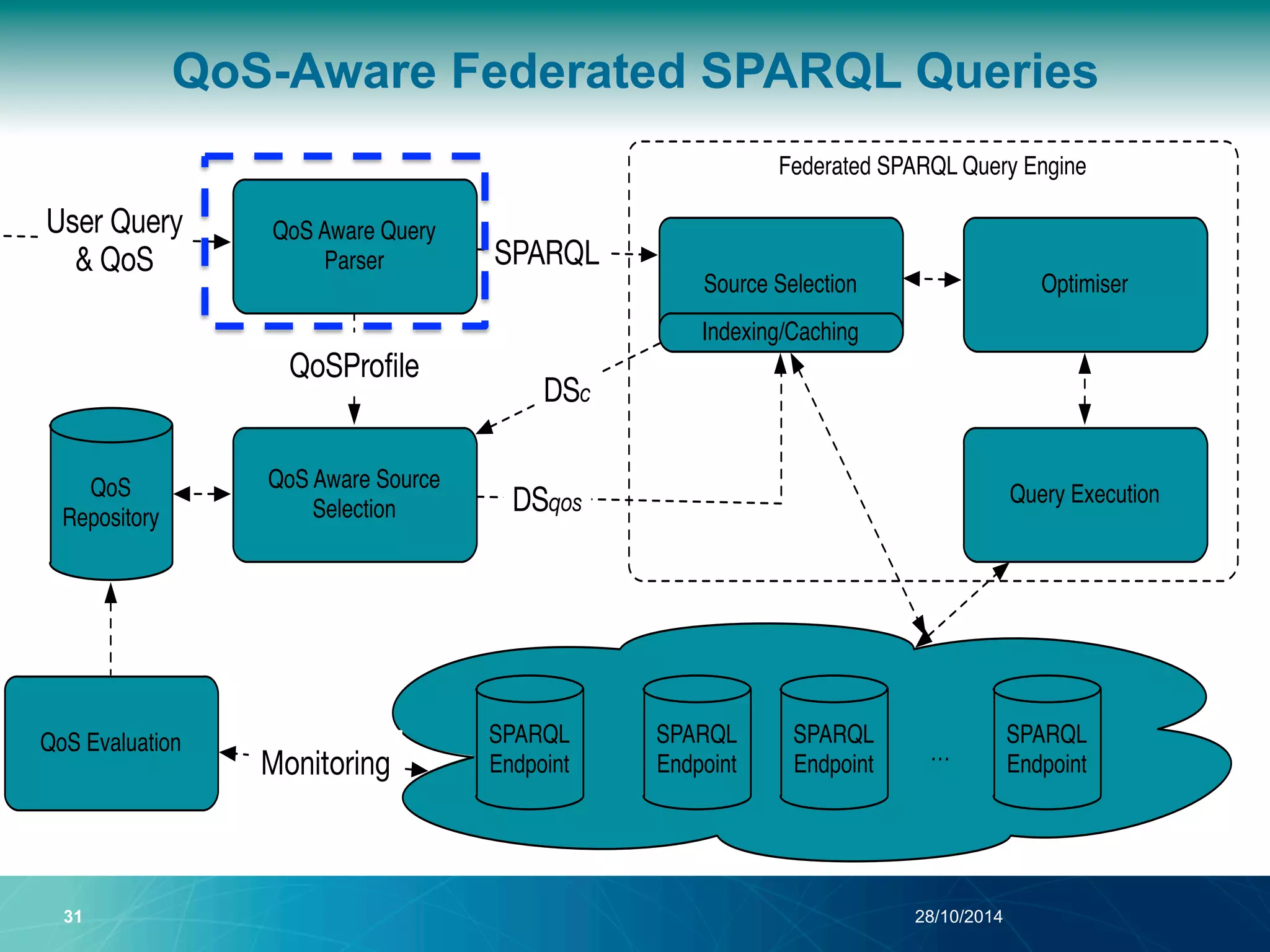
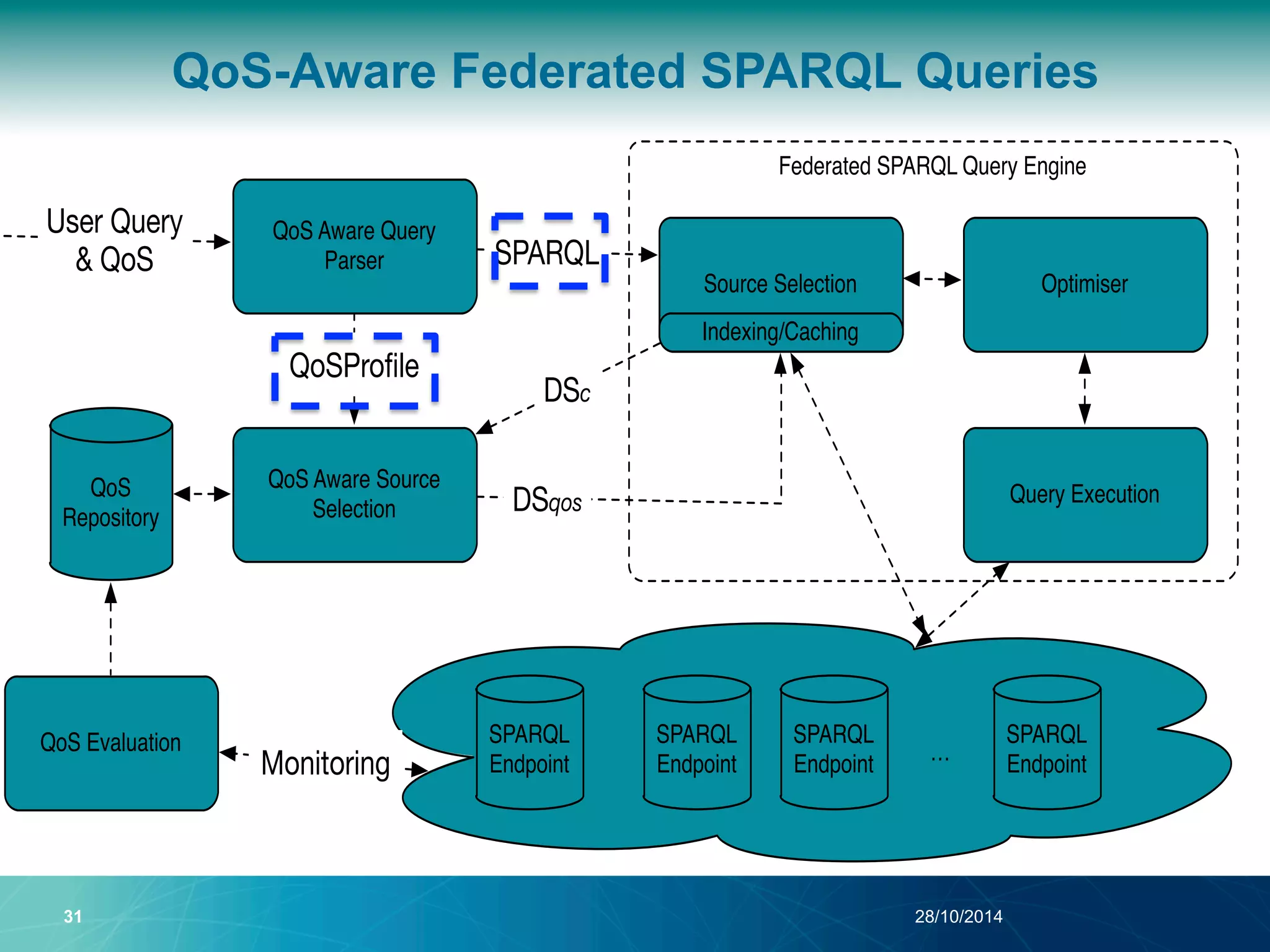
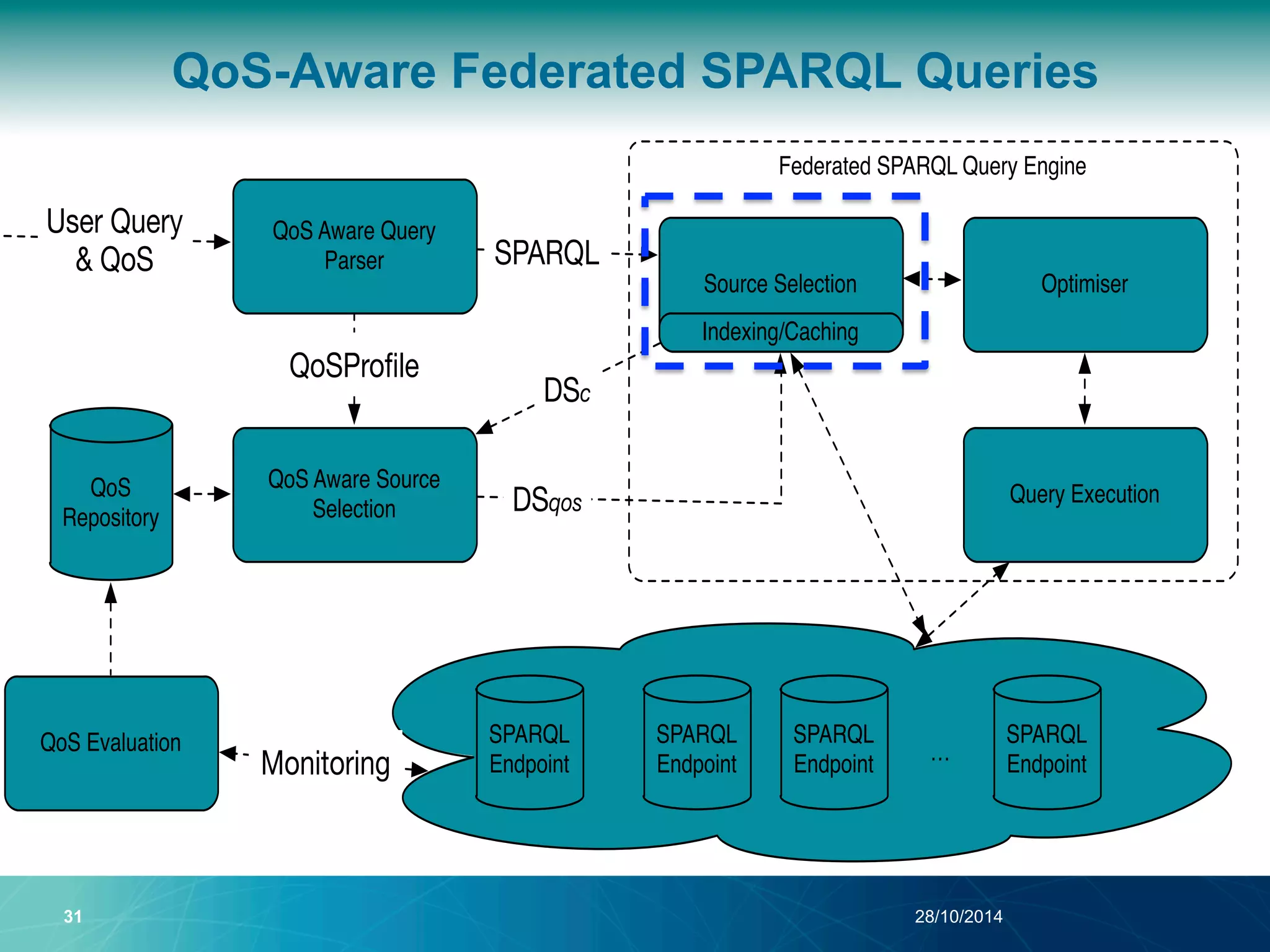
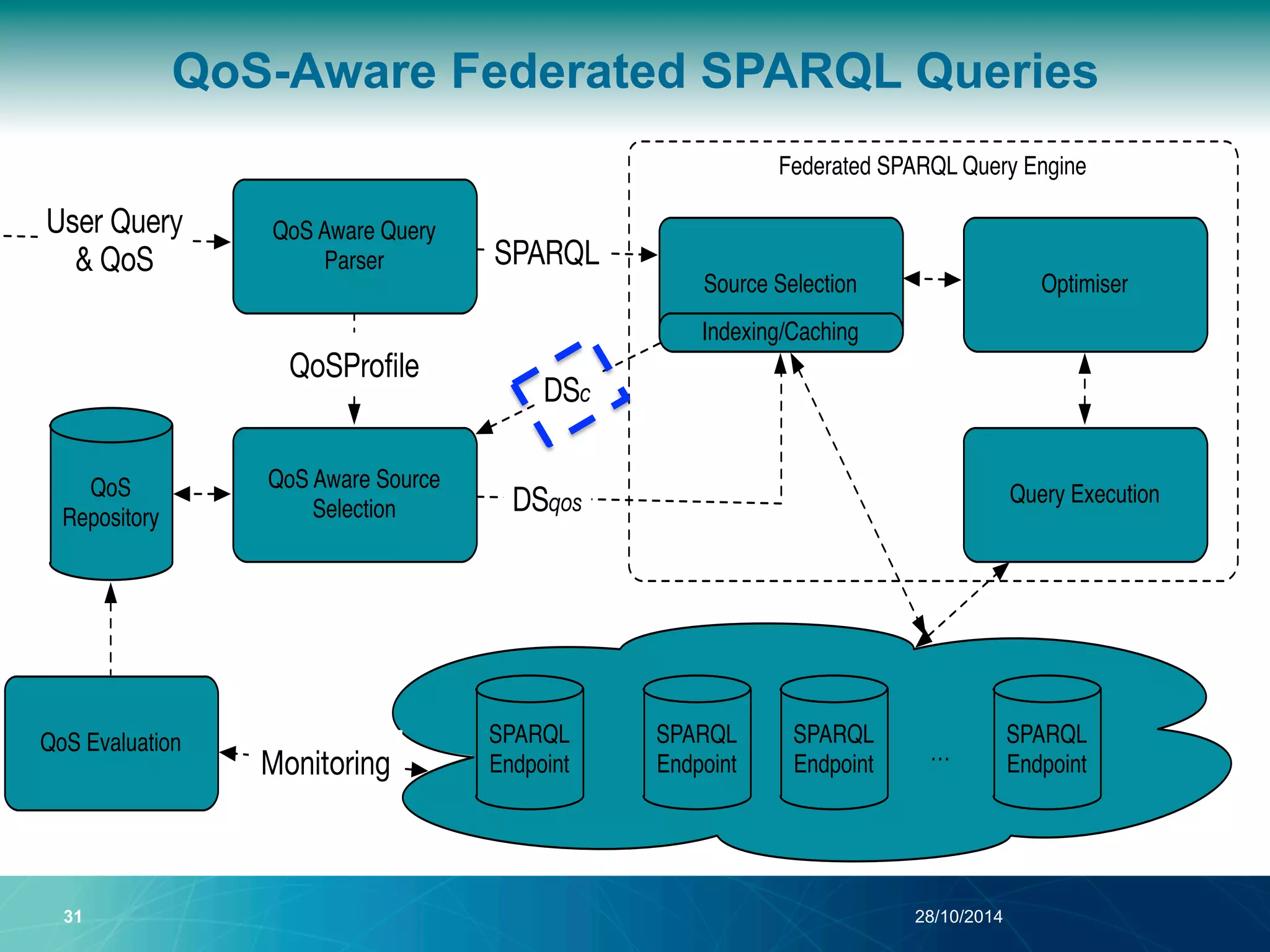
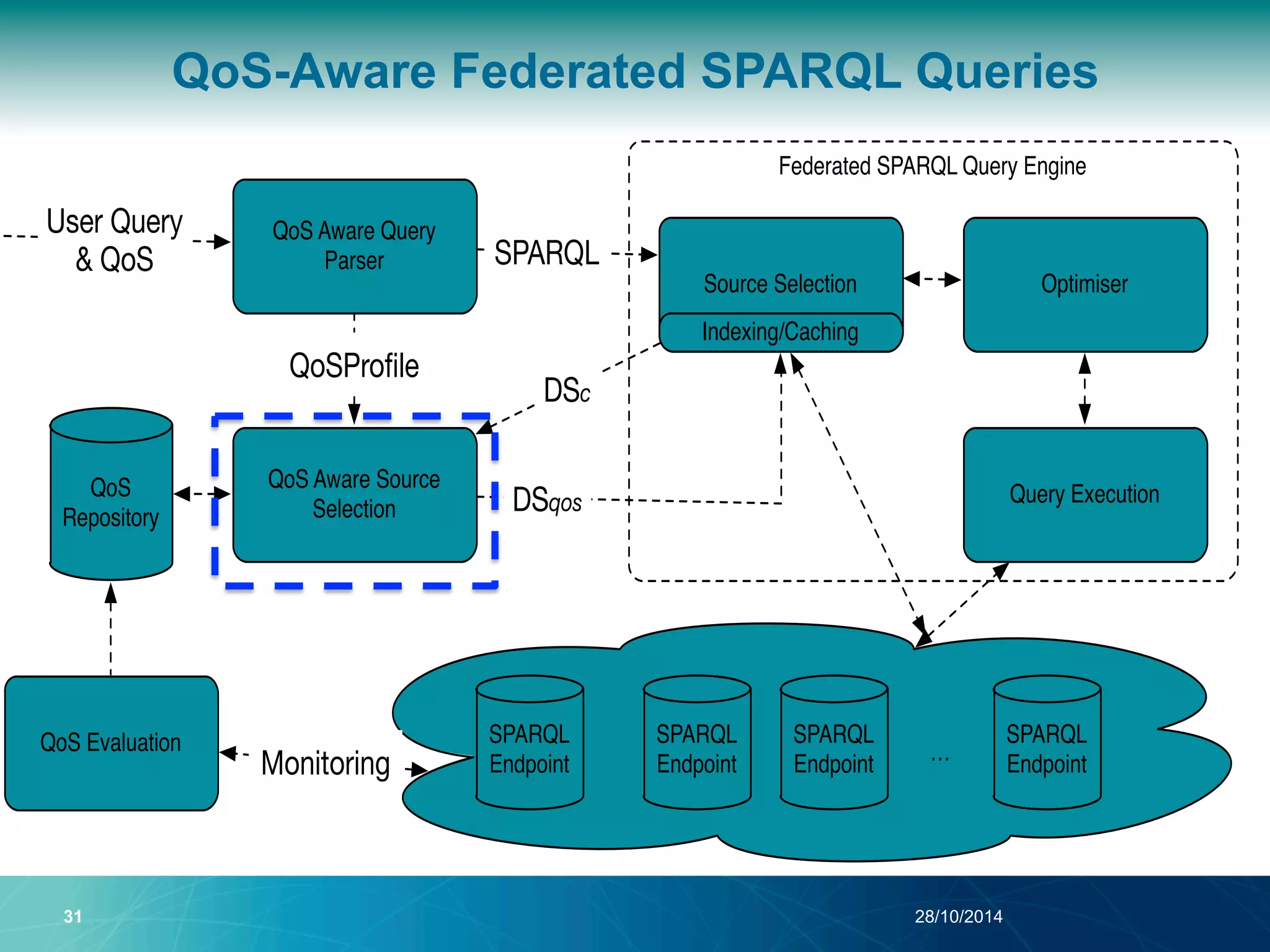
