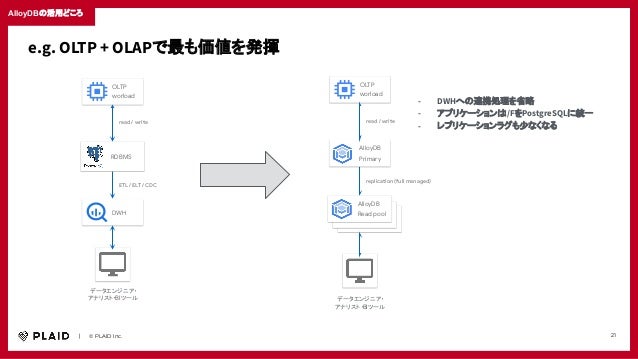
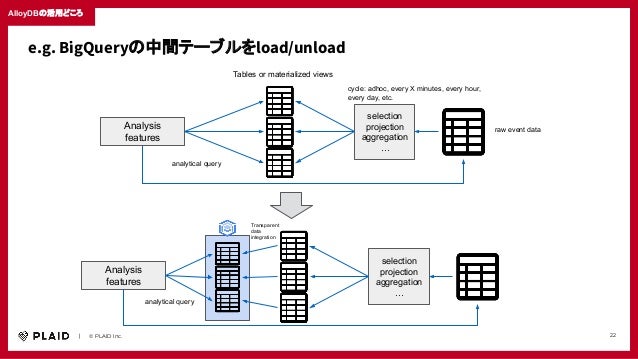
2022/6/8 Data Analytics / Database OnAir https://cloudonair.withgoogle.com/events/solution-data-analytics?talk=0608-3





















































![[db tech showcase Tokyo 2015] B12:カラムストアデータベースの技術と活用法 by 日本電気株式会社 田村稔](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b12infoframe-databoosternec-150618053539-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2014] B33: 超高速データベースエンジンでのビッグデータ分析活用事例 by 株式会社日立製作所 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b33-141127184852-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





