Downloaded 74 times











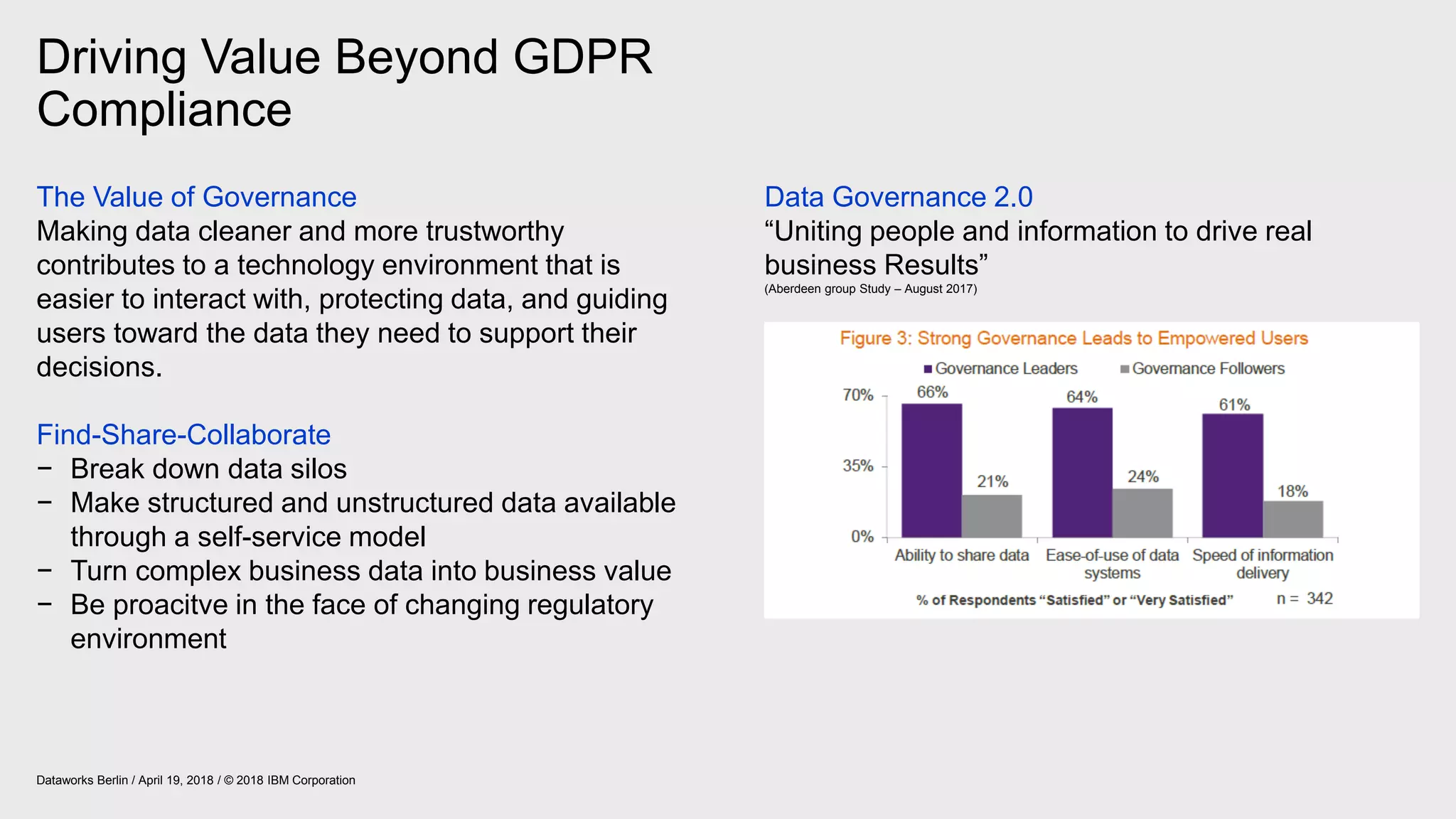