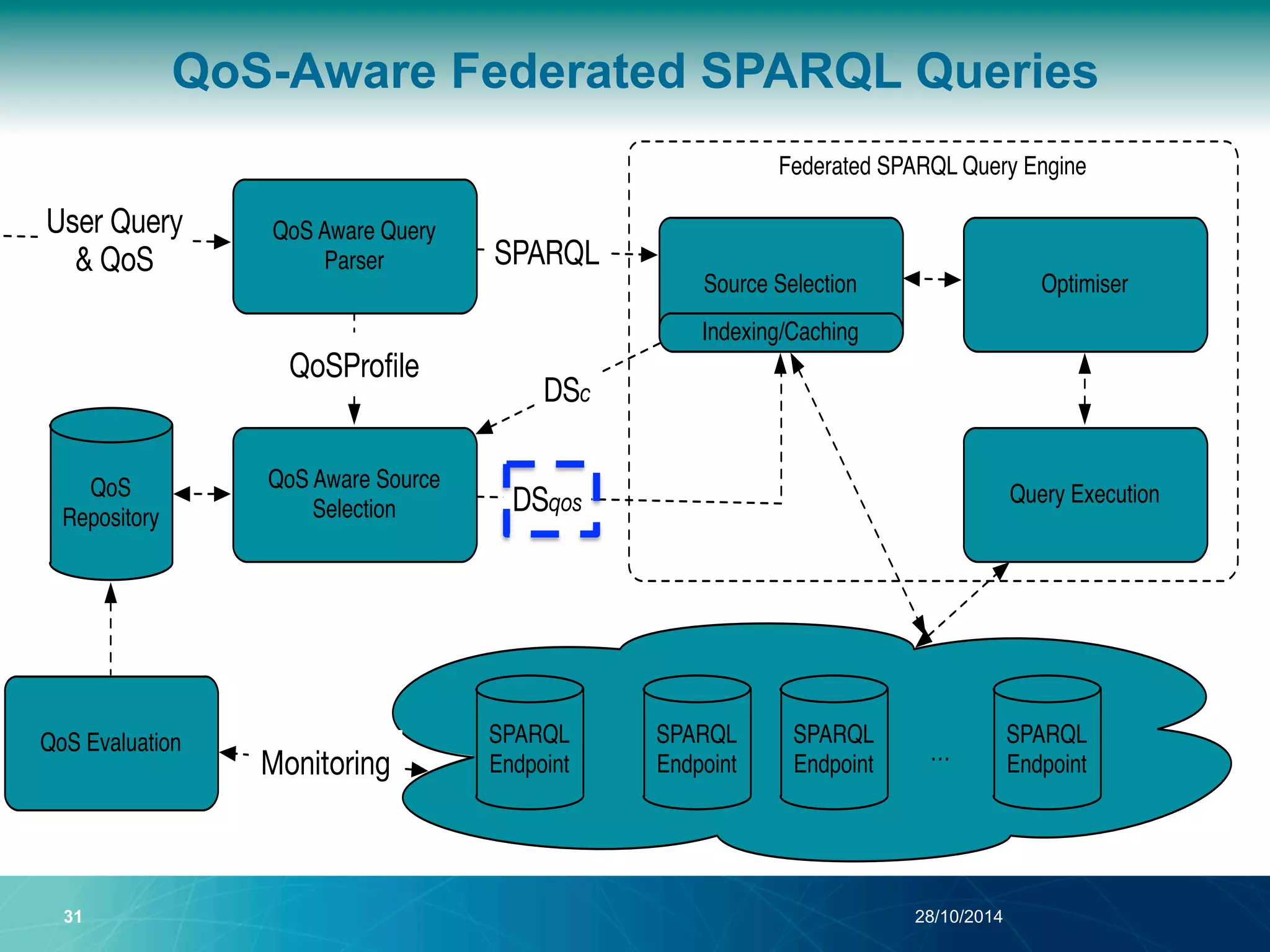
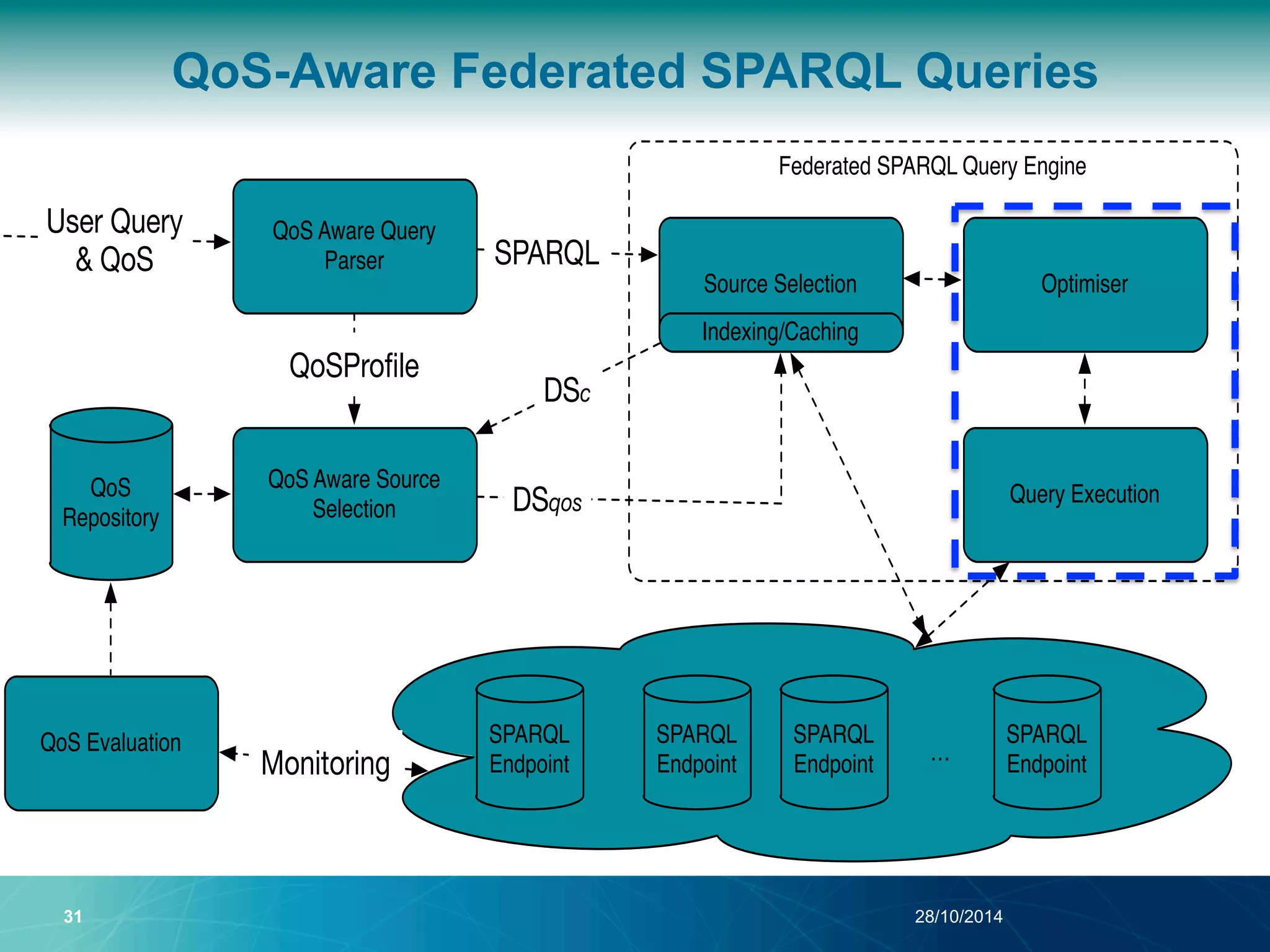

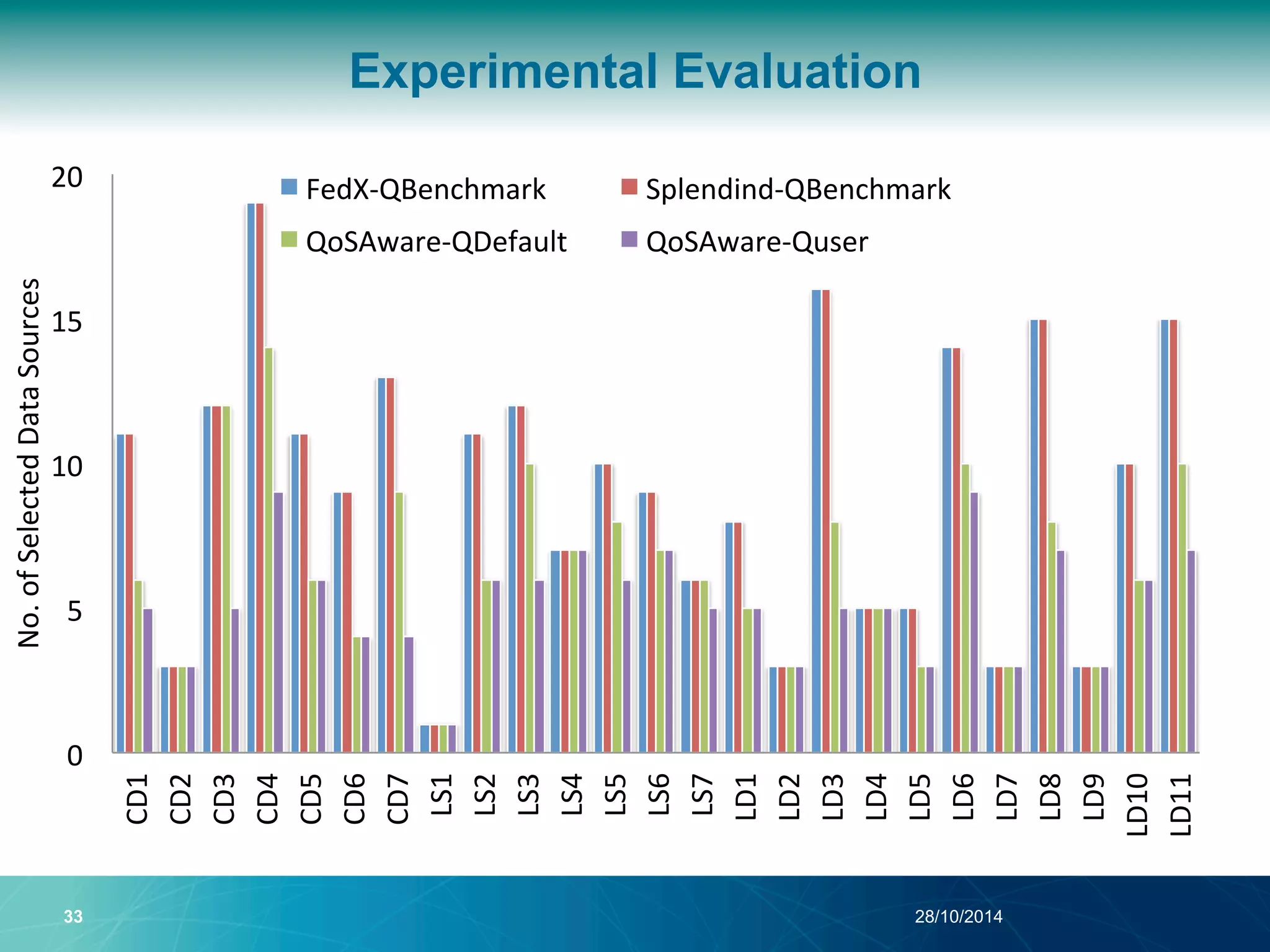
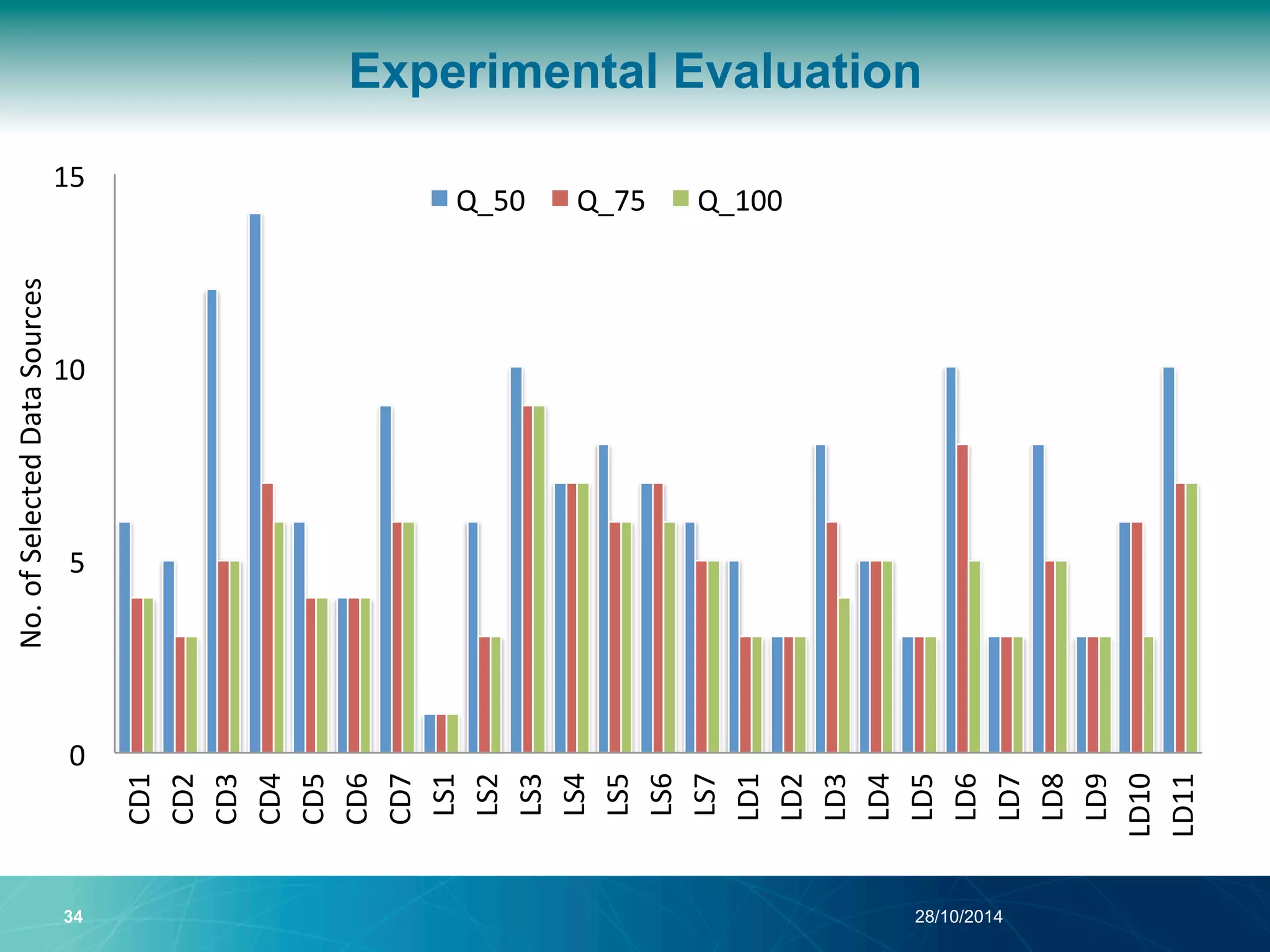



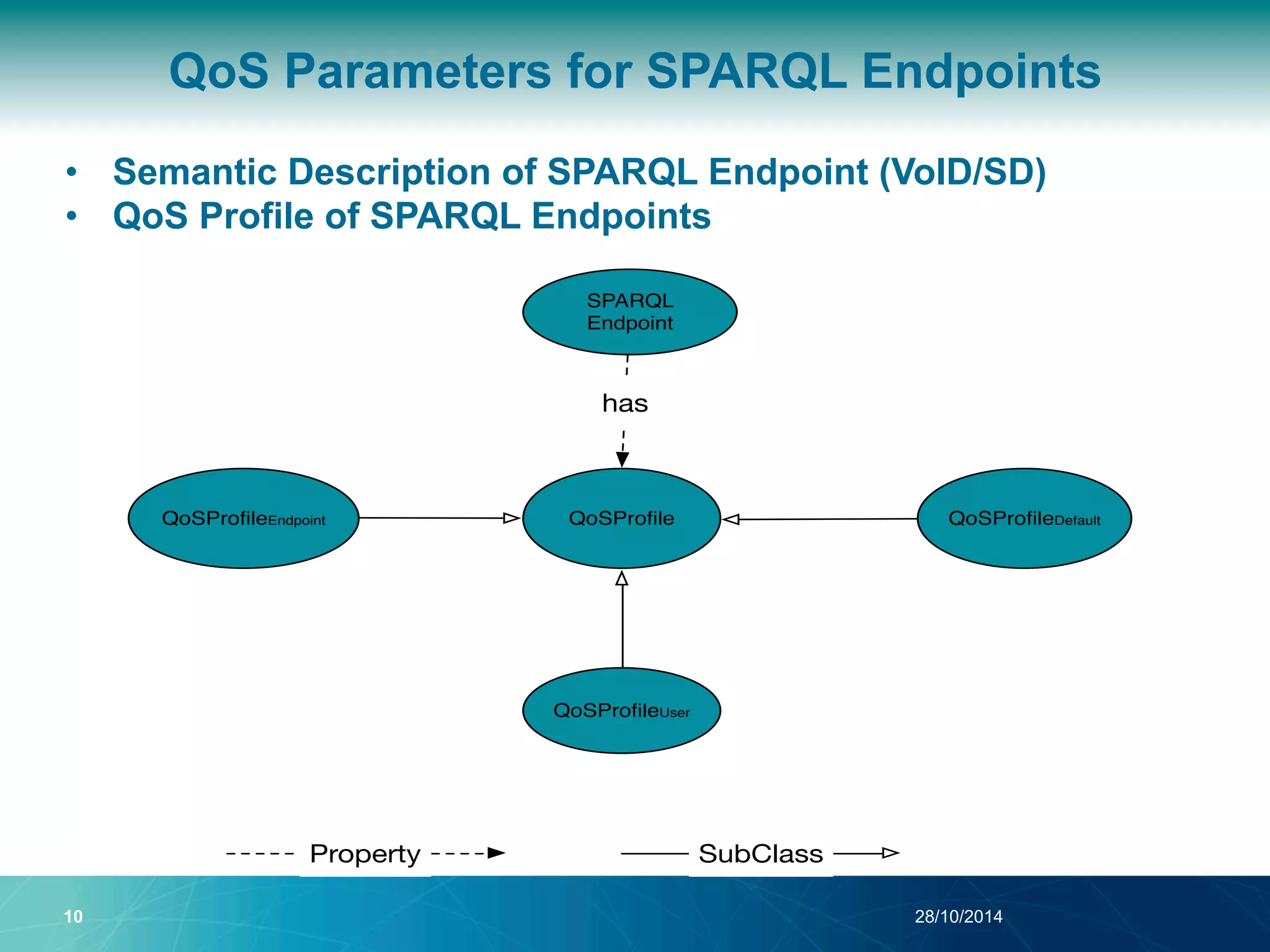
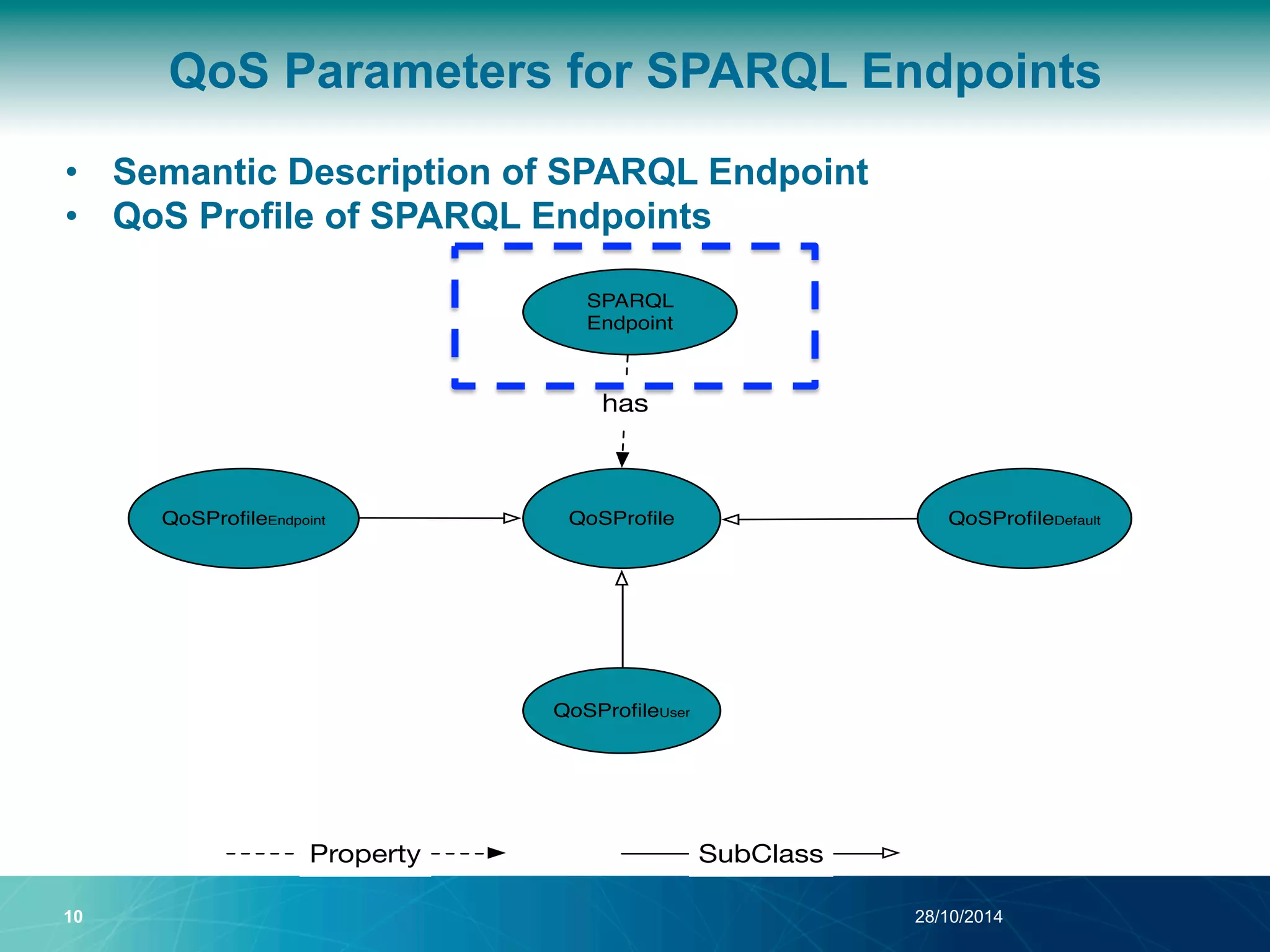
