Downloaded 67 times






![9
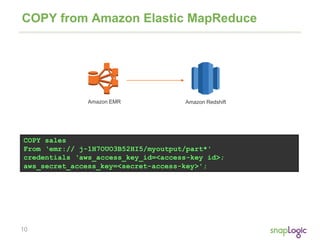
COPY from JSON
{
"jsonpaths":
[
"$['id']",
"$['name']",
"$['location'][0]",
"$['location'][1]",
"$['seats']"
]
}
COPY venue FROM 's3://mybucket/venue.json'
credentials 'aws_access_key_id=<access-key-id>; aws_secret_access_key=<secret-
access-key>'
JSON AS 's3://mybucket/venue_jsonpaths.json';](https://image.slidesharecdn.com/snaplogicwebinarforredshiftmay2014v6-3-140507142049-phpapp01/85/Best-Practices-for-Supercharging-Cloud-Analytics-on-Amazon-Redshift-9-320.jpg)
![11
REGEX_SUBSTR()
select email, regexp_substr(email,'@[^.]*')
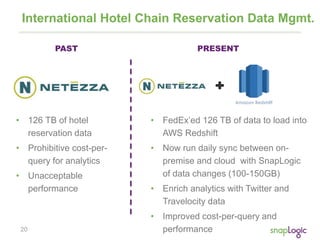
from users limit 5;
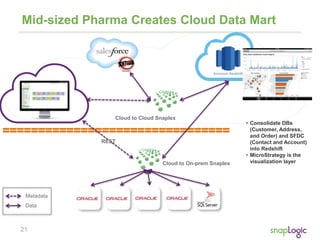
email | regexp_substr
--------------------------------------------+----------------
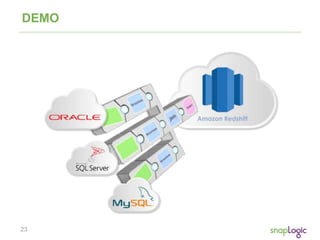
Suspendisse.tristique@nonnisiAenean.edu | @nonnisiAenean
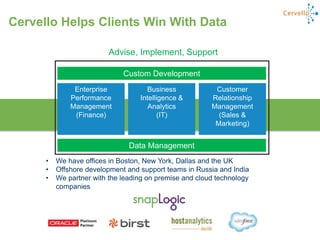
sed@lacusUtnec.ca | @lacusUtnec
elementum@semperpretiumneque.ca | @semperpretiumneque
Integer.mollis.Integer@tristiquealiquet.org | @tristiquealiquet
Donec.fringilla@sodalesat.org | @sodalesat](https://image.slidesharecdn.com/snaplogicwebinarforredshiftmay2014v6-3-140507142049-phpapp01/85/Best-Practices-for-Supercharging-Cloud-Analytics-on-Amazon-Redshift-11-320.jpg)


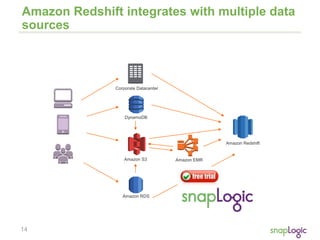

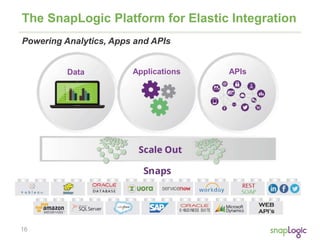
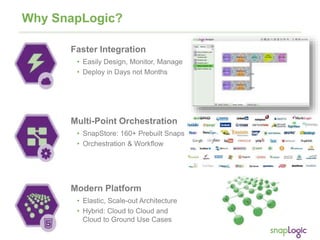

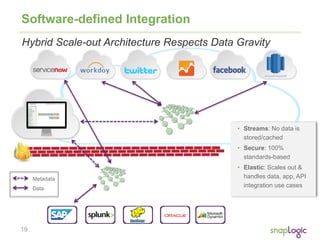


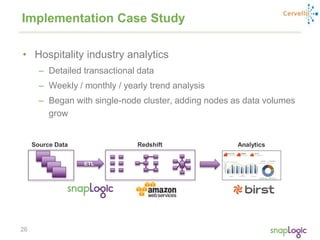
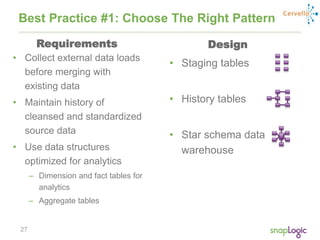

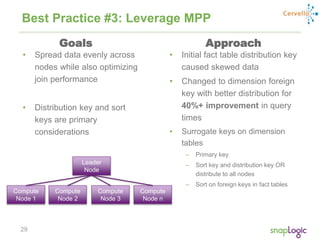





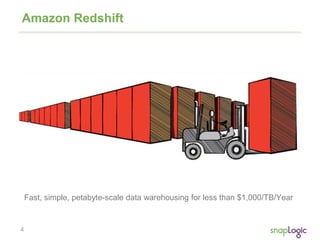
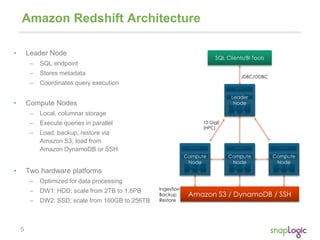
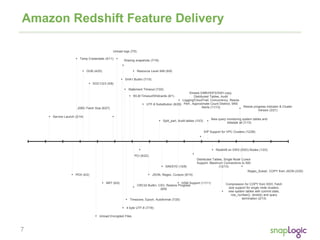
The document discusses best practices for optimizing cloud analytics on Amazon Redshift, covering its architecture, pricing, and key features. It highlights case studies demonstrating successful implementations and suggests best practices for data management, node selection, and performance optimization. Additionally, it promotes SnapLogic's integration platform as a solution for enhancing analytics and data integration processes.


































![[よくわかるAmazon Redshift]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140219redshiftupdatesv1tokyo-140224010117-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[よくわかるAmazon Redshift in 大阪]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140221redshiftupdatesv2osaka-140224010309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


















































