● In feedforward neural network, information always flows in one
direction[forward], from the input nodes to the hidden layers[if any], and then
to output nodes. There are no cycles or loops in the network.
● Decisions are based on current input
● No memory about the past
● No future scope
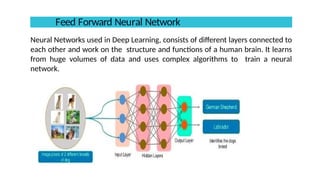
Feed Forward Neural Network
3.
Neural Networks usedin Deep Learning, consists of different layers connected to
each other and work on the structure and functions of a human brain. It learns
from huge volumes of data and uses complex algorithms to train a neural
network.
Feed Forward Neural Network
4.
● Feed forwardNeural Network has several limitations due to architecture:
● Accepts a fixed-sized vector as input (e.g. an image)
● Produces a fixed-sized vector as output (e.g. probabilities of different
classes)
● Performs such input-output mapping used a fixed amount of computational
steps (e.g. the number of layers)
● These limitations make it difficult to model time series problems when
input and output are real-valued sequences.
Feed Forward Neural Network : Limitations
5.
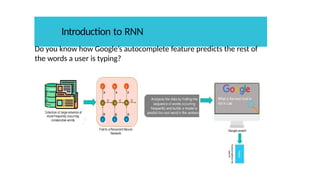
Introduction to RNN
Doyou know how Google’s autocomplete feature predicts the rest of
the words a user is typing?
6.
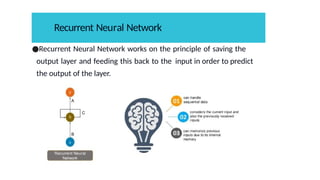
●Recurrent Neural Networkworks on the principle of saving the
output layer and feeding this back to the input in order to predict
the output of the layer.
Recurrent Neural Network
7.
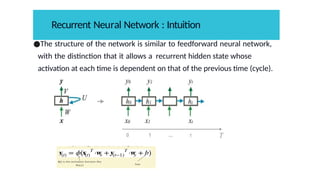
●The structure ofthe network is similar to feedforward neural network,
with the distinction that it allows a recurrent hidden state whose
activation at each time is dependent on that of the previous time (cycle).
Recurrent Neural Network : Intuition
8.
RNN Limitations
● Theproblem with RNNs is that as time passes by and they get fed
more and more new data, they start to “forget” about the previous
data they have seen (vanishing gradient problem), as it gets diluted
between the new data, the transformation from activation function,
and the weight multiplication. This means they have a good short
term memory, but a slight problem when trying to remember things
that have happened a while ago (data they have seen many time steps
in the past).
● The more time steps we have, the more chance we have of
back-propagation gradients either accumulating and exploding
or vanishing down to nothing.


![● In feed forward neural network, information always flows in one
direction[forward], from the input nodes to the hidden layers[if any], and then
to output nodes. There are no cycles or loops in the network.
● Decisions are based on current input
● No memory about the past
● No future scope
Feed Forward Neural Network](https://image.slidesharecdn.com/rnn-new-260206045851-c311eaac/85/Helpfull-for-Data-Analystics-using-Deep-Learning-2-320.jpg)