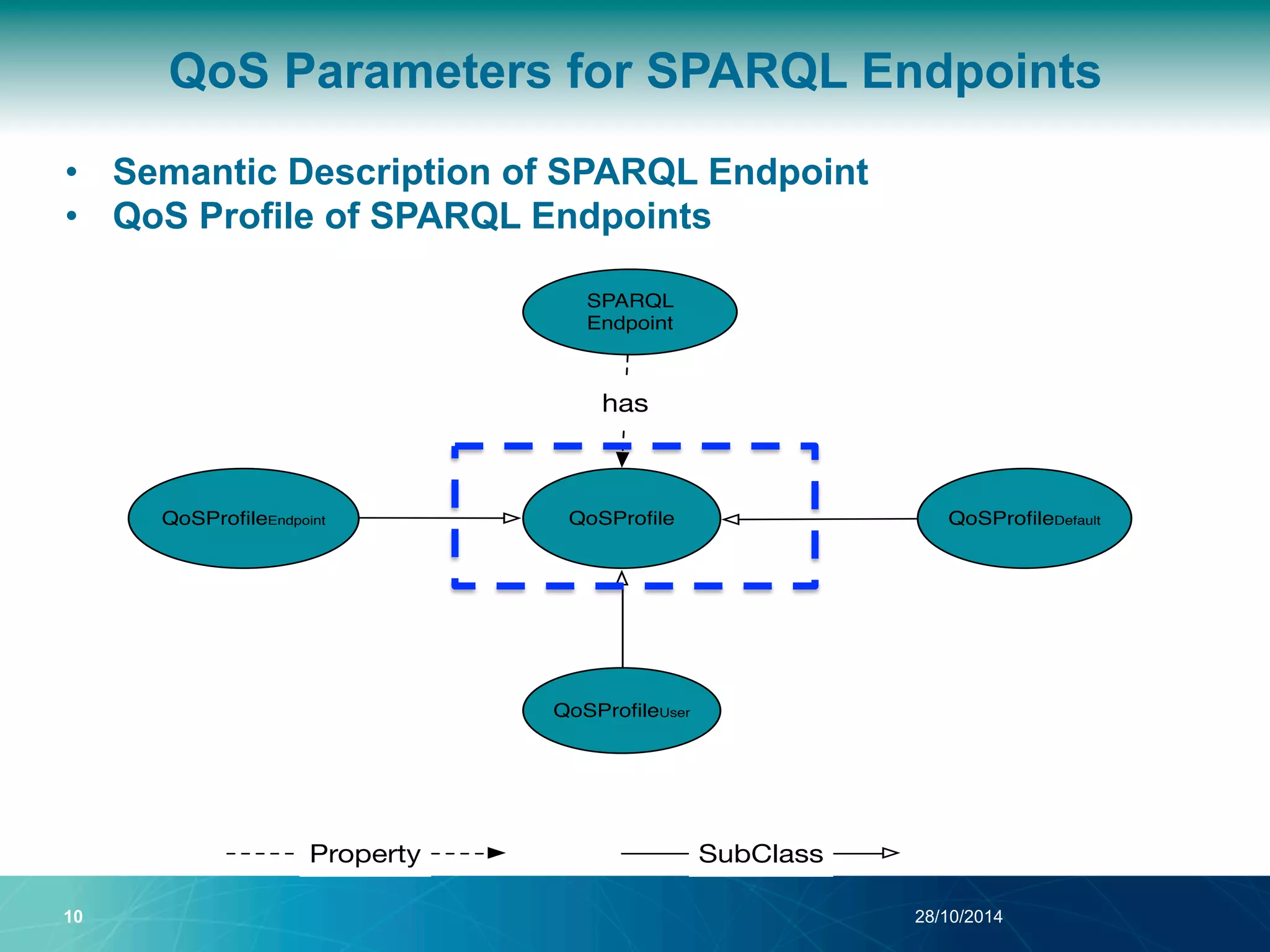
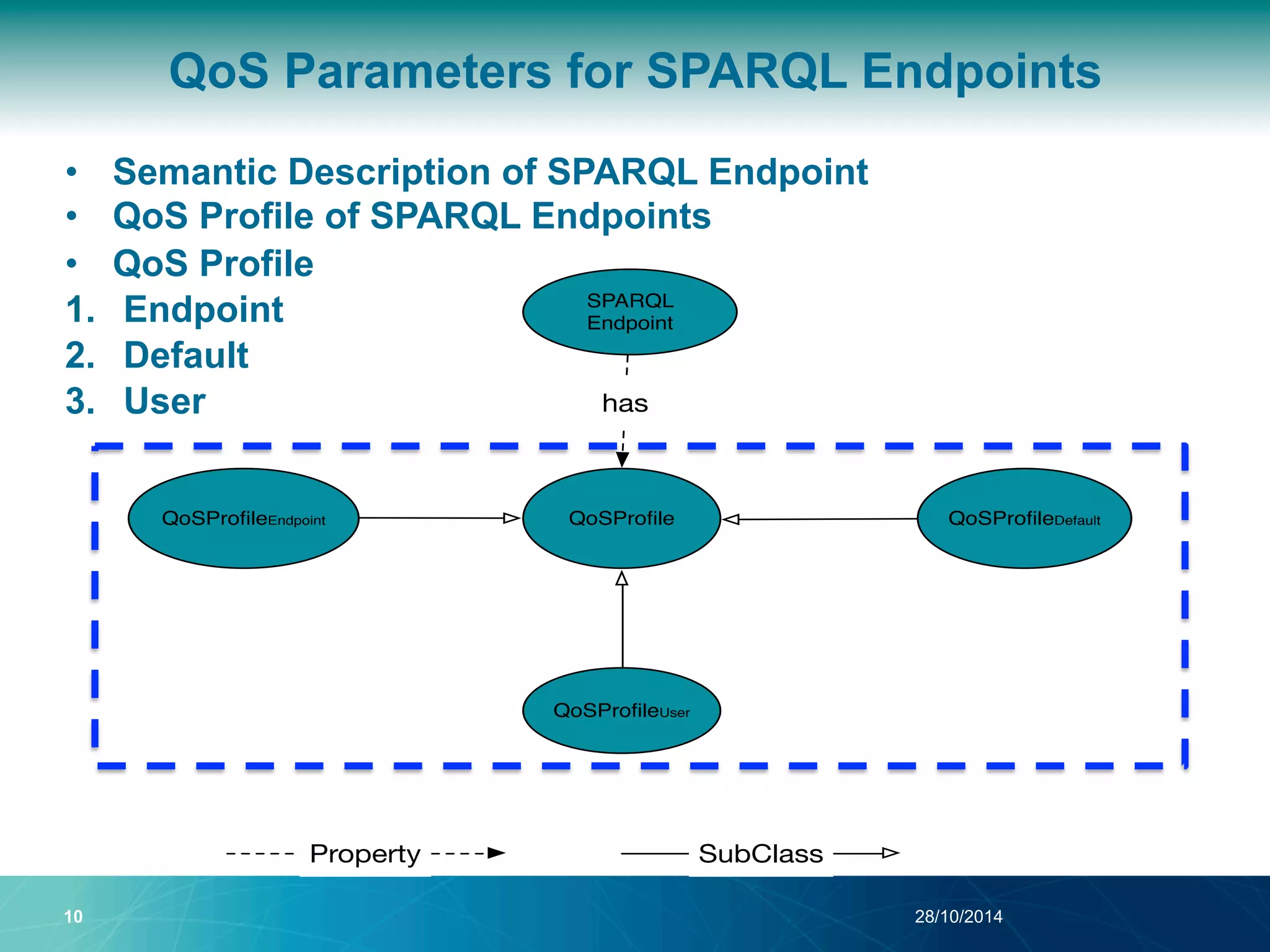
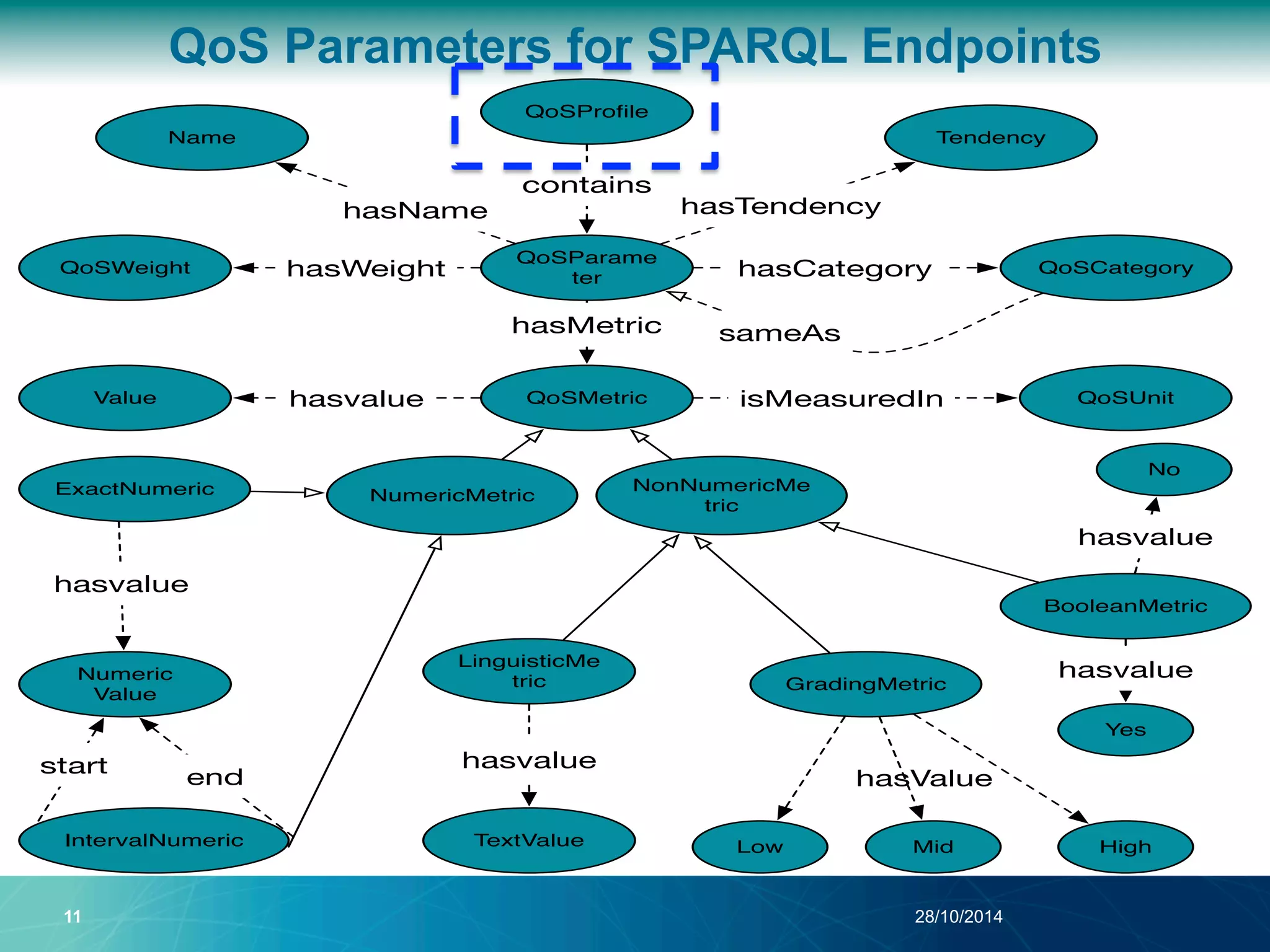
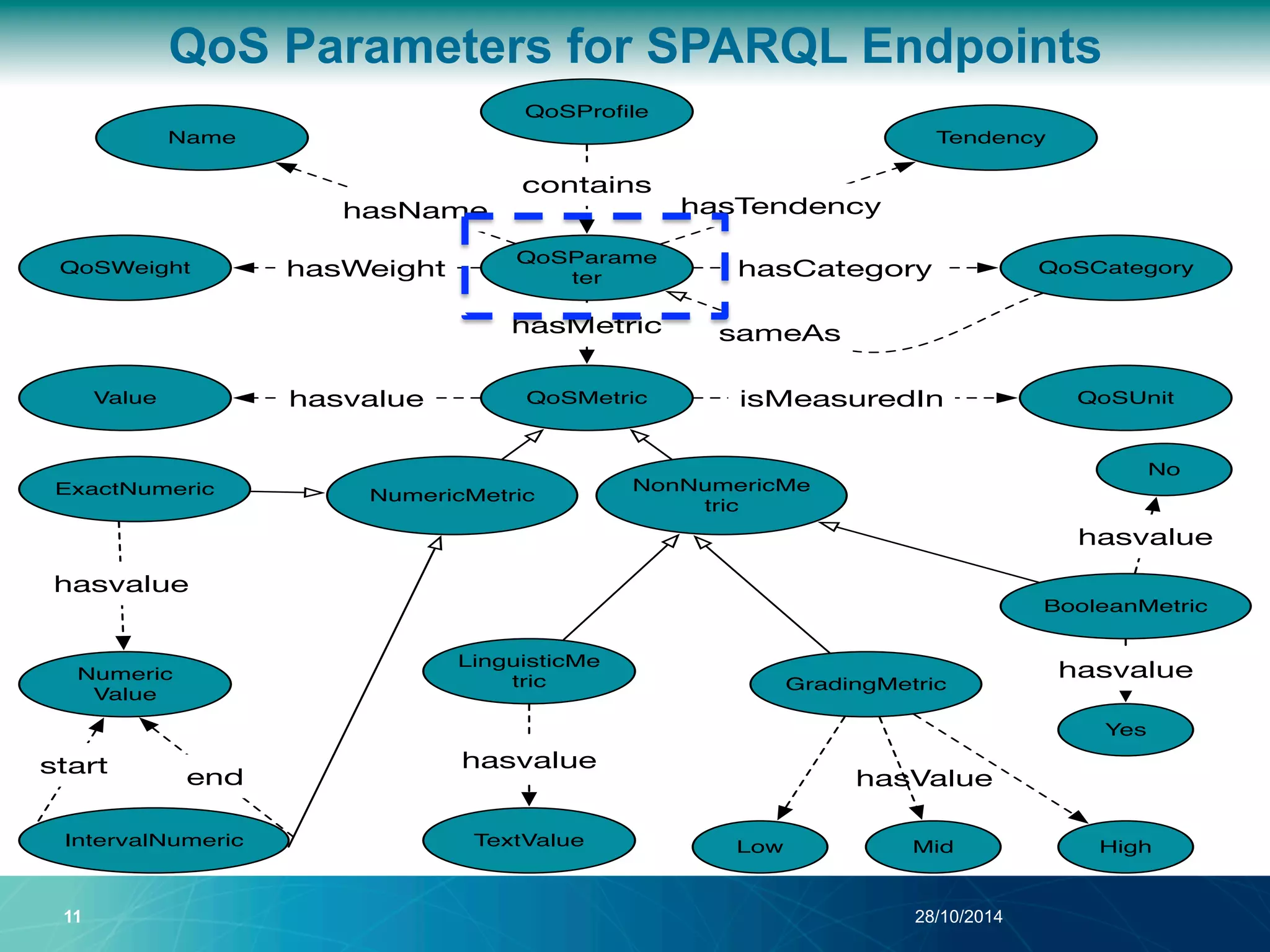
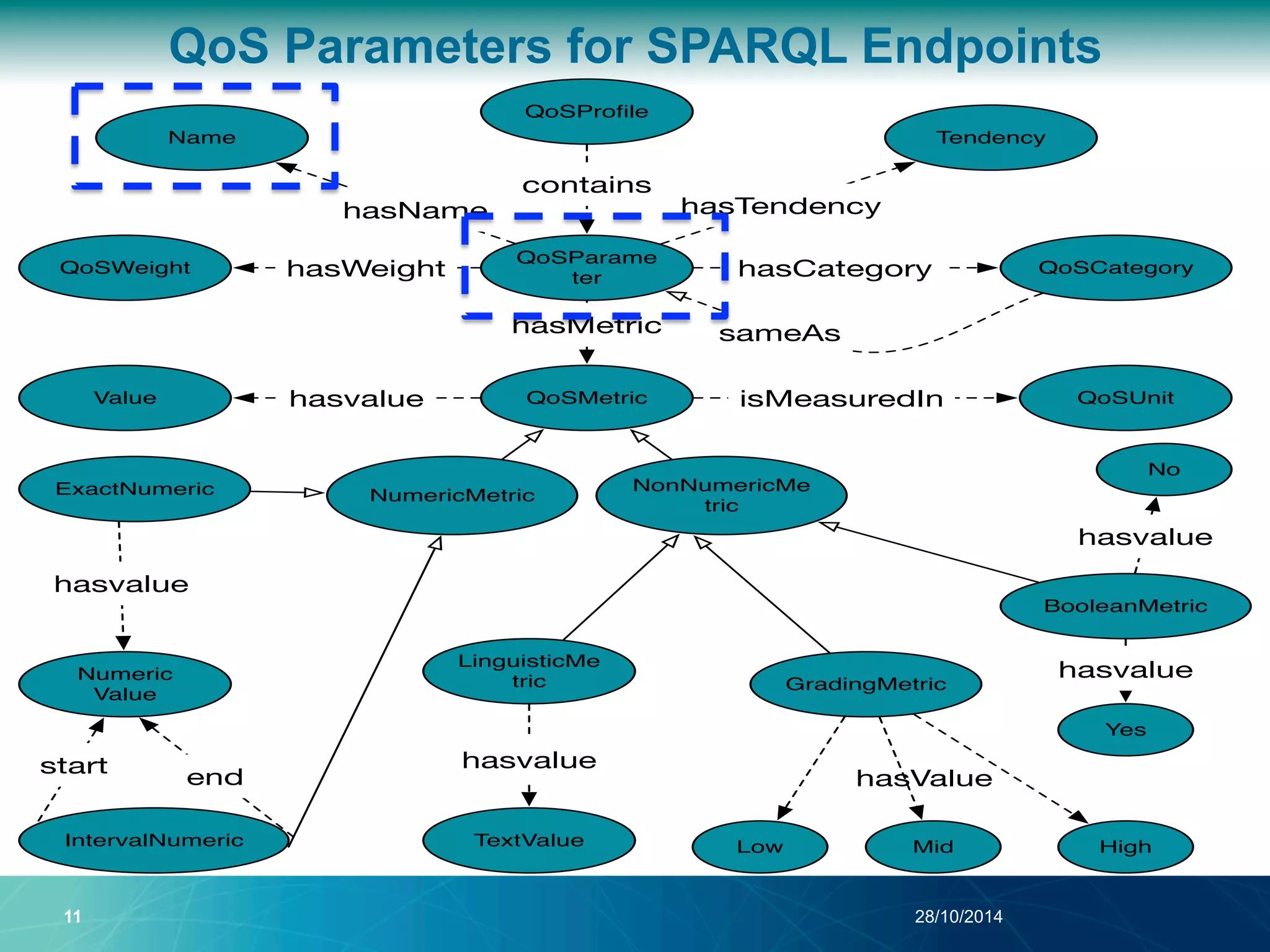
