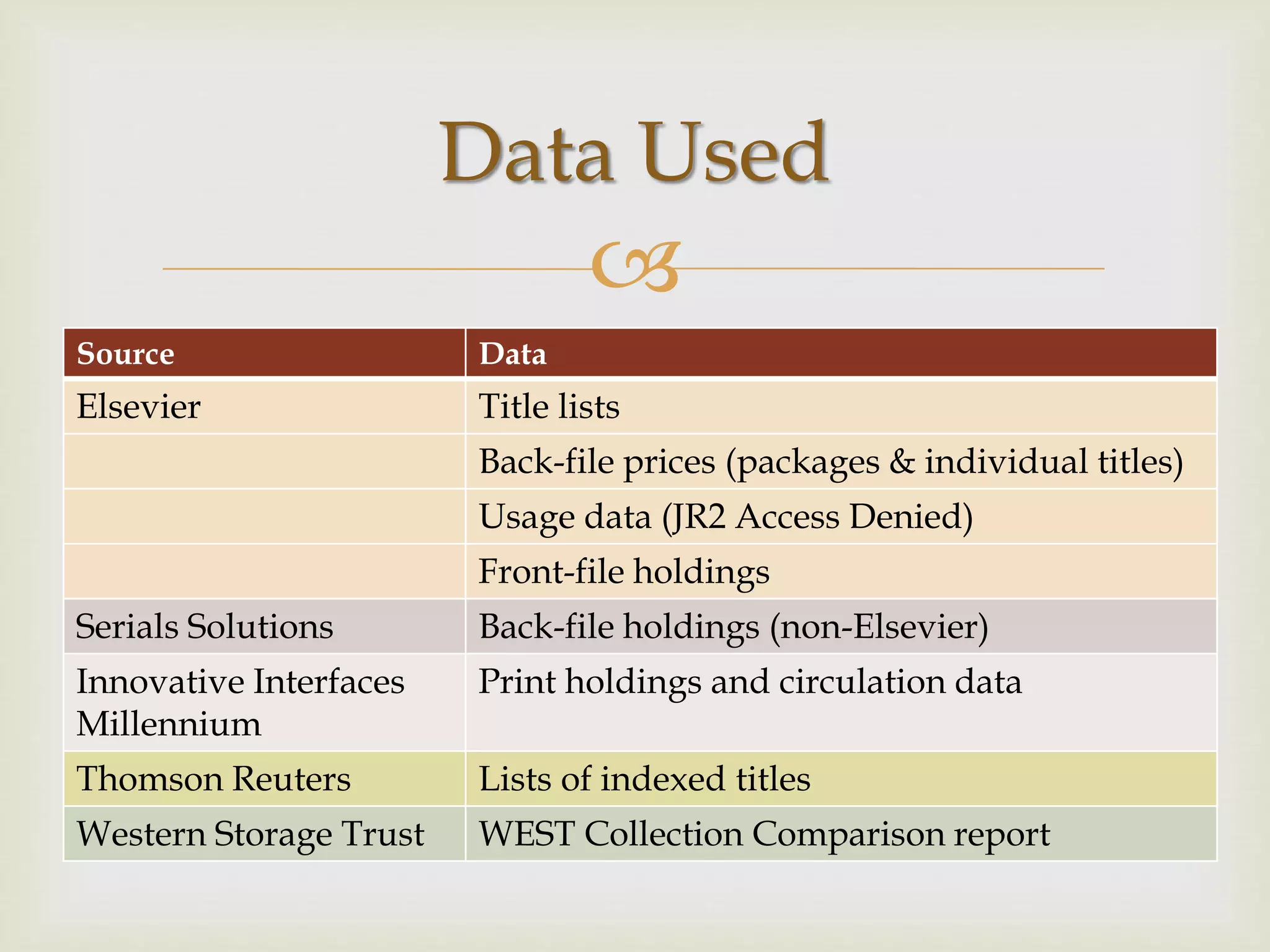
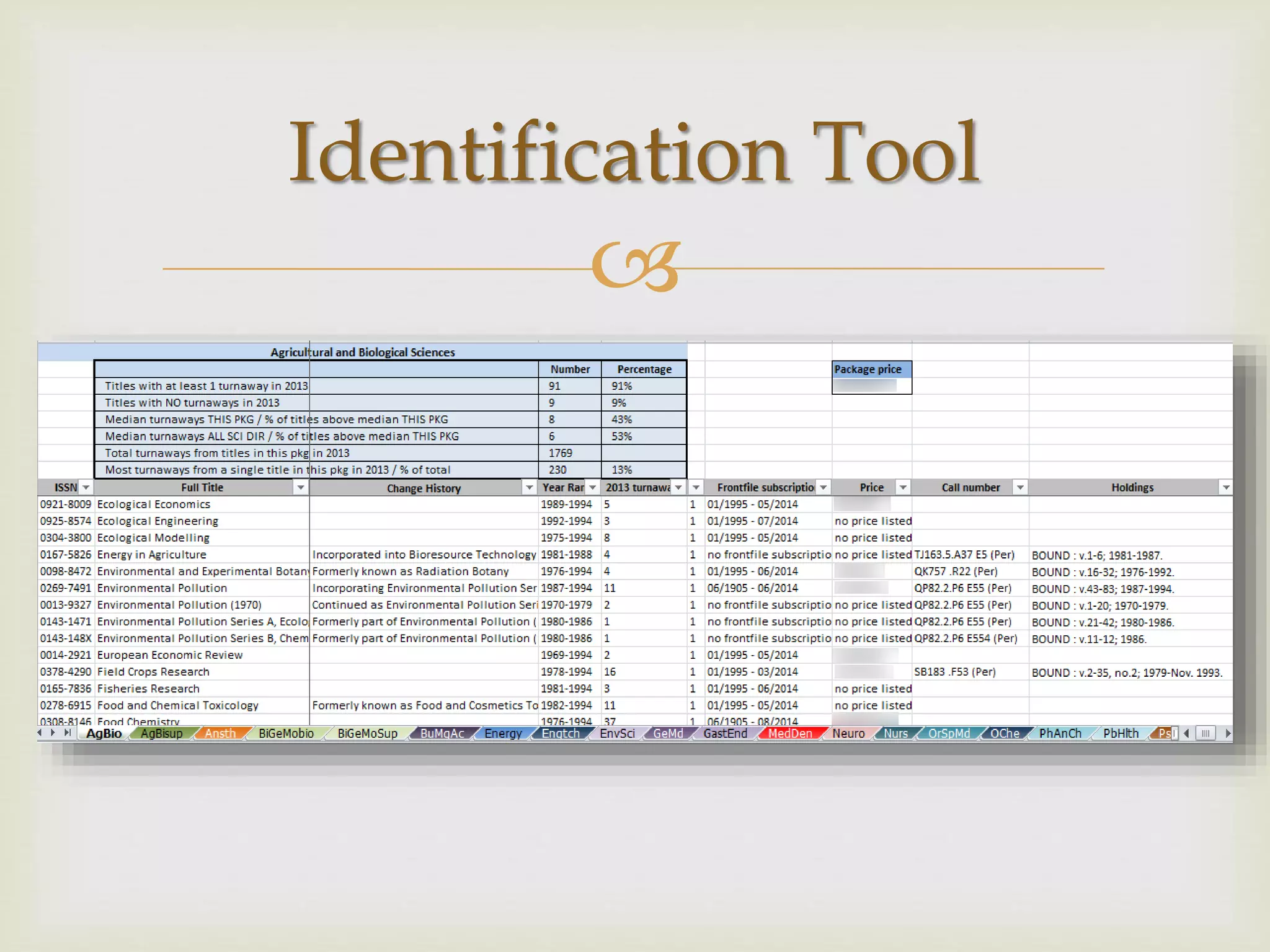
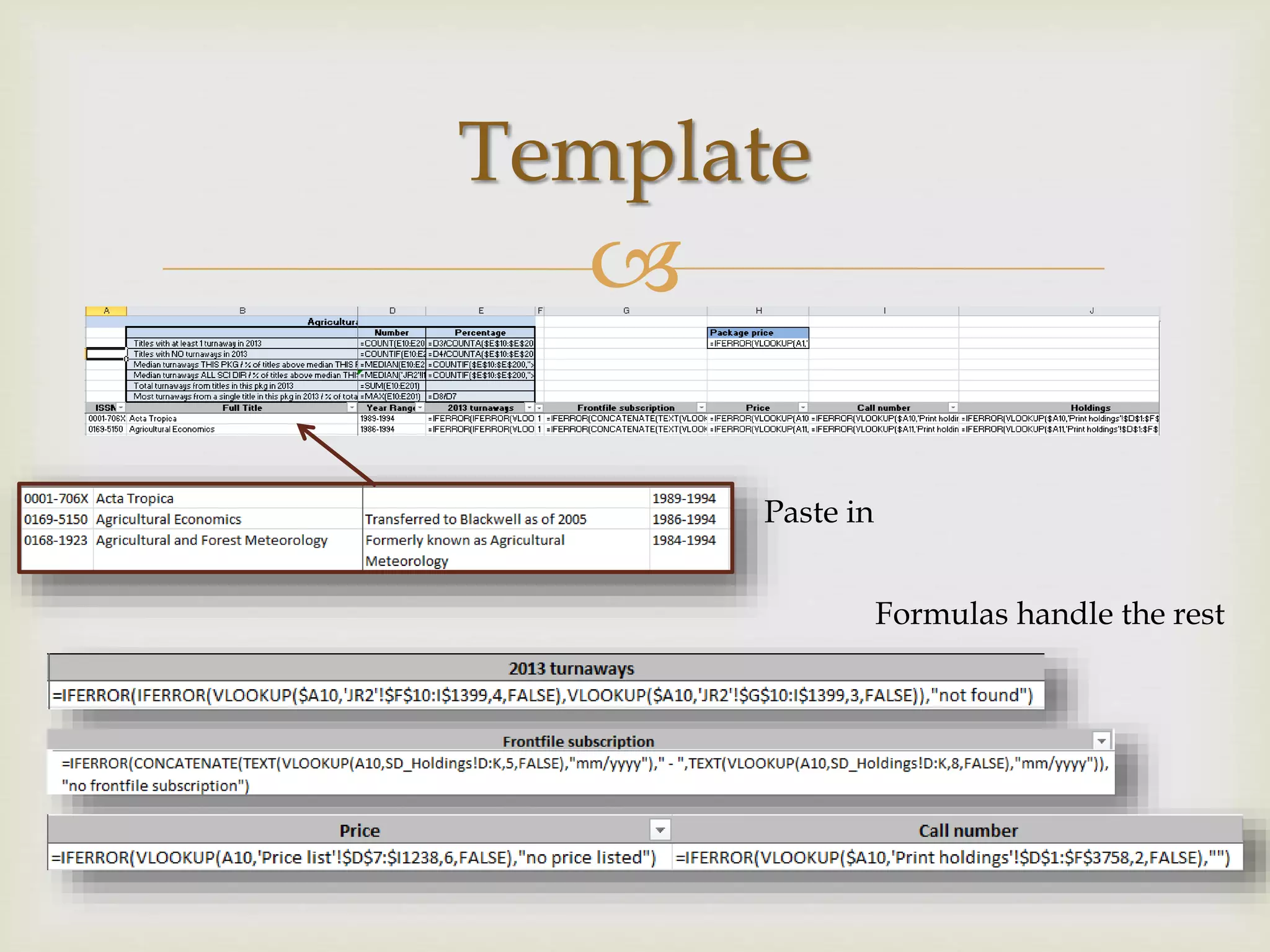
