Google Correlate(TM): Exploring Big "Google Search" Data
•
1 like•596 views

This is an early draft of an article about "Google Correlate" as a free tool enabling access to Google Search search terms as time-series data.
![6/17/2017 Google Correlate(TM): Exploring Big "Google Search" Data
http://scalar.usc.edu/works/c2cdigitalmagazinespringsummer2017/googlecorrelateexploringbiggooglesearchdata?t=1497707738311 2/12
Educational
Technologies
21. Book Review:
Building
Competency-Based
Education in Higher
Education
22. Book Review:
Cultivating
“Classroom Life” in
Real Space
23. Welcome, All:
SIDLIT 2017 Social
Hour!
24. About Colleague
2 Colleague
25. Call for
Submissions: Fall
2017 - Winter 2018
Search
names, formulas, and so on. There is not a limit to a onegram or unigram; in other words, there can be a number of
alphanumeric terms in a particular order that may be explored. Make sure that the Country in the left dropdown menu
is correct (or engage the dropdown if the default “United States” is not correct), and click the “Search correlations”
button at the top.
For this article, “educational technology” was used as the seeding term. In Figure 2, “Top 10 ‘educational technology’
Pairwise Correlations in the U.S. (Google Correlate),” the top 10 correlations may be seen. To the left are the
correlations between the selected seeding search term and the phrase. A 0.9706 is a very high correlation, and that may
be seen in the red and blue lines of the line graph below. In this case, the xaxis is time (2003 – present) in equal
increments. The yaxis represents standard deviations away from the mean (whether higher or lower or right on the
mean). The yaxis shows the normalized search activity so that the respective patterns over time may be legitimately
compared. (Raw counts would show similar changes over time patternwise, but they would result in large gaps between
the lines in the line graph depending on the volume of the two datasets being compared. Normalizing would show how
far off the mean an aggregated query count is for a particular time period—either weekly or monthly—and this allows
the yaxis to have a smaller range of possible values for clearer expressions of the correlations.) [Note: As a reminder,
correlations are reflected as a number from 1 to +1. If r=0, there is no observable correlation between the two
variables. If r = 1, there is a perfect positive correlation between the two variables. A correlation coefficient or rscore
shows the statistical relationship between two variables. Sometimes, this coefficient is referred to as the “Pearson
productmoment correlation coefficient” or “Pearson’s r.” Google Correlate only shows positive correlations, and they
show the search terms with the highest correlation coefficients with the target seeding terms and then others in
descending correlation order.] For more about “Standard_score,” please see the following article on Wikipedia.
In other words, when people search “educational technology” over time from 2003 to the present, “education research”
has the closest data pattern over time in Google Search. The next most highly correlated pattern is “technology,” then
“abstracts,” “educational research,” “information systems,” “c++,” “research journal,” “ecommerce,” “biotechnology,”
and “dissertations.”
Figure 2: Top 10 “educational technology” Pairwise Correlations in the U.S. (Google Correlate)
From the same data, it is possible to have Google Correlate draw a scatterplot. Note that the xaxis of the scatterplot
represents “educational technology,” and the yaxis represents “education research.” The bottom left quadrant
contains the lessthanaverage adjusted counts for the particular observed week. The mapping of the two sets of dots is
to enable the visual analysis of whether the dots cluster and if it is possible to draw a line of best fit through the dots to
see if there is an association between the variable represented on the xaxis and the one on the yaxis. The normalized
data has the mean (μ for full population means, and x̅ for means of samples of populations) at zero for both sets. The
placed dots show where the respective aggregate queries land (in terms of standard deviations from the mean) from the
two sets. The diagonal line of best fit is drawn through the data to see if there may be a linear correlation between
“educational technology” (on the xaxis) and “education research” on the yaxis. In Figure 3, the scatter plot shows a
very high correlation, both in the r and the fit to the diagonal line.