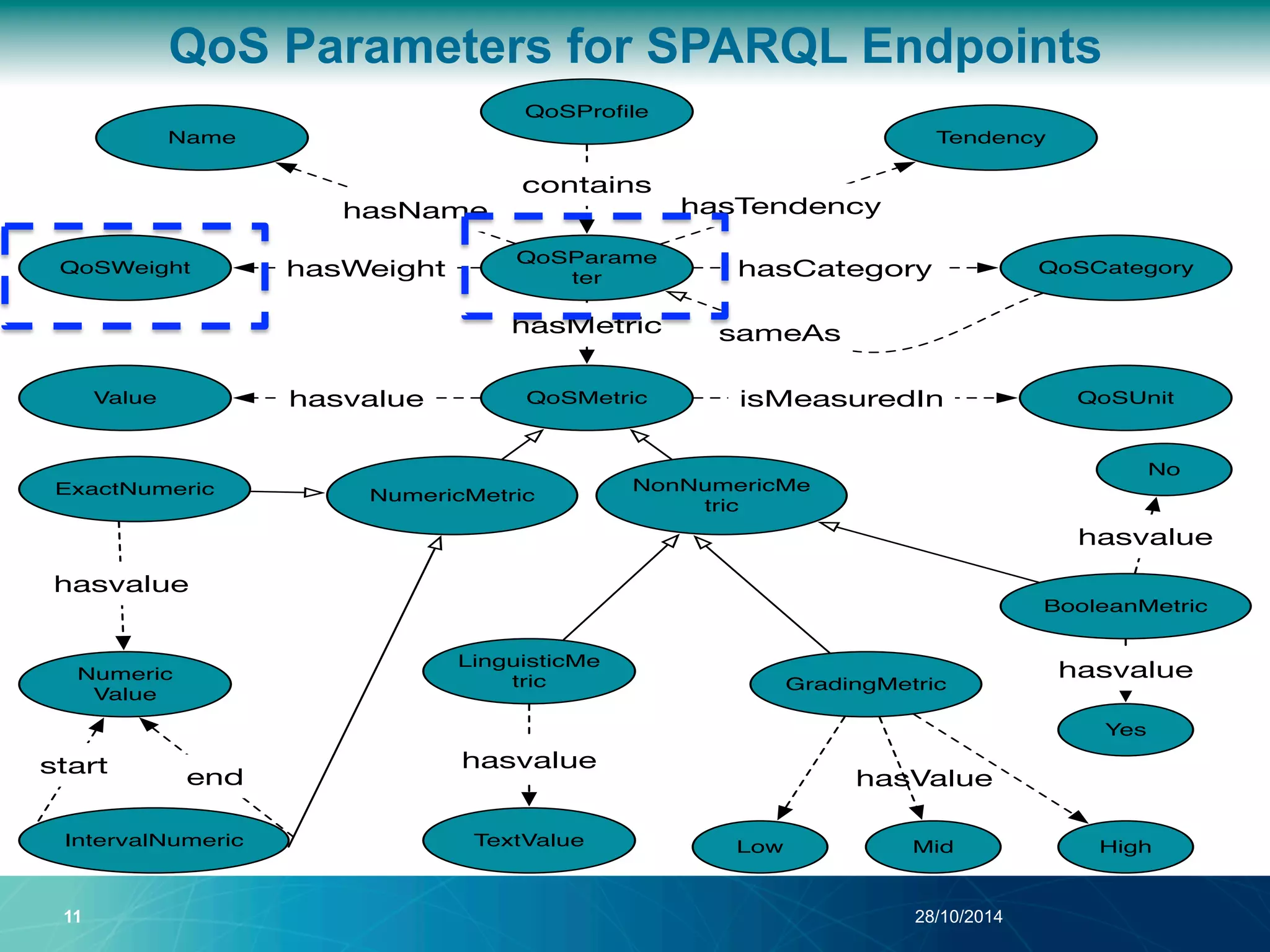
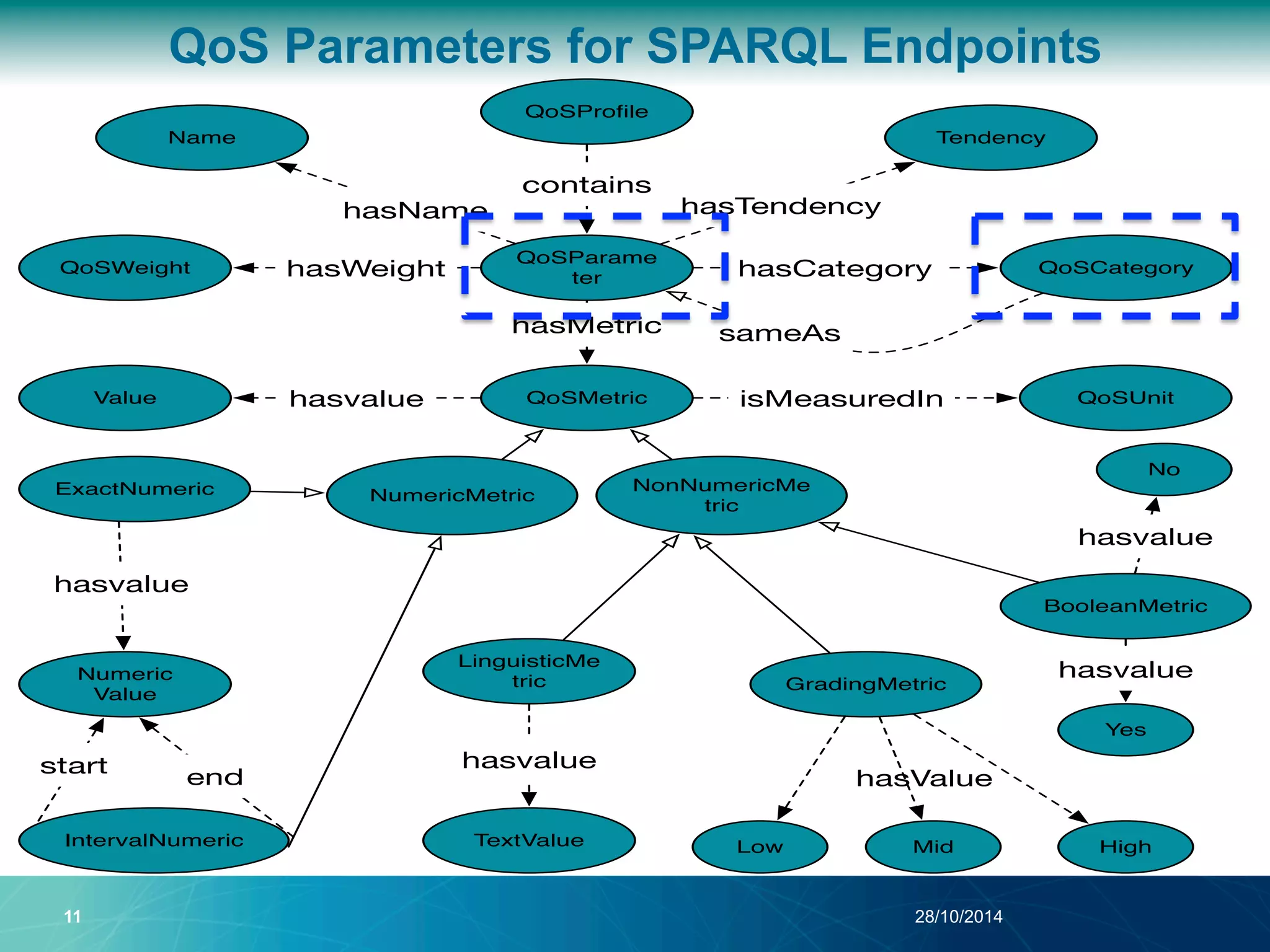
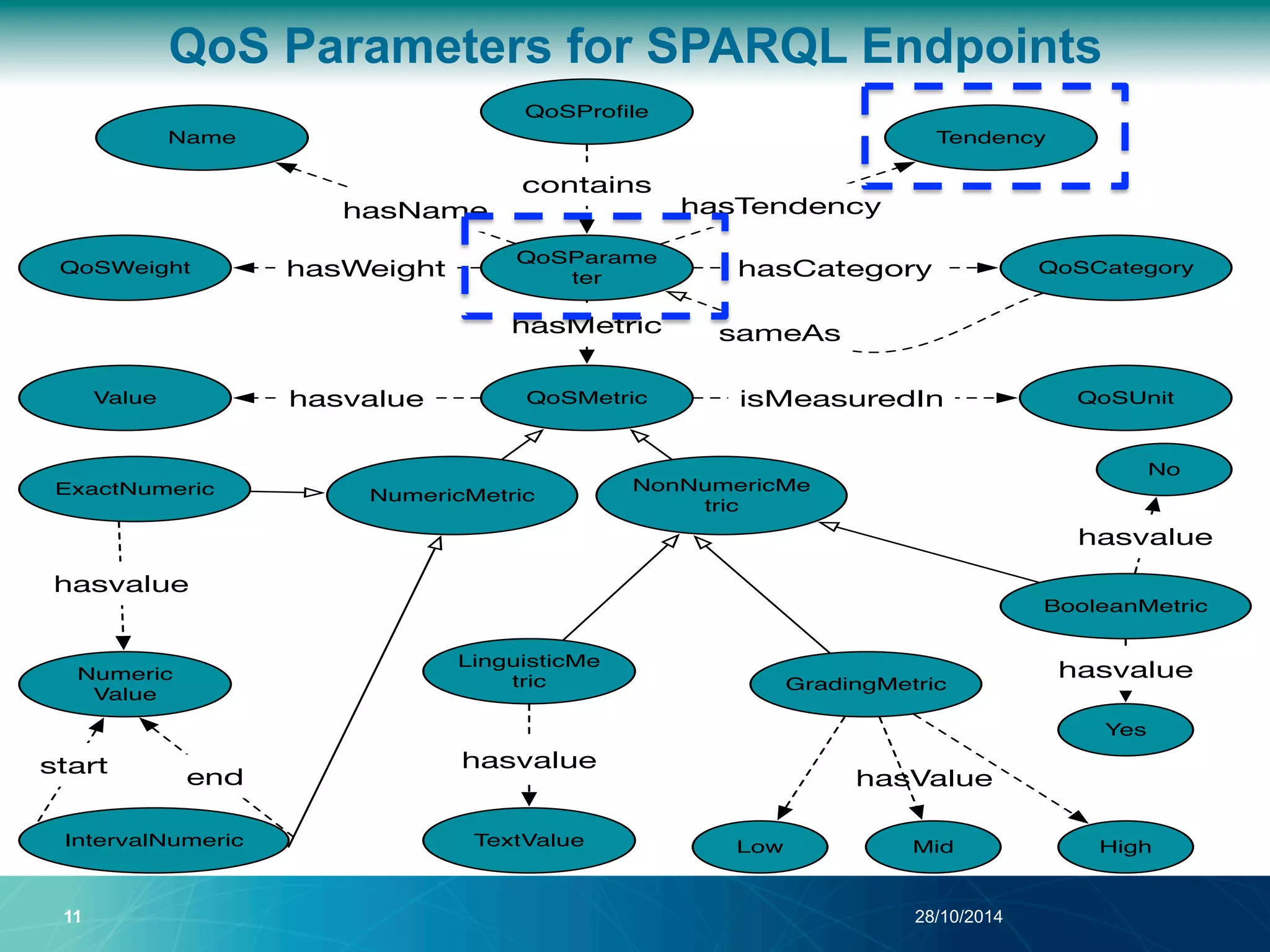
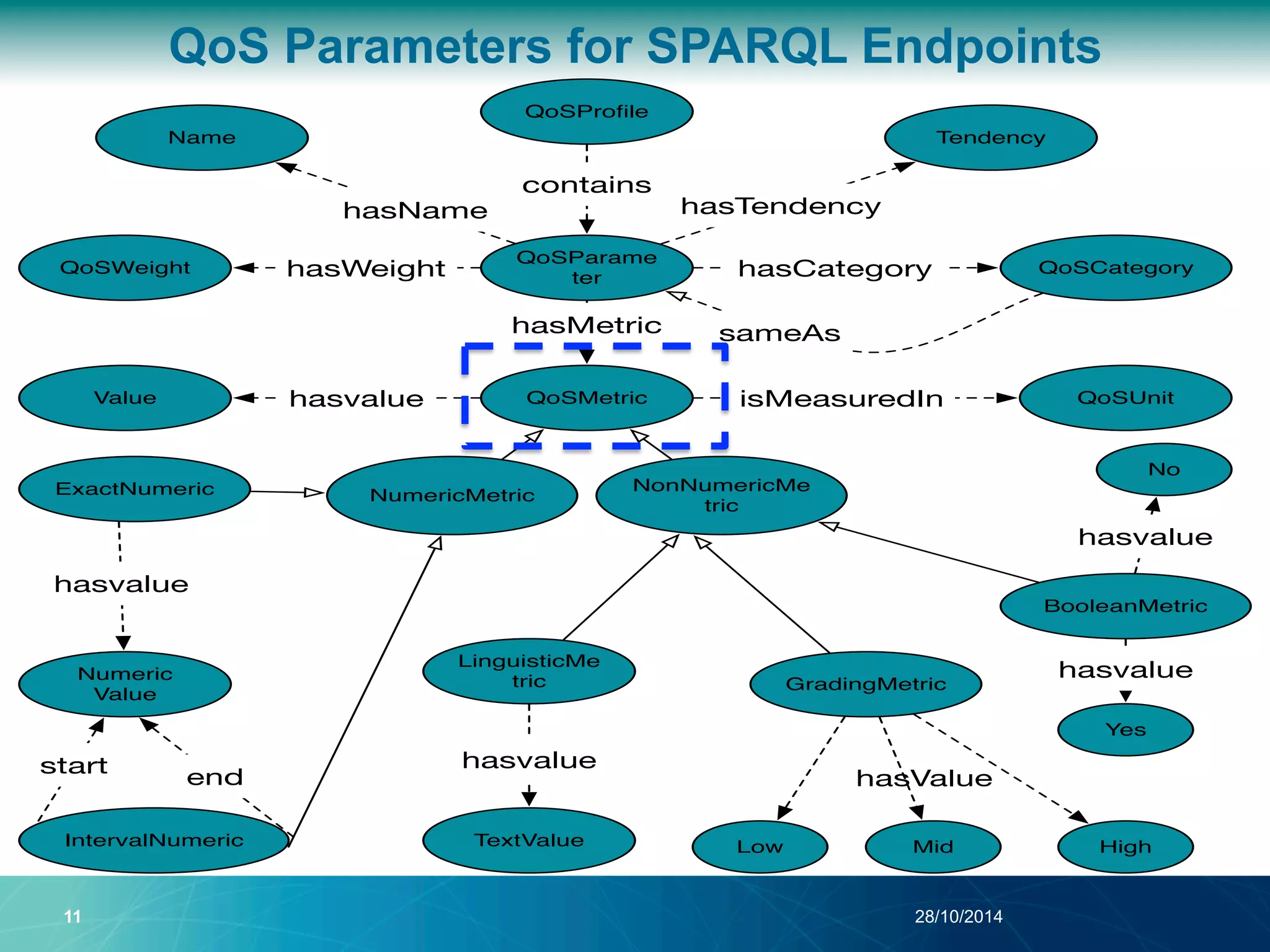
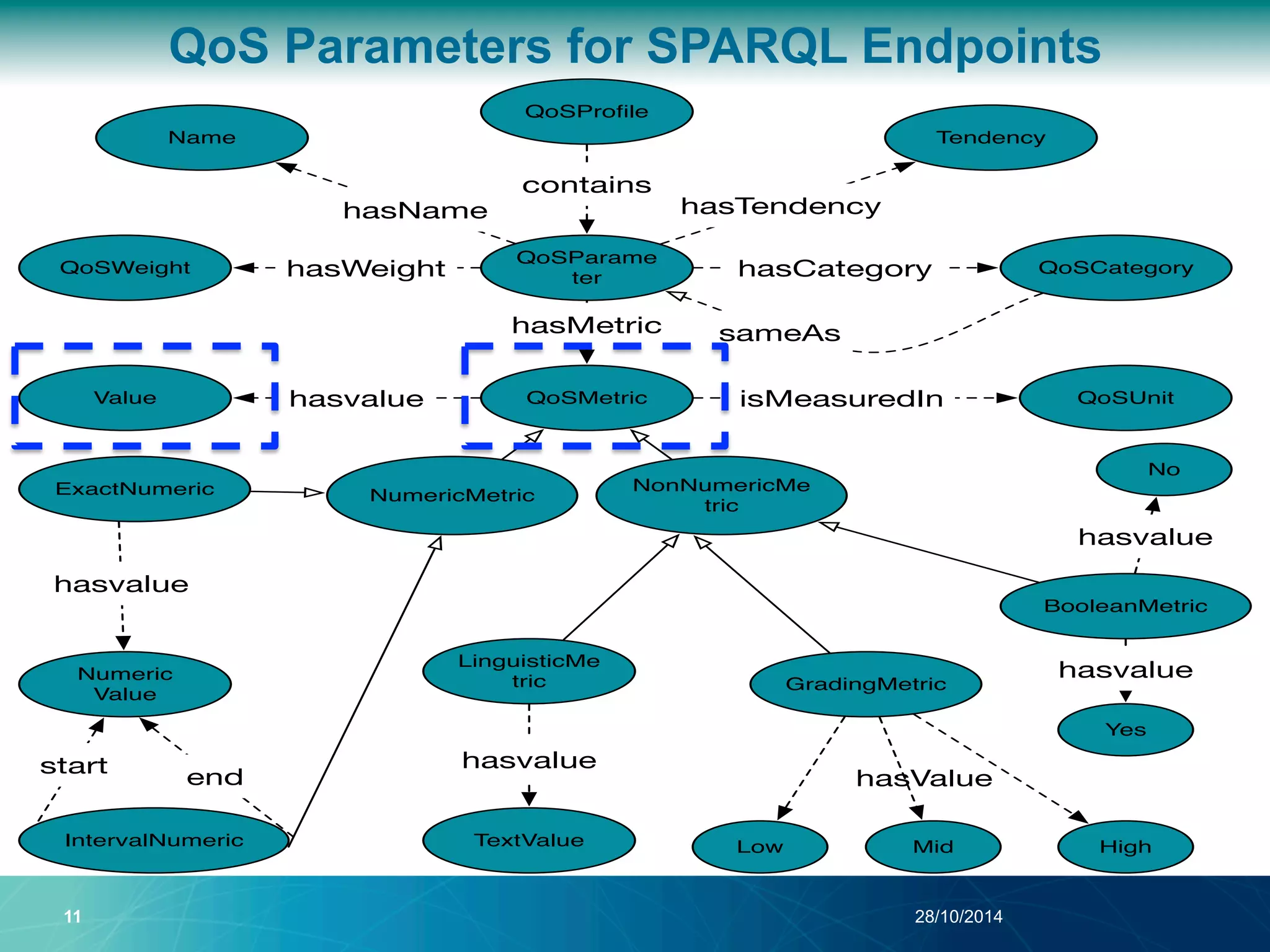
