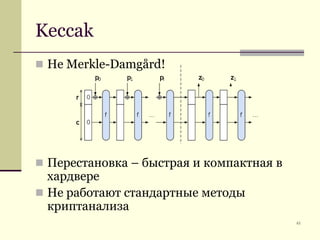
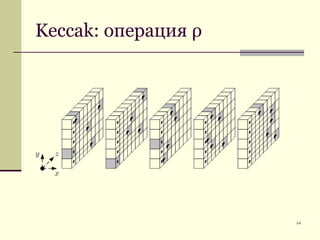
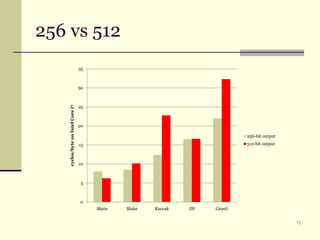
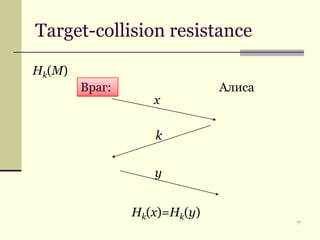
Документ обсуждает криптографические хэш-функции, их конструкции, применения и атаки на них. Основное внимание уделяется стандарту SHA-3 и различным методам, таким как схемы Davies-Meyer и Merkle-Damgård. В документе также представлены примеры применения хэш-функций, включая цифровые подписи и SSL/TLS.