View Recent
Top 10 “educational technology” Pairwise Correlations in the U.S. Annotations
Details](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommended
More Related Content
Similar to Google Correlate(TM): Exploring Big "Google Search" Data
Similar to Google Correlate(TM): Exploring Big "Google Search" Data (20)
More from Shalin Hai-Jew
More from Shalin Hai-Jew (20)
Recently uploaded
Recently uploaded (20)
Google Correlate(TM): Exploring Big "Google Search" Data
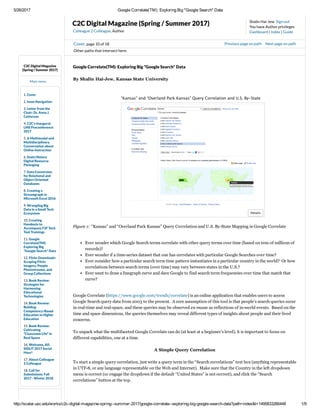
- 1. 6/17/2017 Google Correlate(TM): Exploring Big "Google Search" Data http://scalar.usc.edu/works/c2cdigitalmagazinespringsummer2017/googlecorrelateexploringbiggooglesearchdata?t=1497707738311 1/12 Shalin Hai-Jew Sign out You have Author privileges Dashboard | Index | Guide C2C Digital Magazine (Spring / Summer 2017) Colleague 2 Colleague, Author C2C Digital Magazine (Spring / Summer 2017) 1. Cover 2. Issue Navigation 3. Letter from the Chair: Dr. Anna J. Catterson 4. Discover, Connect & Engage: SIDLIT 2017 5. C2C's Inaugural LMS Preconference 2017 6. A Multimodal and Multidisciplinary Conversation about Online Instruction 7. State History Digital Resource Packaging 8. Sentiment Analysis of Real-Time Twitter Data 9. Data Conversion for Relational and Object Oriented Databases 10. Using iMovie to Inspire Creative Top- Notch Projects in the Classroom 11. How Do You Know What You Don’t Know? 12. Affective Computing 13. Using the Content Collection in Blackboard for Course Development 14. "It’s Not Politics; It's Technology, Stupid" 15. Creating a Streamgraph in Microsoft Excel 2016 16. Wrangling Big Data in a Small Tech Ecosystem 17. Creating Handouts to Accompany F2F Tech Tool Trainings 18. Google Correlate(TM): Exploring Big "Google Search" Data 19. Flickr Downloadr: Scraping Flickr Imagery, People Photostreams, and Group Collections 20. Book Review: Strategies for Harnessing Other paths that intersect here: Issue Navigation, page 16 of 23 Previous page on path Next page on path Google Correlate(TM): Exploring Big "Google Search" Data By Shalin HaiJew, Kansas State University Figure 1: “Kansas” and “Overland Park Kansas” Query Correlation and U.S. ByState Mapping in Google Correlate Ever wonder which Google Search terms correlate with other query terms over time (based on billions of records)? Ever wonder if a timeseries dataset that one has correlates with particular Google Searches over time? Ever consider how a particular search term time pattern instantiates in a particular country in the world? Or how correlations between search terms (over time) may vary between states in the U.S.? Ever want to draw a linegraph curve and dare Google to find search term frequencies over time that match that curve? Google Correlate (https://www.google.com/trends/correlate) is an online application that enables users to access Google Search query data from 2003 to the present (with up to a week's lag). A core assumption of this tool is that people’s search queries occur in realtime and realspace, and these queries may be observed en masse as reflections of inworld events. Based on the time and space dimensions, the queries themselves may reveal different types of insights about people and their lived concerns. How search terms vary in frequency over time shows times of heightened interest for particular terms as well as times of lessened interest for particular terms. This data variability over time may provide insights about inworld phenomena as well as population interests. To unpack what the multifaceted Google Correlate can do (at least at a beginner’s level), it is important to focus on different capabilities, one at a time. A Simple Query Correlation To start a simple query correlation, just write a query term in the “Search correlations” text box (anything representable in UTF8, or any language representable on the Web and Internet). The search terms may be phrases, sentences, Main menu “Kansas” and “Overland Park Kansas” Query Correlation and U.S. By-State Annotations Details
- 2. 6/17/2017 Google Correlate(TM): Exploring Big "Google Search" Data http://scalar.usc.edu/works/c2cdigitalmagazinespringsummer2017/googlecorrelateexploringbiggooglesearchdata?t=1497707738311 2/12 Educational Technologies 21. Book Review: Building Competency-Based Education in Higher Education 22. Book Review: Cultivating “Classroom Life” in Real Space 23. Welcome, All: SIDLIT 2017 Social Hour! 24. About Colleague 2 Colleague 25. Call for Submissions: Fall 2017 - Winter 2018 Search names, formulas, and so on. There is not a limit to a onegram or unigram; in other words, there can be a number of alphanumeric terms in a particular order that may be explored. Make sure that the Country in the left dropdown menu is correct (or engage the dropdown if the default “United States” is not correct), and click the “Search correlations” button at the top. For this article, “educational technology” was used as the seeding term. In Figure 2, “Top 10 ‘educational technology’ Pairwise Correlations in the U.S. (Google Correlate),” the top 10 correlations may be seen. To the left are the correlations between the selected seeding search term and the phrase. A 0.9706 is a very high correlation, and that may be seen in the red and blue lines of the line graph below. In this case, the xaxis is time (2003 – present) in equal increments. The yaxis represents standard deviations away from the mean (whether higher or lower or right on the mean). The yaxis shows the normalized search