Download to read offline













 26](https://image.slidesharecdn.com/andreaacumencopenhagen20130308-130313184807-phpapp01/75/Genericity-versus-expressivity-reflections-about-the-semantics-of-interoperable-research-information-systems-26-2048.jpg)
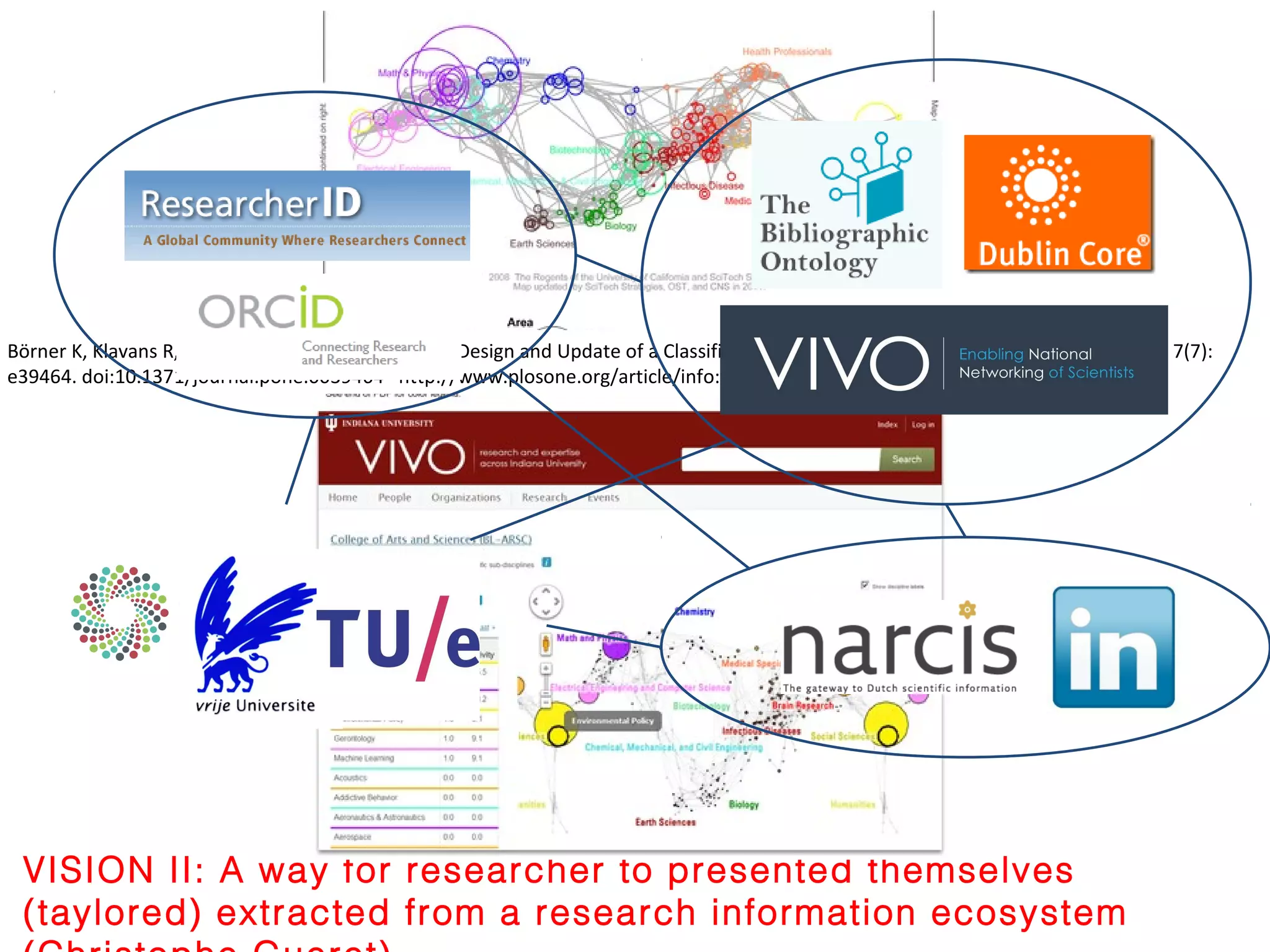


