Gene association networks - Large-scale integration of data and text
•Download as PPT, PDF•
1 like•237 views

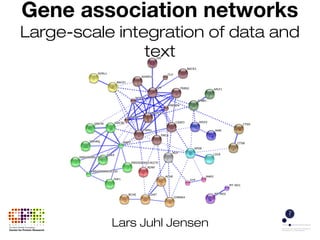
This document discusses how gene association networks are created by integrating large amounts of genomic data and text from many databases. Researchers develop parsers and mapping files to combine information about genes from various sources, which may have different formats and identifiers. They also use text mining to extract gene and protein associations from literature. The resulting association networks provide a comprehensive view of functional relationships between genes and are made available through online resources like STRING-DB.

Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Similar to Gene association networks - Large-scale integration of data and text
Similar to Gene association networks - Large-scale integration of data and text (15)
More from Lars Juhl Jensen
More from Lars Juhl Jensen (20)
Recently uploaded
Recently uploaded (20)
Gene association networks - Large-scale integration of data and text
- 1. Gene association networks Large-scale integration of data and text Lars Juhl Jensen
- 7. gene fusion
- 8. Korbel et al., Nature Biotechnology, 2004
- 10. Korbel et al., Nature Biotechnology, 2004
- 15. Jensen & Bork, Science, 2008
- 19. pathways
- 20. Letunic & Bork, Trends in Biochemical Sciences, 2008
- 21. many databases
- 24. variable quality
- 25. not comparable
- 26. hard work
- 27. (Ph.D. students)
- 28. parsers
- 29. mapping files
- 30. quality scores
- 32. von Mering et al., Nucleic Acids Research, 2005
- 34. gold standard
- 35. von Mering et al., Nucleic Acids Research, 2005
- 36. implicit weighting by quality
- 37. common scale
- 39. Franceschini et al., Nucleic Acids Research, 2013
- 40. missing most of the data
- 41. >10 km
- 42. too much to read
- 43. text mining
- 45. cyclin dependent kinase 1
- 46. CDC2
- 49. cyclin dependent kinase 1
- 52. CDC2
- 53. hCdc2
- 54. “black list”
- 55. SDS
- 56. co-mentioning
- 57. counting
- 58. within documents
- 60. within sentences
- 61. quality scores
- 65. Szklarczyk et al., Nucleic Acids Research, 2015string-db.org
- 66. web resource
- 67. download files
- 68. REST API
- 70. Cytoscape App
- 71. Acknowledgments Damian Szklarczyk Michael Kuhn Andrea Franceschini Milan Simonovic Alexander Roth Sune Pletscher-Frankild John “Scooter” Morris Christian von Mering Peer Bork
- 72. Unacknowledgments Do yourself a favor, don’t fly