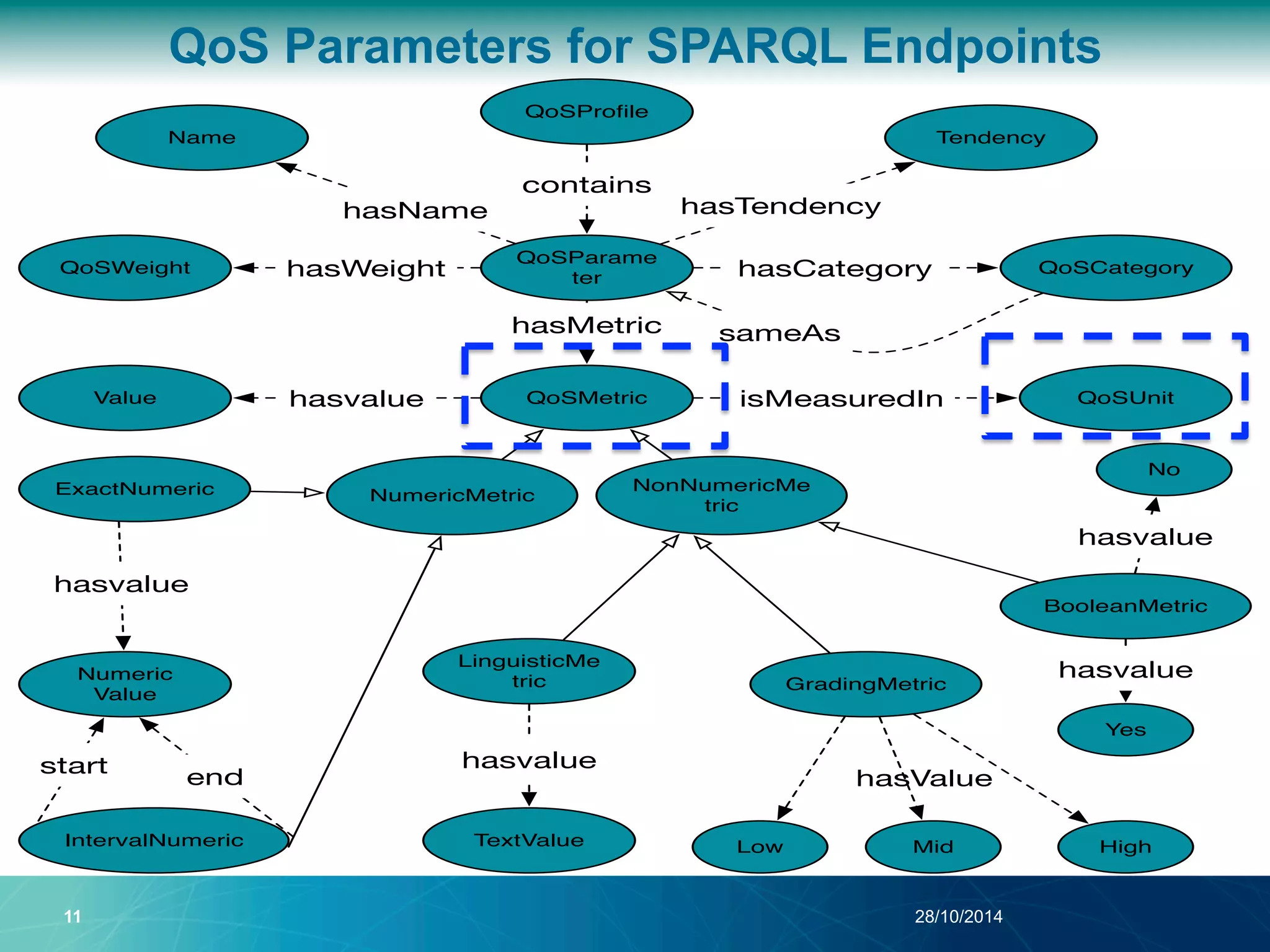
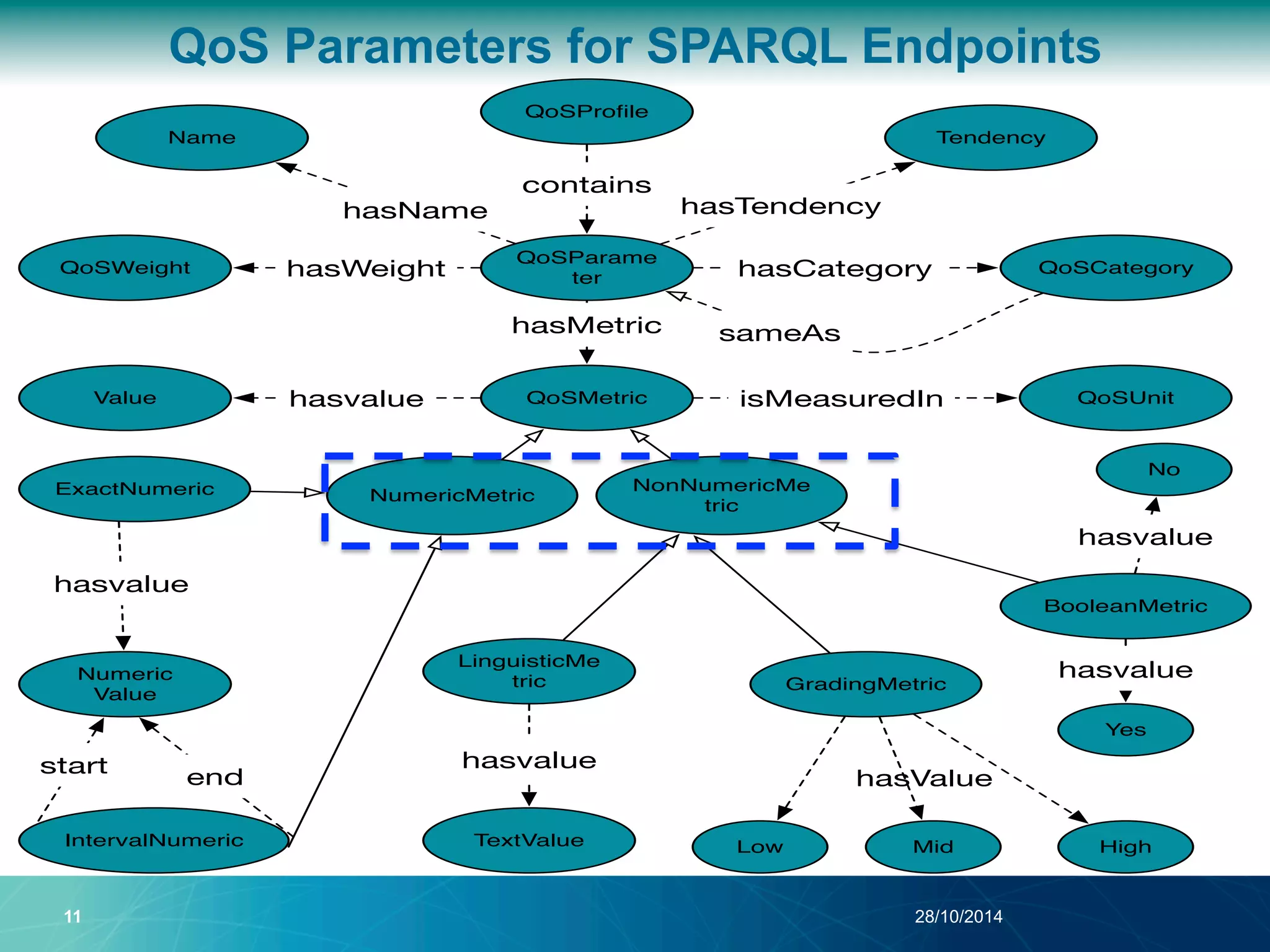
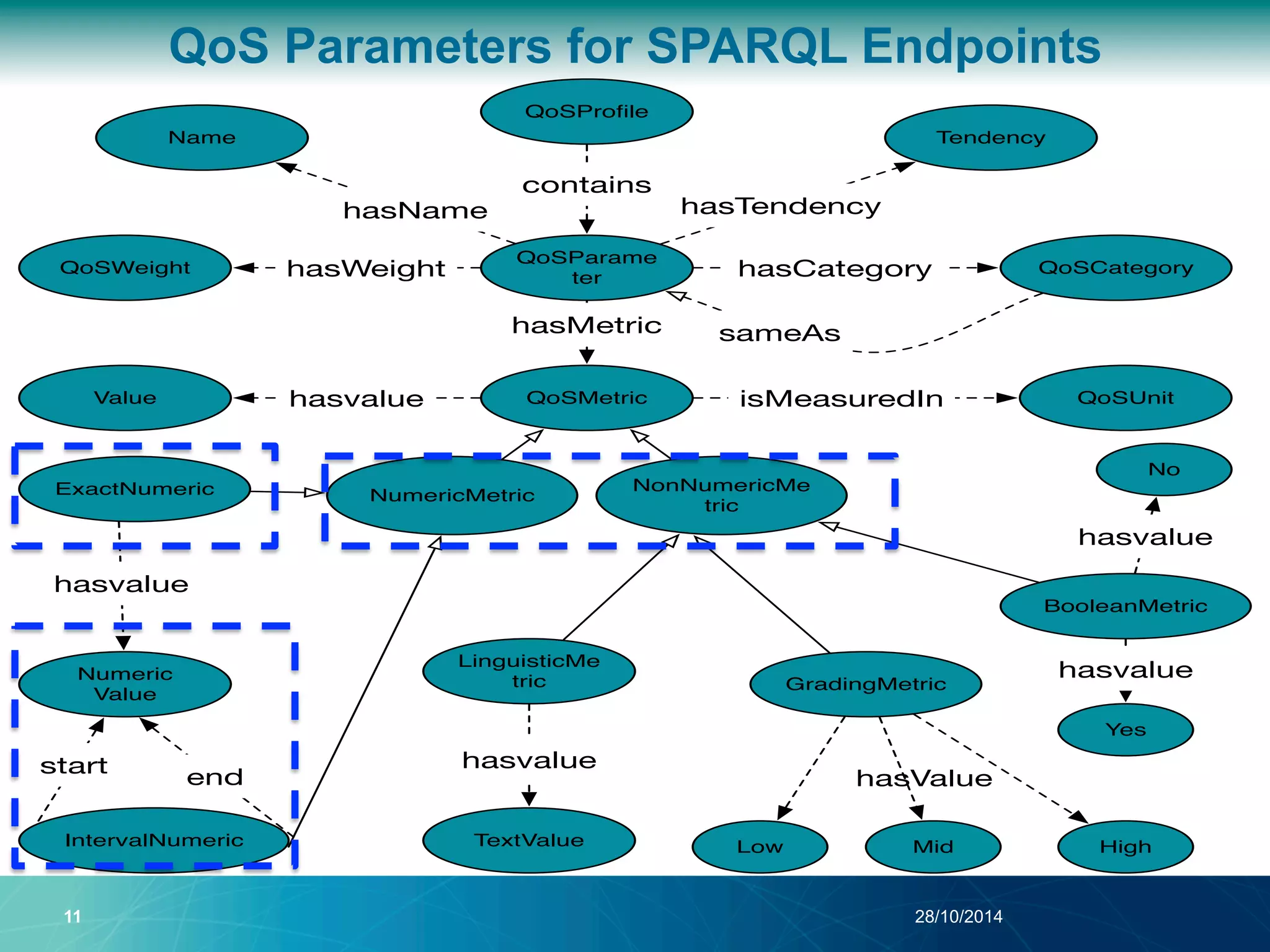
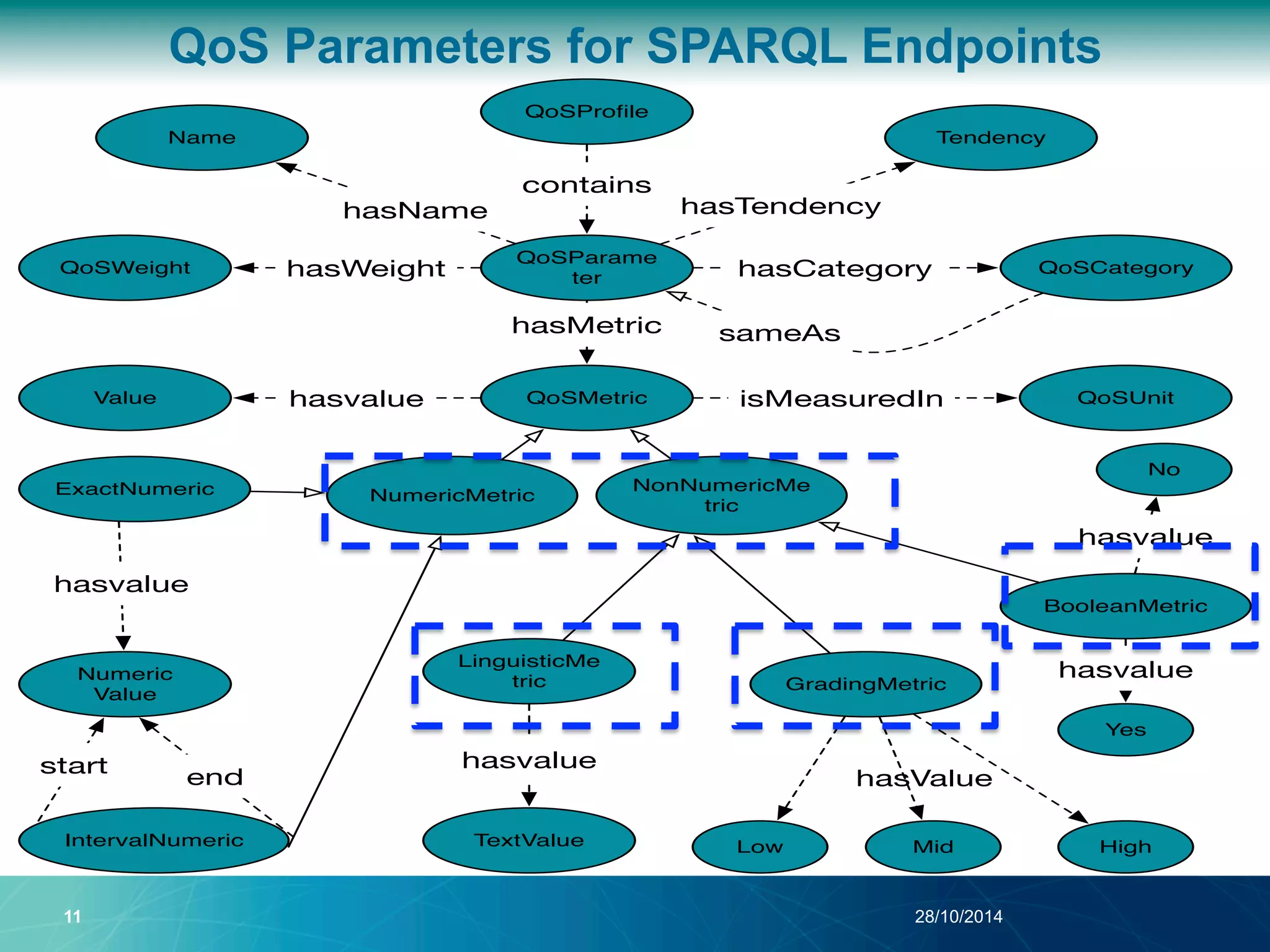
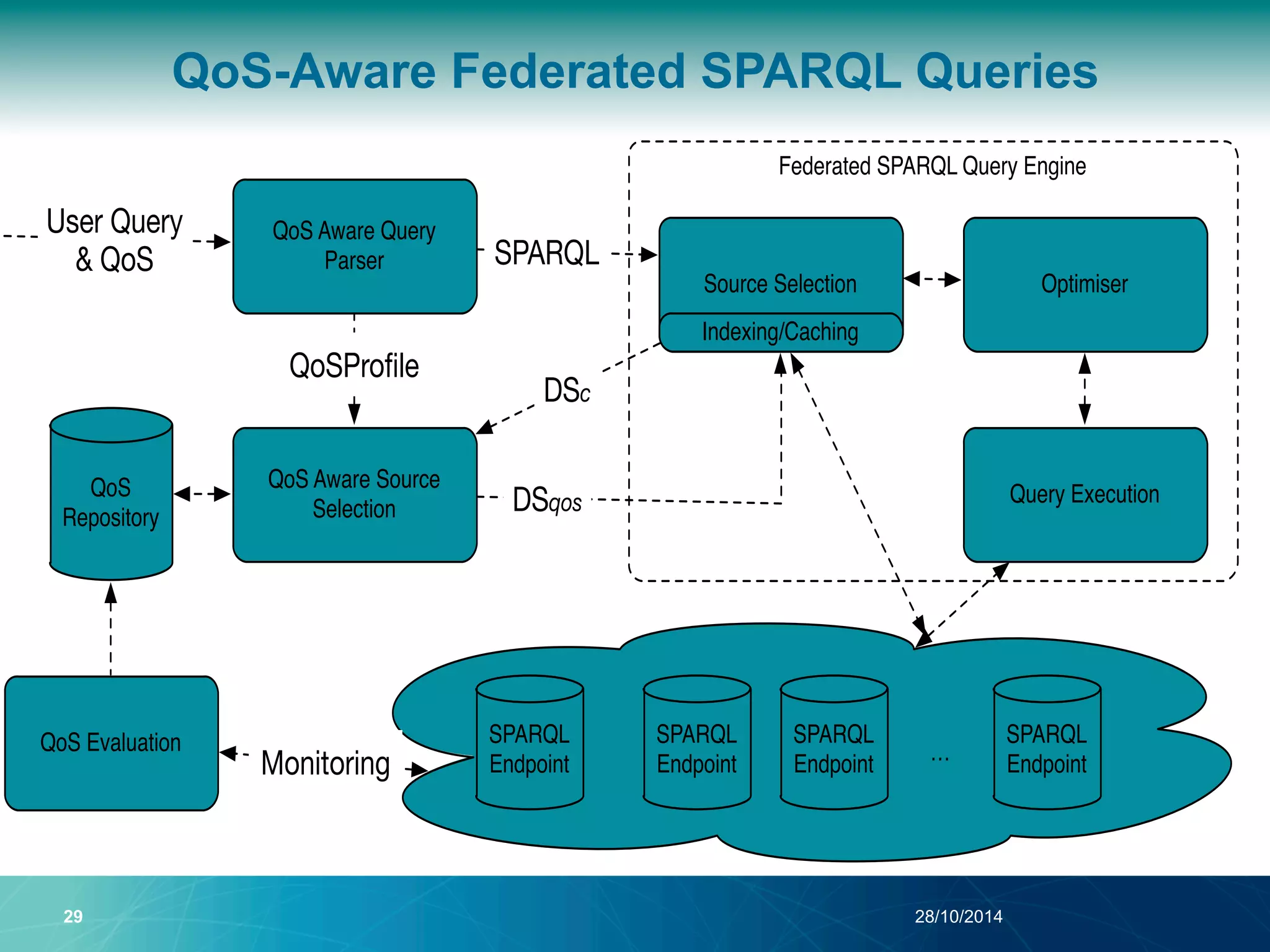
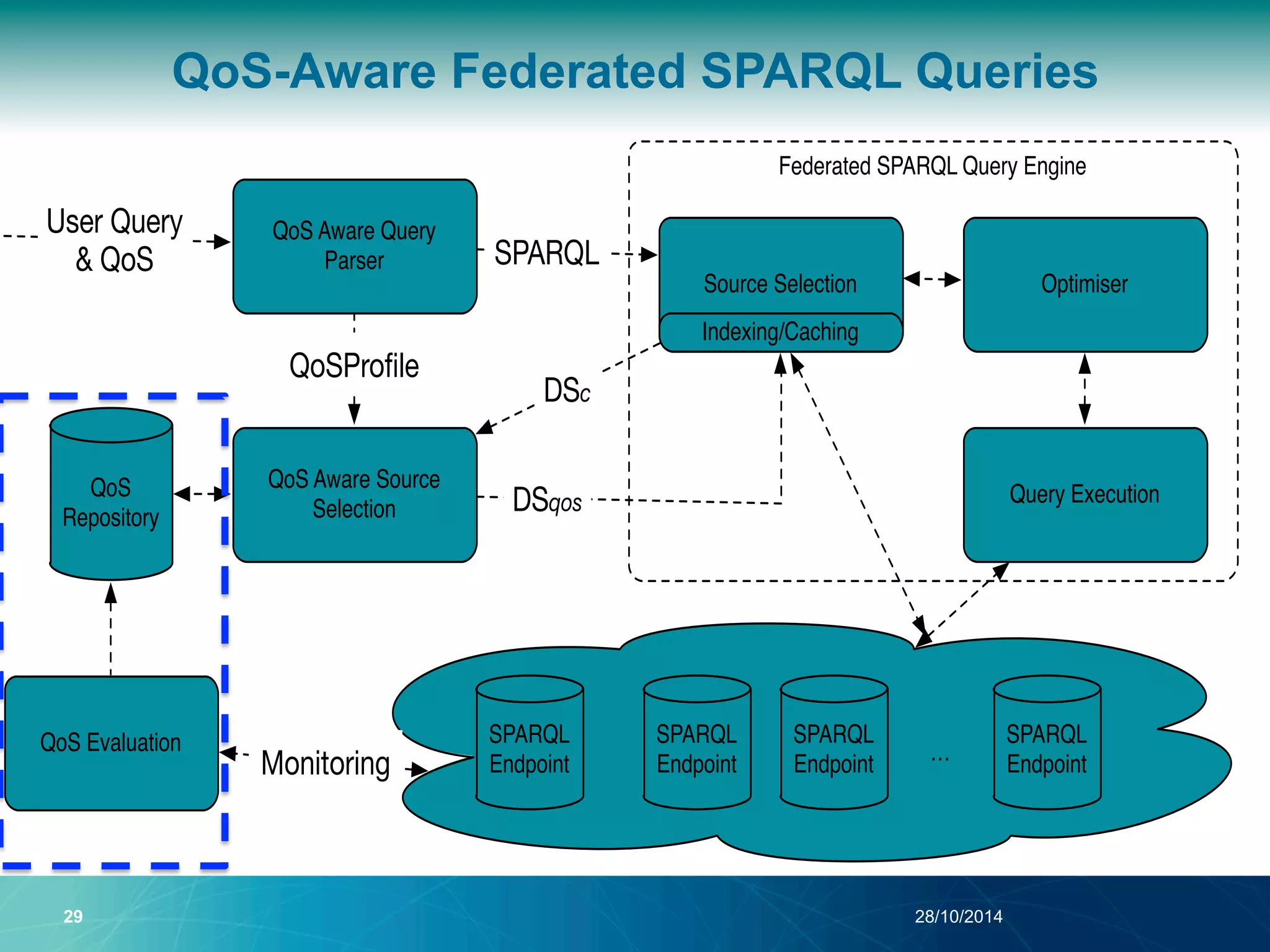