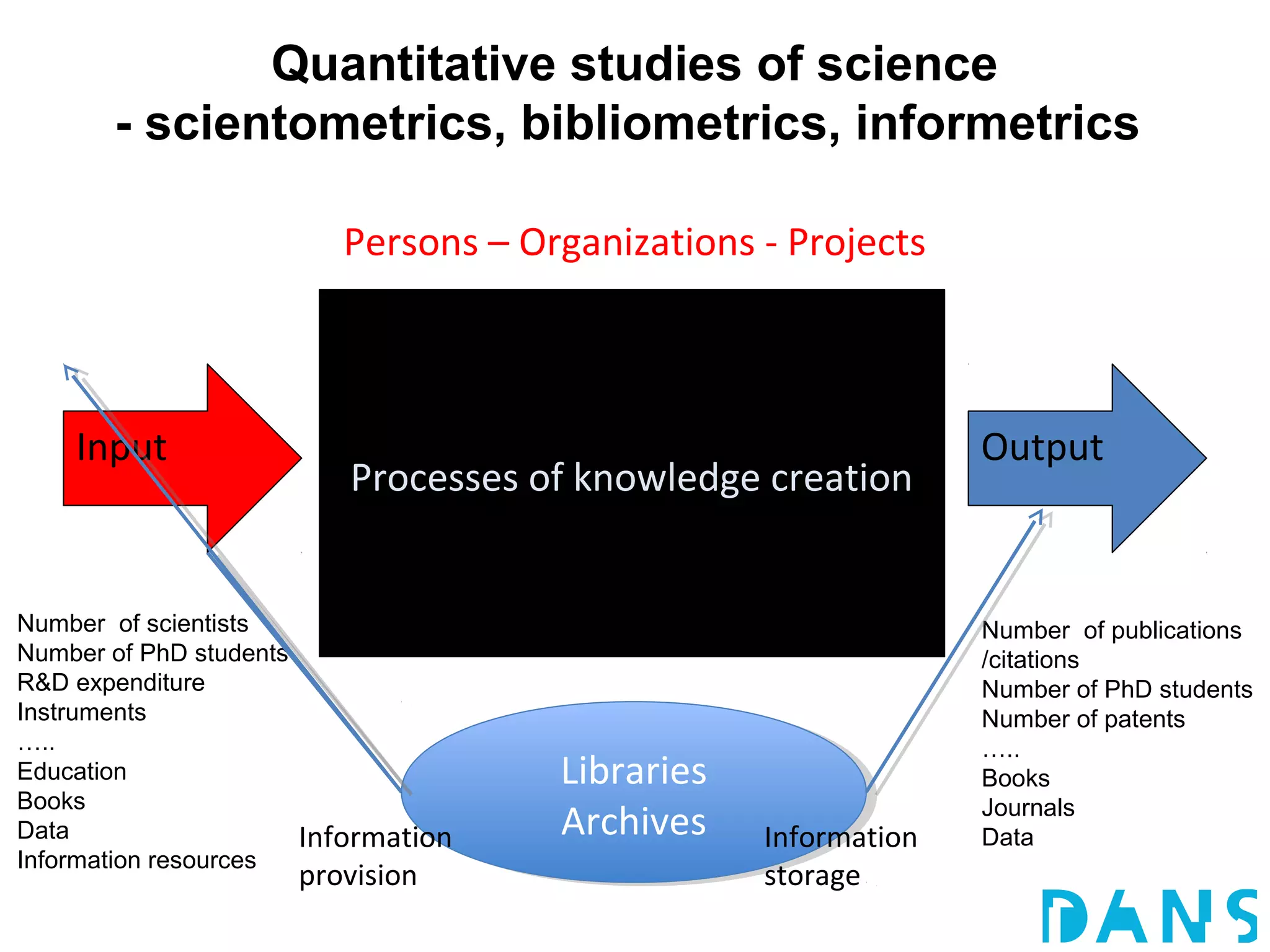
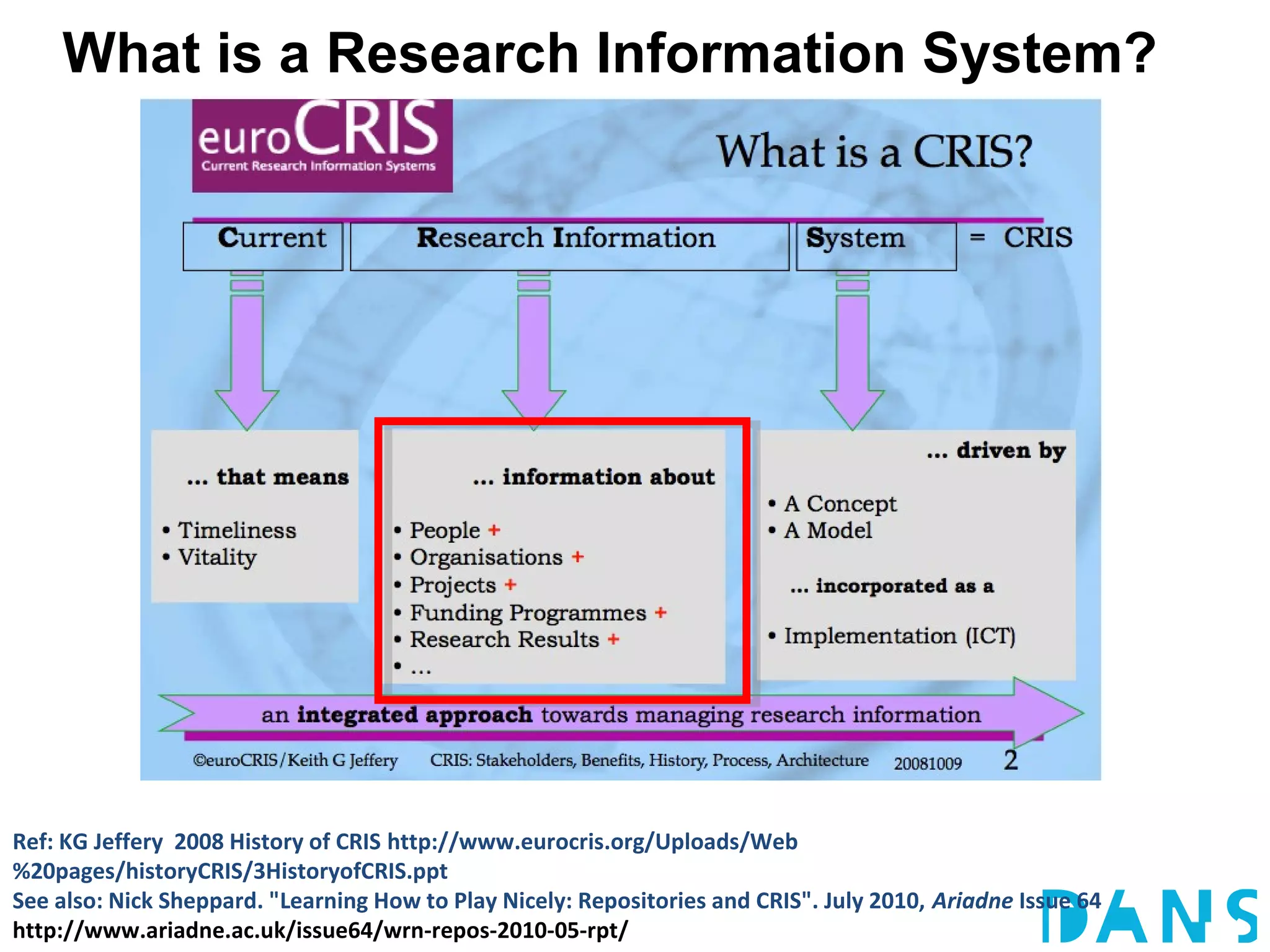
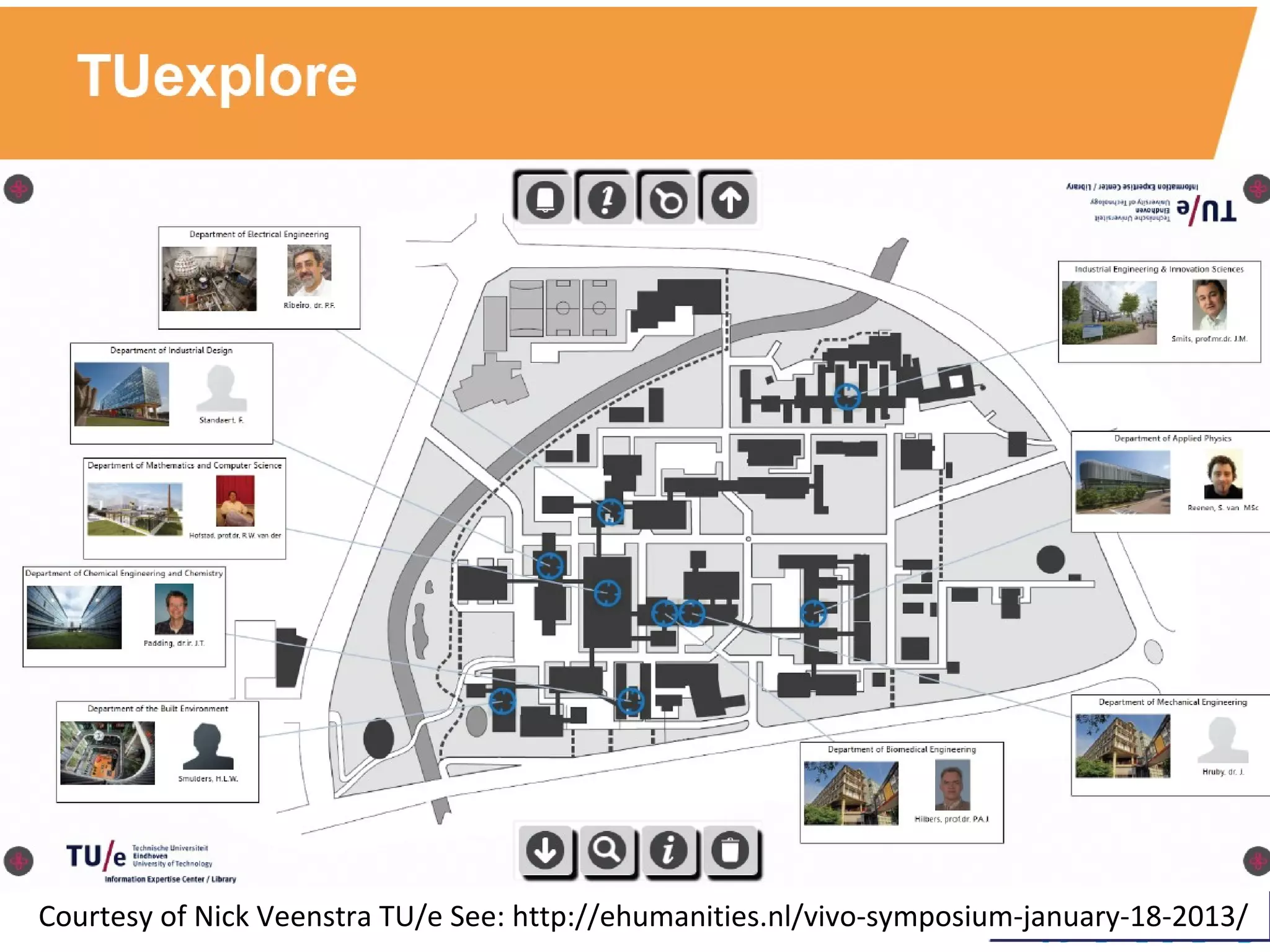
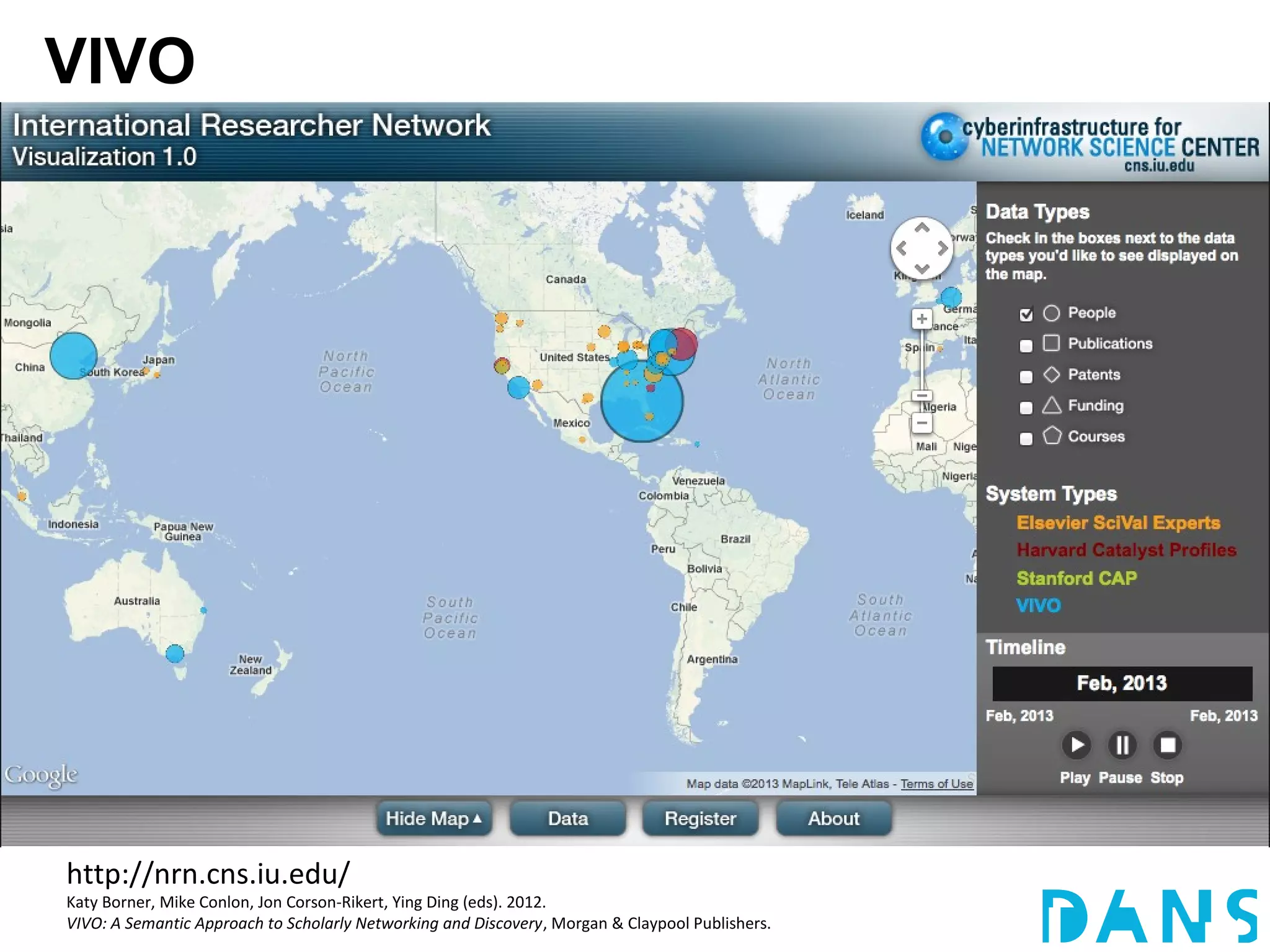