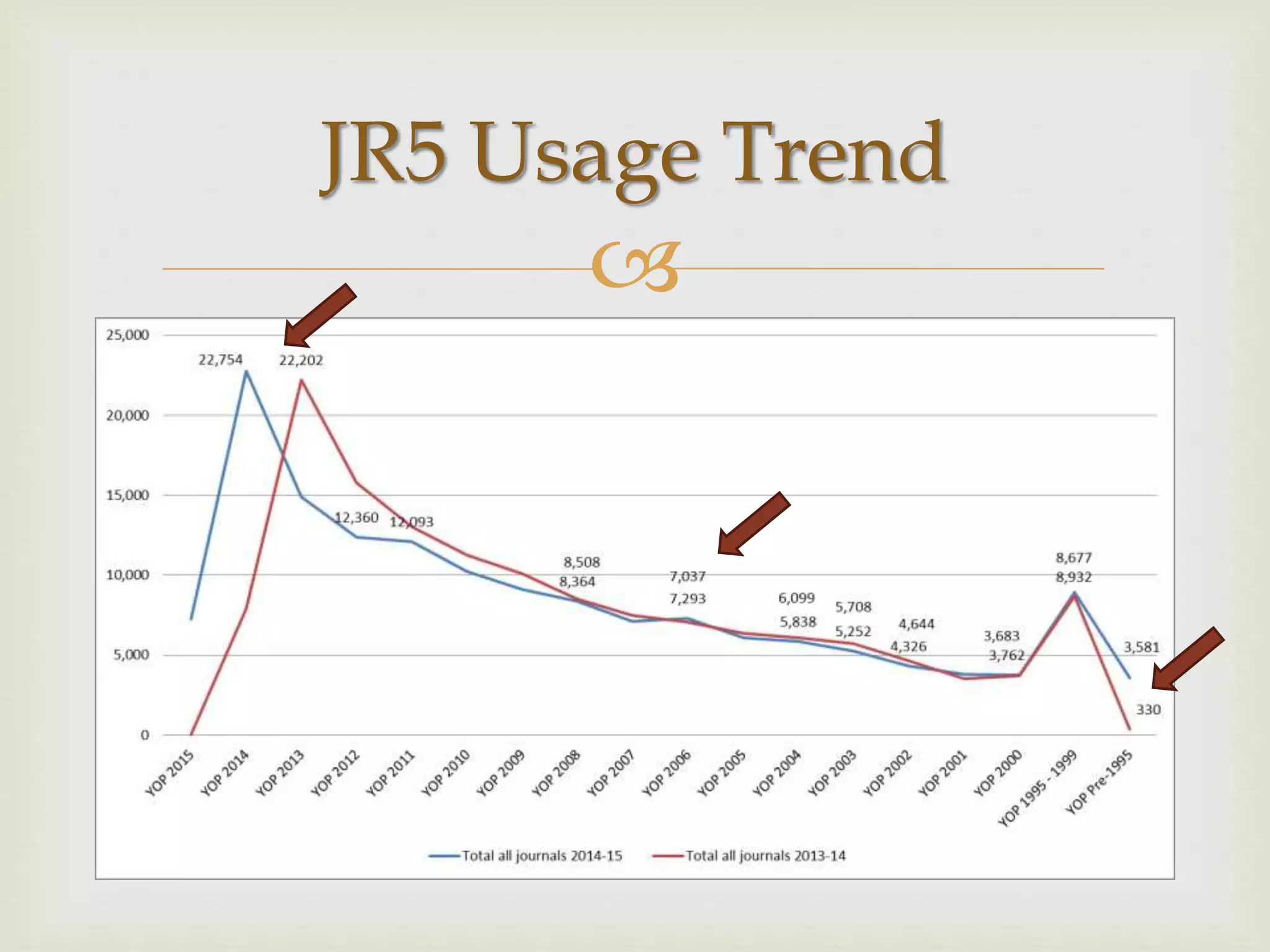
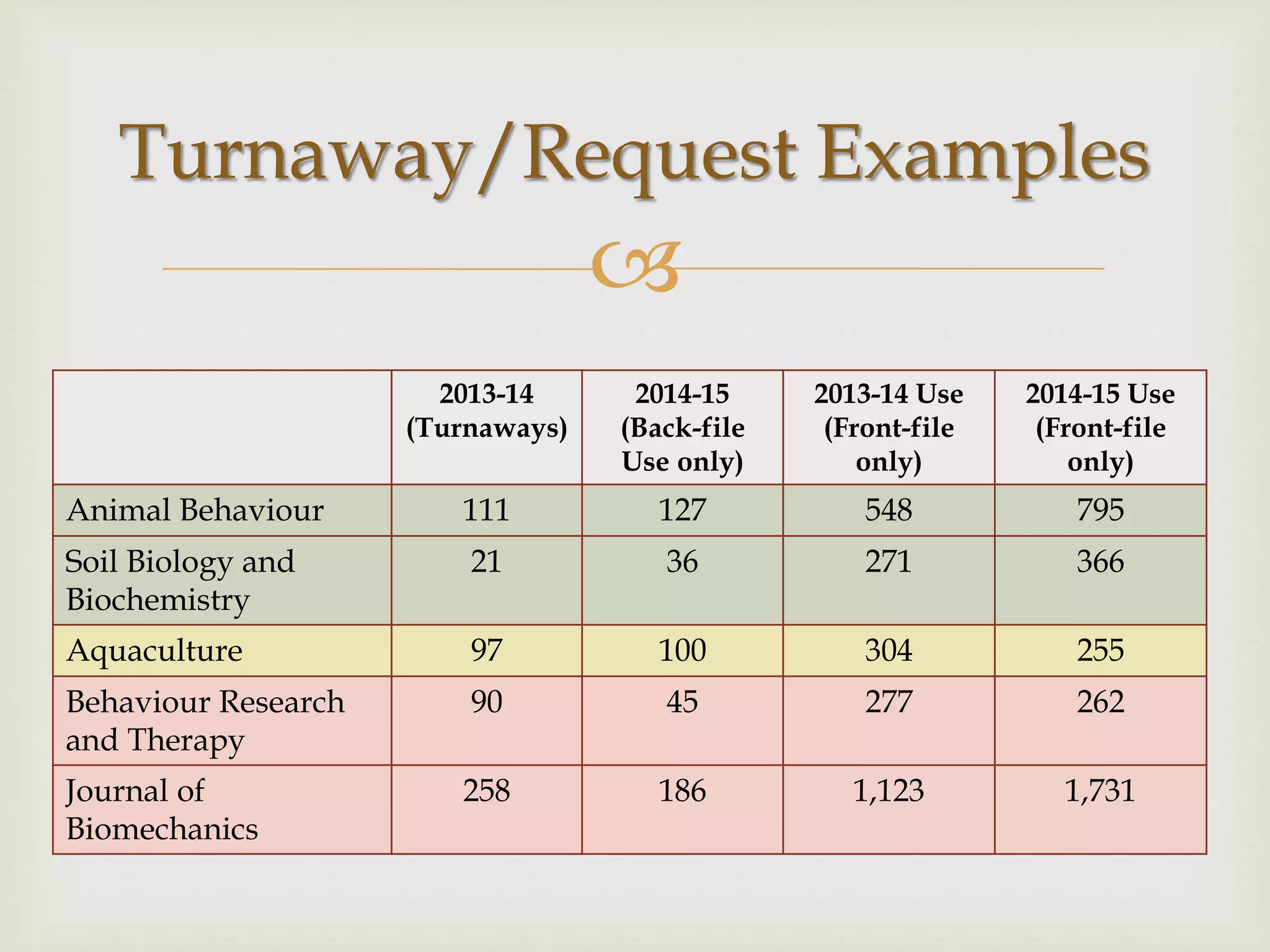
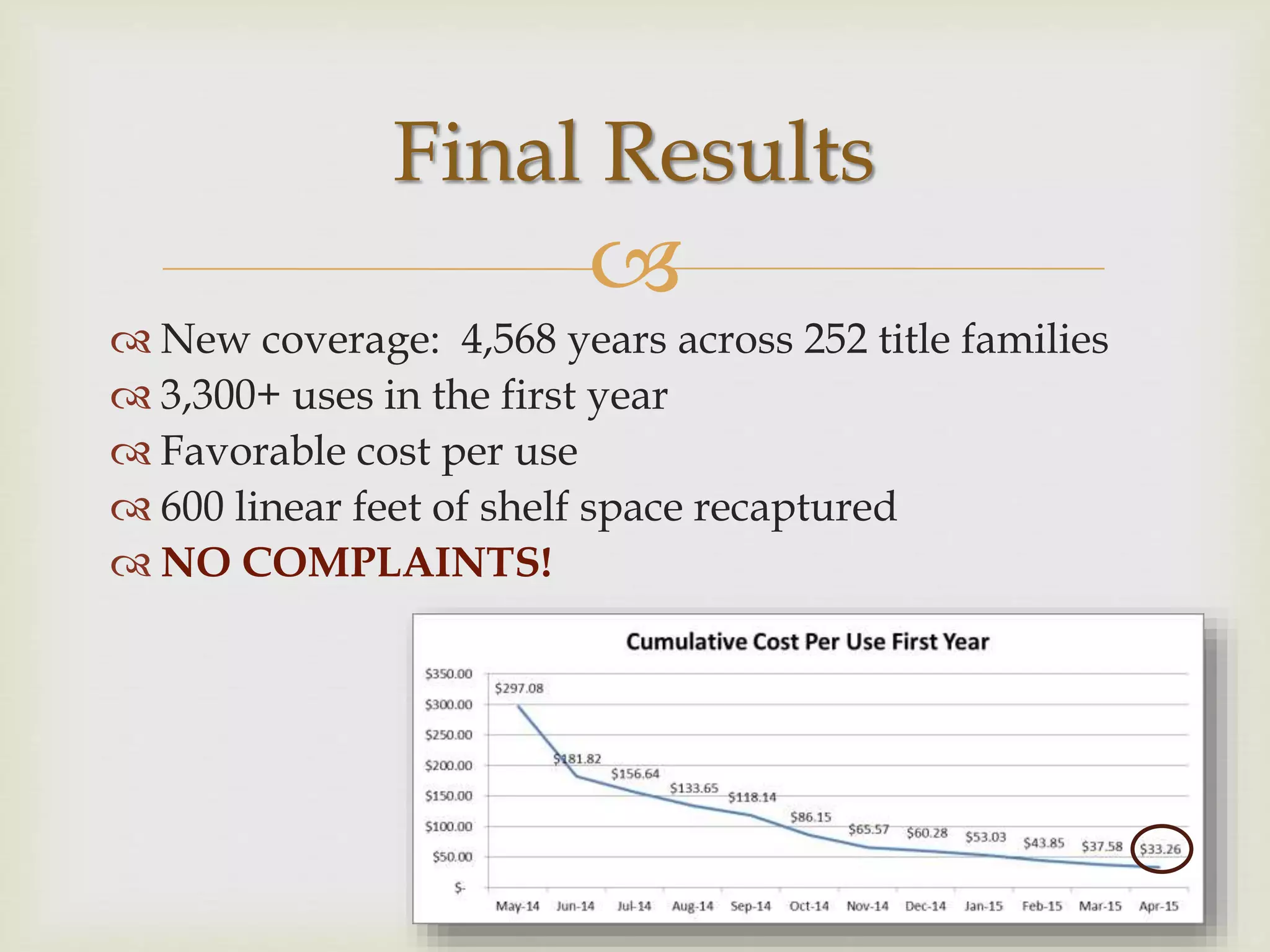
The document outlines California Polytechnic State University's approach to optimizing library space by transitioning from print to electronic resources, particularly through analyzing turnaway data from their electronic collection. Key goals included increasing accessibility, improving resource management, and repurposing space while ensuring budget compliance and user needs were met. The project led to a significant increase in back-file usage and the recapture of over 600 linear feet of shelf space, aiming to enhance collaboration and resource sharing on campus.