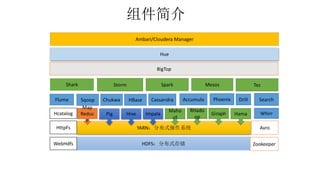
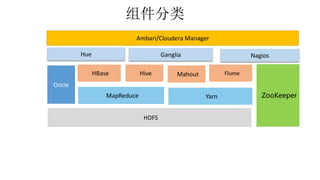
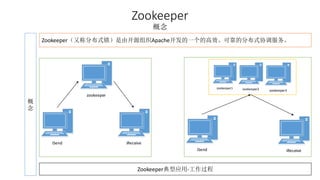
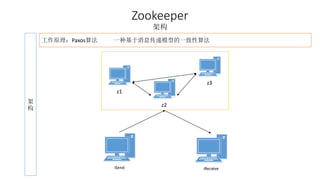
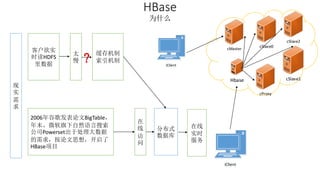
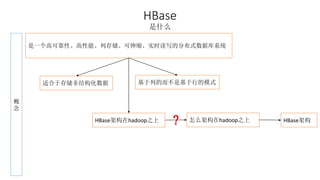
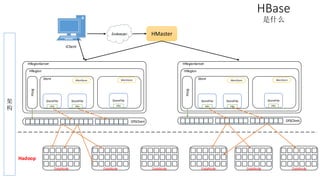
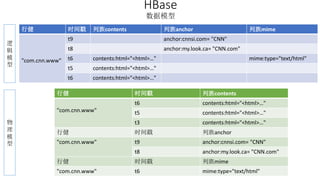
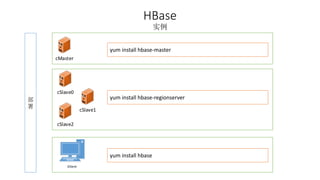
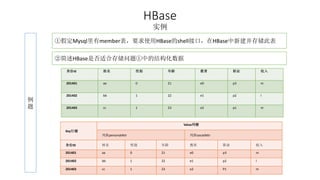
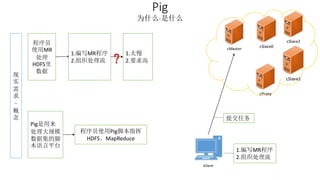
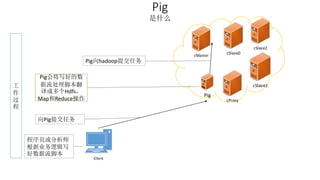
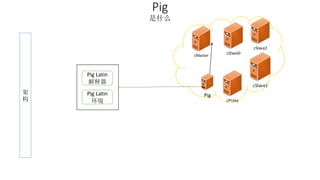
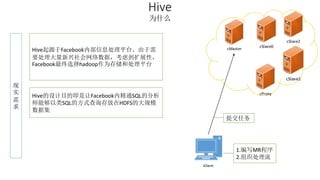
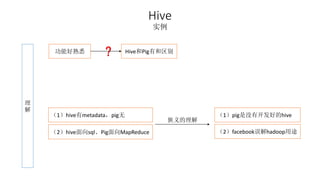
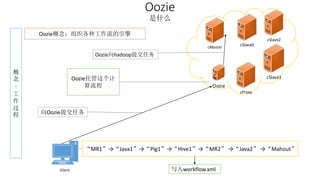
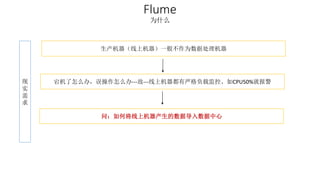
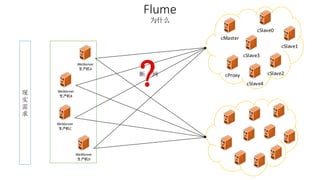
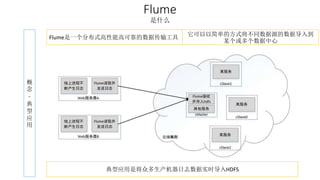
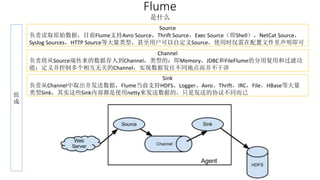
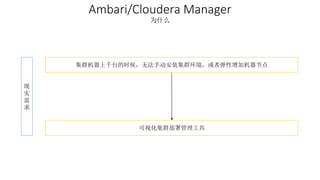
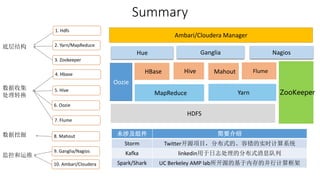
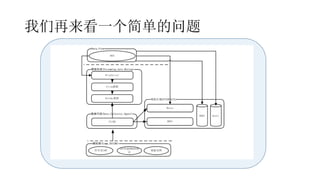
本报告介绍了Hadoop生态圈的架构和组件,包括HDFS、YARN、MapReduce等,并探讨了大数据、云计算和移动互联网等趋势。文中还说明了IBM如何利用先进工具通过分析社交媒体信息来优化产品。总结部分概述了Hadoop的分布式特性、Zookeeper的分布式协调服务及HBase作为高性能数据库系统的应用。


















![参考文献
[1] http://hadoop.apache.org/
[2] http://zookeeper.apache.org/
[3] https://hbase.apache.org/
[4] https://pig.apache.org/
[5] http://hive.apache.org/
[6] https://oozie.apache.org/
[7] http://flume.apache.org/
[8] https://mahout.apache.org/
[9] http://sqoop.apache.org/
[10] http://cassandra.apache.org/
[11] http://avro.apache.org/
[12] http://ambari.apache.org/
[13] https://chukwa.apache.org/
[14] https://hama.apache.org/
[15] https://giraph.apache.org/
[16] http://crunch.apache.org/
[17] https://whirr.apache.org/
[18] http://bigtop.apache.org/
[19] http://hortonworks.com/hadoop/hcatalog/
[20] http://gethue.com/
[21] http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH5/latest/CDH5-Installation-
Guide/CDH5-Installation-Guide.html](https://image.slidesharecdn.com/hadoopecosystem-141112192433-conversion-gate02/85/Hadoop-ecosystem-60-320.jpg)