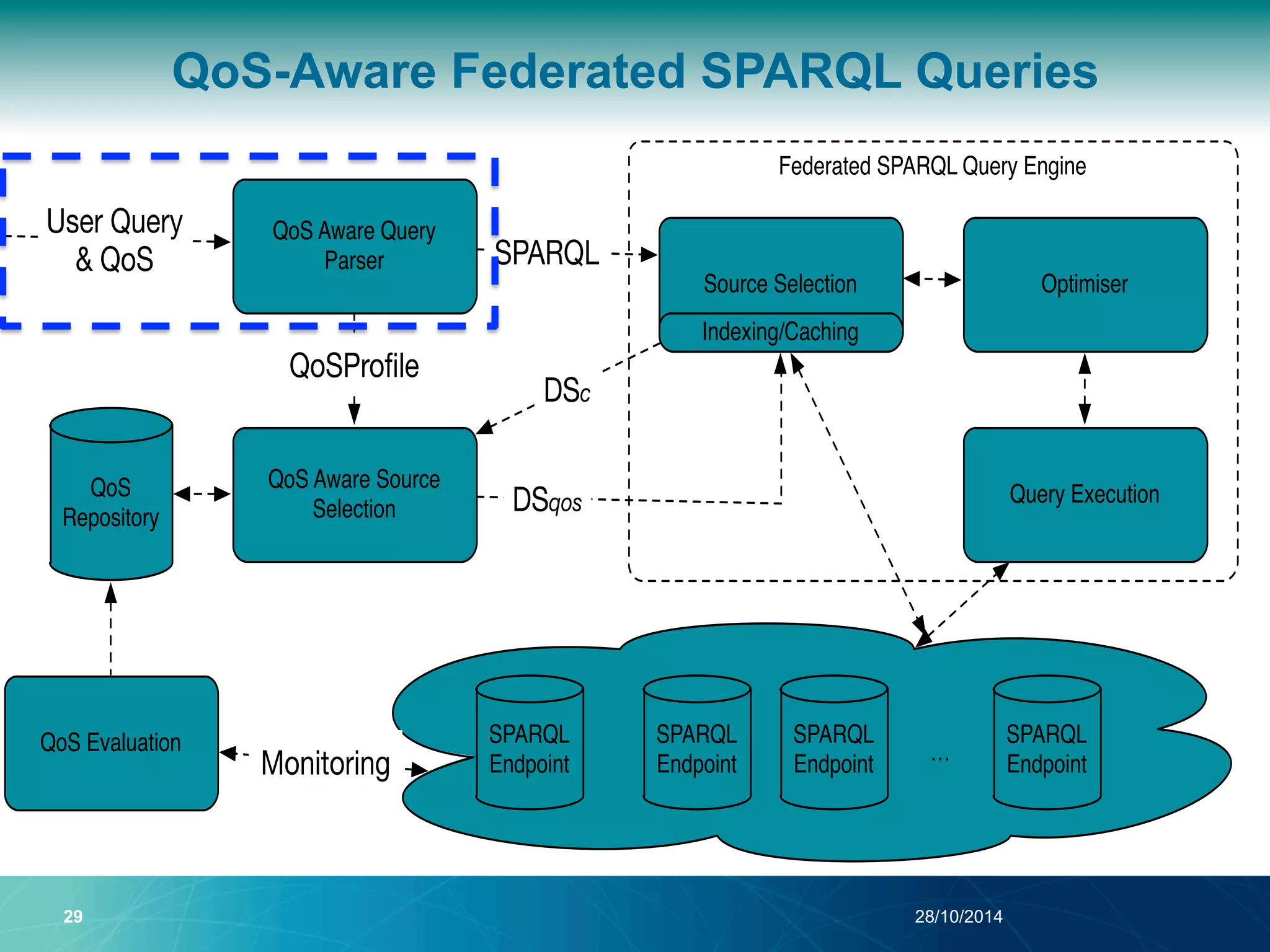
The document discusses a Quality of Service (QoS) aware mechanism for monitoring SPARQL endpoints and selecting data sources for federated SPARQL queries. It highlights the identification and evaluation of various QoS parameters related to SPARQL endpoints, such as performance and data quality, as well as the importance of continuous monitoring. The document also addresses the challenges in automated discovery and execution of SPARQL queries across multiple endpoints while ensuring QoS compliance.



























































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)