activity so that the respective patterns over time may be legitimately compared. (Raw counts would show similar changes over time patternwise, but they would result in large gaps between the lines in the line graph depending on the volume of the two datasets being compared. Normalizing would show how far off the mean an aggregated query count is for a particular time period—either weekly or monthly—and this allows the yaxis to have a smaller range of possible values for clearer expressions of the correlations.) [Note: As a reminder, correlations are reflected as a number from 1 to +1. If r=0, there is no observable correlation between the two variables. If r = 1, there is a perfect positive correlation between the two variables. A correlation coefficient or rscore shows the statistical relationship between two variables. Sometimes, this coefficient is referred to as the “Pearson productmoment correlation coefficient” or “Pearson’s r.” Google Correlate only shows positive correlations, and they show the search terms with the highest correlation coefficients with the target seeding terms and then others in descending correlation order.] For more about “Standard_score,” please see the following article on Wikipedia. In other words, when people search “educational technology” over time from 2003 to the present, “education research” has the closest data pattern over time in Google Search. The next most highly correlated pattern is “technology,” then “abstracts,” “educational research,” “information systems,” “c++,” “research journal,” “ecommerce,” “biotechnology,” and “dissertations.” Figure 2: Top 10 “educational technology” Pairwise Correlations in the U.S. (Google Correlate) From the same data, it is possible to have Google Correlate draw a scatterplot. Note that the xaxis of the scatterplot represents “educational technology,” and the yaxis represents “education research.” The bottom left quadrant contains the lessthanaverage adjusted counts for the particular observed week. The mapping of the two sets of dots is to enable the visual analysis of whether the dots cluster and if it is possible to draw a line of best fit through the dots to see if there is an association between the variable represented on the xaxis and the one on the yaxis. The normalized data has the mean (μ for full population means, and x̅ for means of samples of populations) at zero for both sets. The placed dots show where the respective aggregate queries land (in terms of standard deviations from the mean) from the two sets. The diagonal line of best fit is drawn through the data to see if there may be a linear correlation between “educational technology” (on the xaxis) and “education research” on the yaxis. In Figure 3, the scatter plot shows a very high correlation, both in the r and the fit to the diagonal line. View Recent Top 10 “educational technology” Pairwise Correlations in the U.S. Annotations Details
- 3. 6/17/2017 Google Correlate(TM): Exploring Big "Google Search" Data http://scalar.usc.edu/works/c2cdigitalmagazinespringsummer2017/googlecorrelateexploringbiggooglesearchdata?t=1497707738311 3/12 Figure 3: “educational technology” and “education research” as a Scatter Plot (Google Correlate) To showcase how this information may be intriguing, it is possible to run the same query at the same period (within the week, with weeks starting on Sunday at midnight Pacific Standard Time), albeit for a different country, like Australia. The results of this may be seen in Figures 4 and 5. Figure 4: “educational technology” and “managing” Line Graph over Time for Australia (Google Correlate) “educational technology” and “education research” as a Scatter Plot Annotations Details “educational technology” and “managing” Line Graph over Time for Annotations Details “educational technology” and “managing” Scatter Plot for Australia Annotations
- 7. 6/17/2017 Google Correlate(TM): Exploring Big "Google Search" Data http://scalar.usc.edu/works/c2cdigitalmagazinespringsummer2017/googlecorrelateexploringbiggooglesearchdata?t=1497707738311 7/12 Figure 9: “Search by Drawing” Feature…Leads to “Ruby Rails” in the U.S. as the Top Correlate with the Drawn Curve (Google Correlate) To provide a sense of how some other drawn curves may look and how closely the found data may fit, two additional figures are included. Figure 10: Drawn Time Series Curve with a Serious Dip in 2015 (Google Correlate) Details Drawn Series with "Crash" in 2015 Annotations Details Drawn Series with Spikes in 2005 and 2008 ("Search by Annotations
- 12. 6/17/2017 Google Correlate(TM): Exploring Big "Google Search" Data http://scalar.usc.edu/works/c2cdigitalmagazinespringsummer2017/googlecorrelateexploringbiggooglesearchdata?t=1497707738311 12/12 • More Version 33 of this page, updated 17 June 2017. C2C Digital Magazine (Spring / Summer 2017) by Colleague 2 Colleague. Help reading this book. Powered by Scalar. Terms of Service | Privacy Policy | Scalar Feedback New Edit Hide Comment on this page Previous page on path Issue Navigation, page 16 of 23 Next page on path Nearest Neighbor Search in Google Correlate https://www.google.com/trends/correlate/nnsearch.pdf Search by Drawing (in Google Correlate) https://www.google.com/trends/correlate/draw About the Author Shalin HaiJew works as an instructional designer at Kansas State University. Her email is shalin@kstate.edu. Related: (No related content) web search forecasting Google Search web search activity human sensor network surveillance Google Correlate time-series data