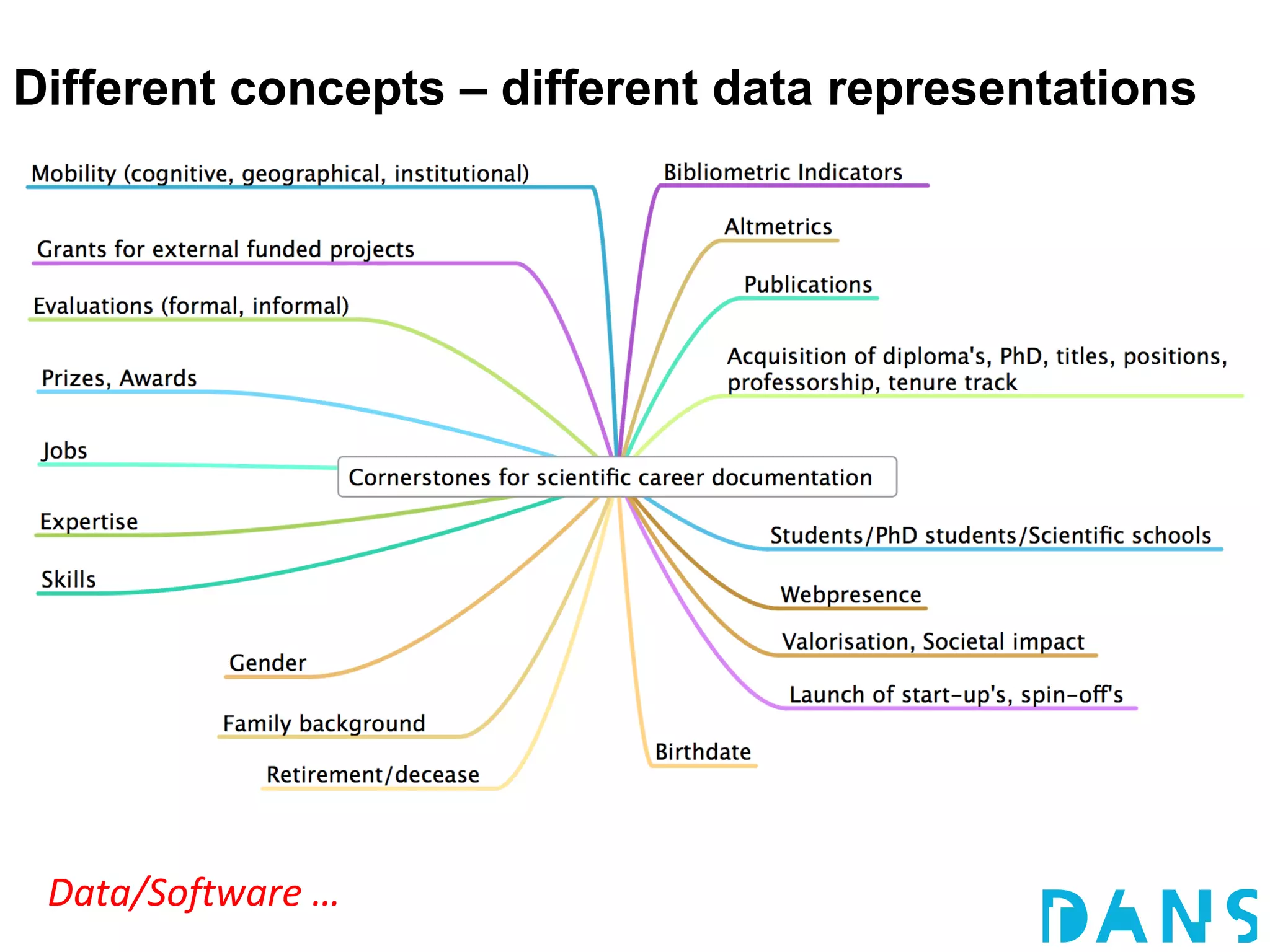
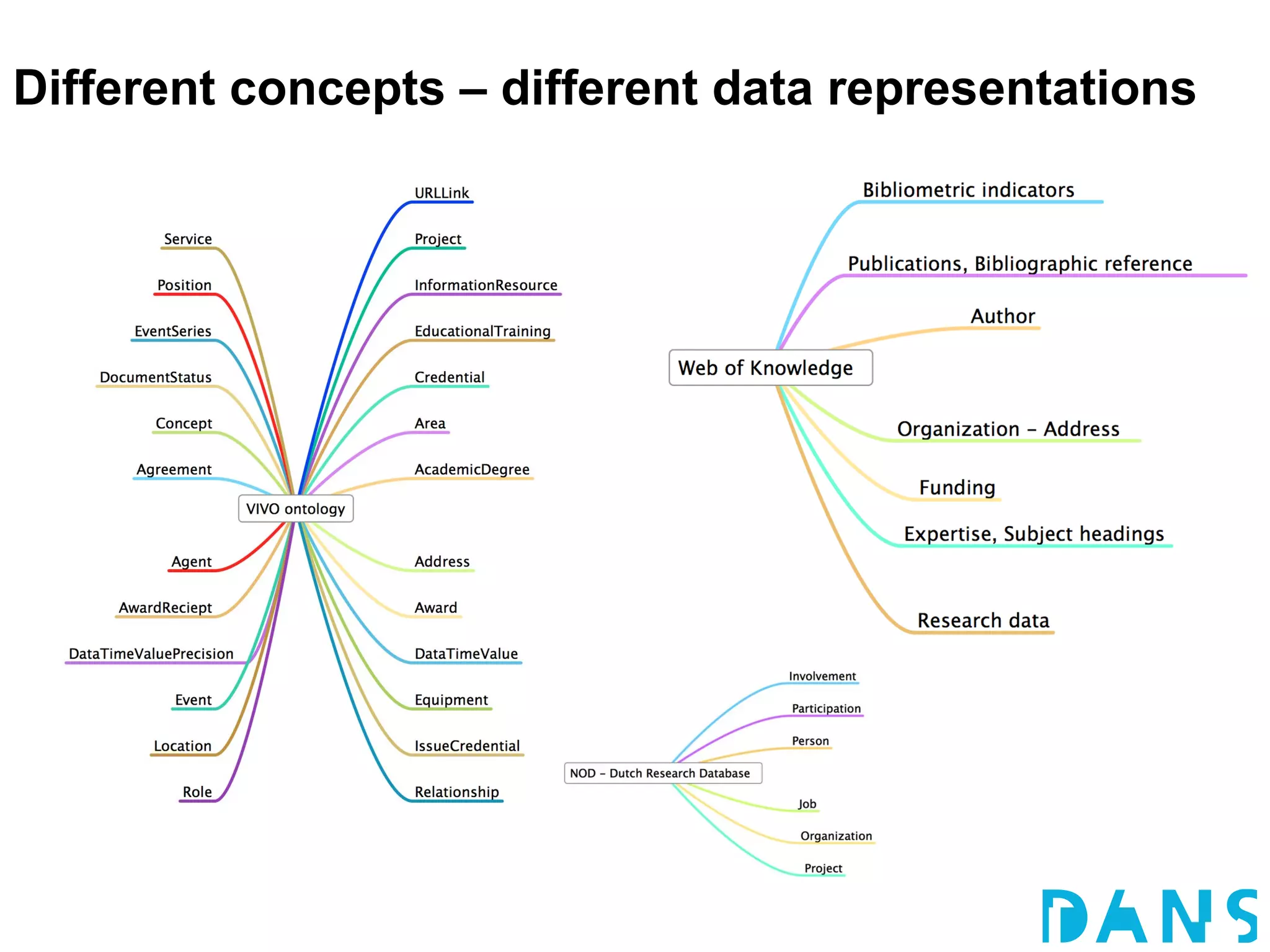
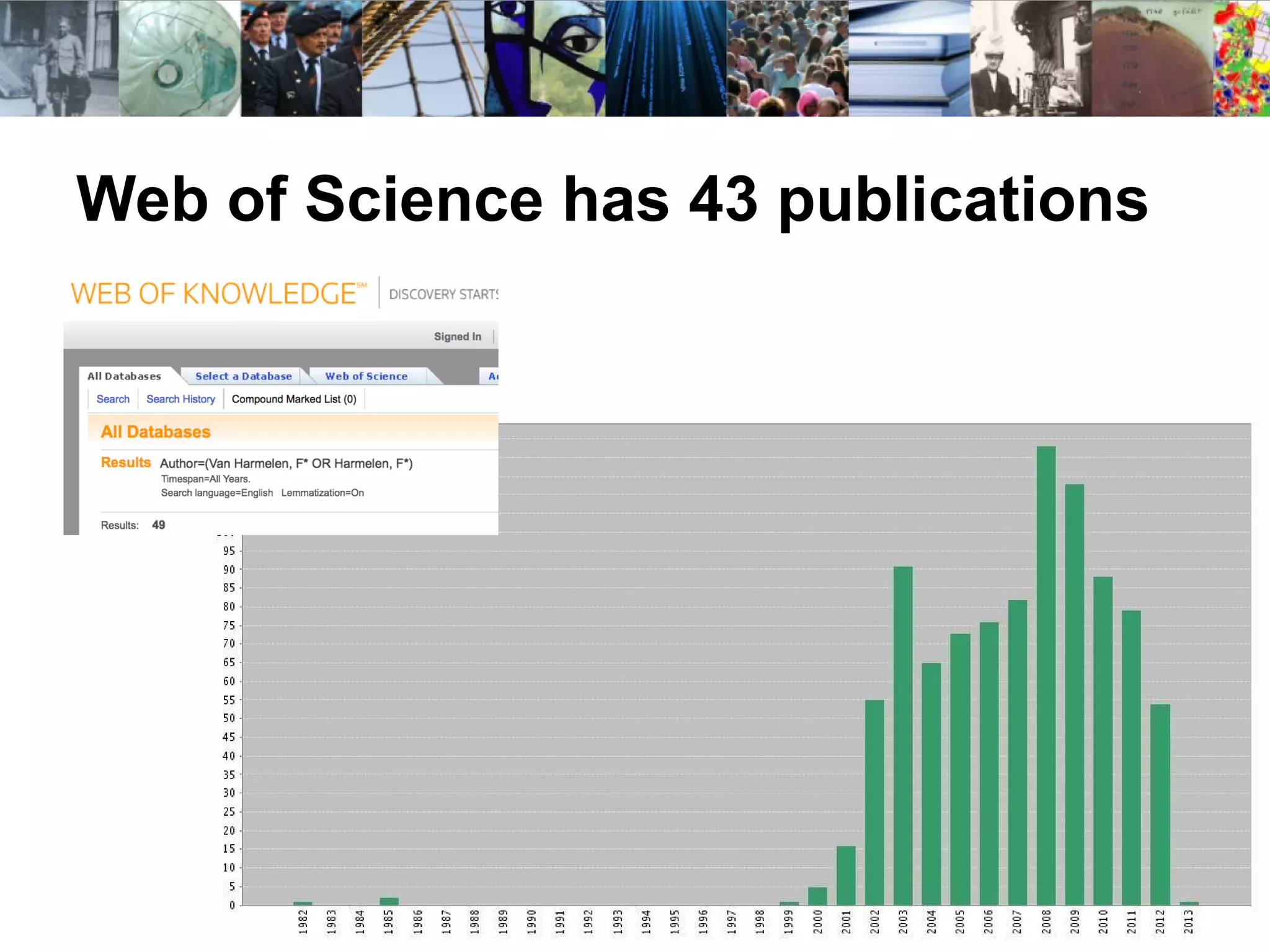
The document discusses the challenges and proposals related to the semantics of interoperable research information systems, focusing on the need for a core vocabulary in the context of bibliometrics and open data. It highlights the complexities of data archiving and the limitations of current research information systems in ensuring effective knowledge transfer and accessibility. The authors advocate for a conceptual model that balances expressivity and interoperability in representing research careers and information.










































