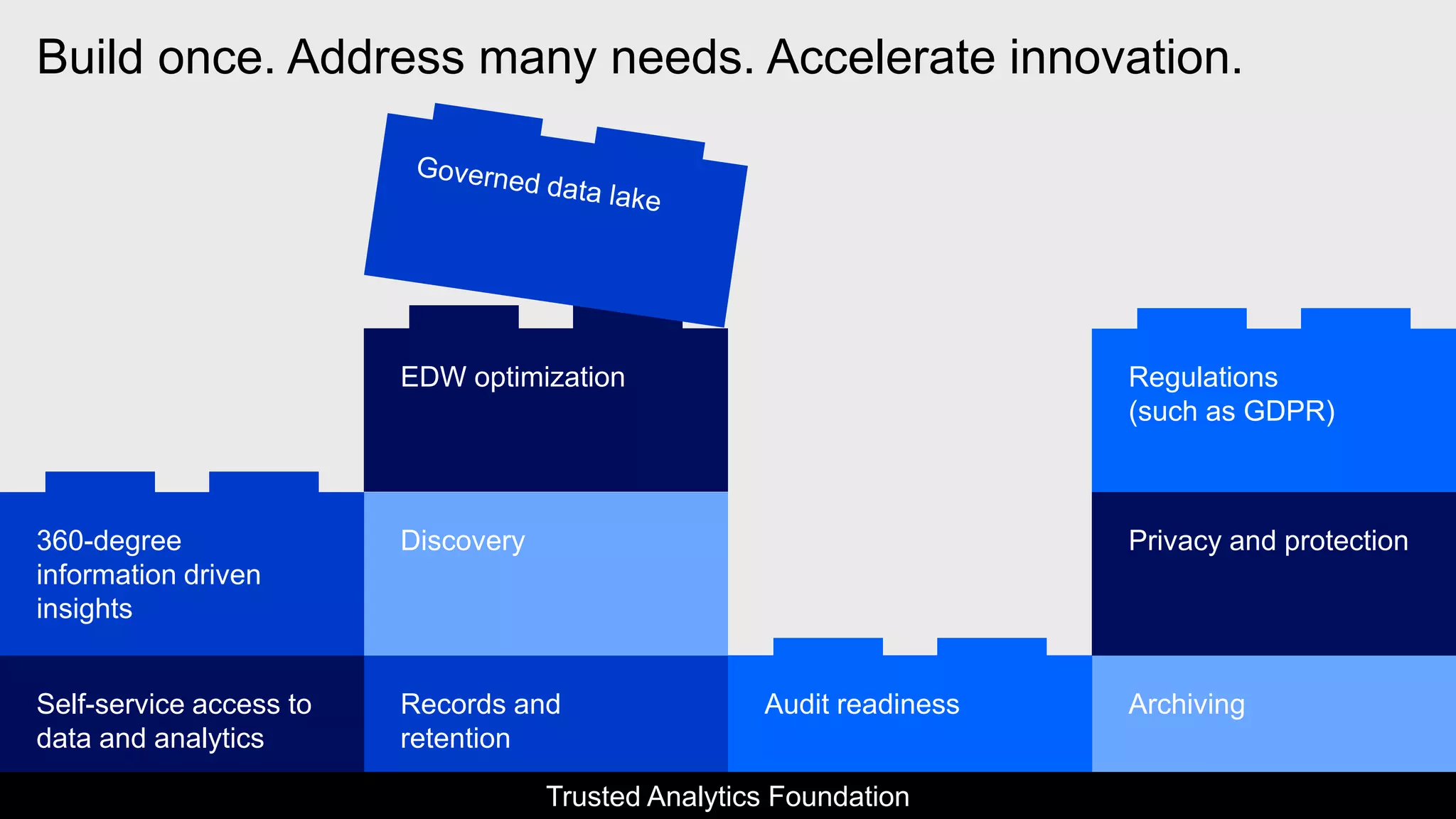




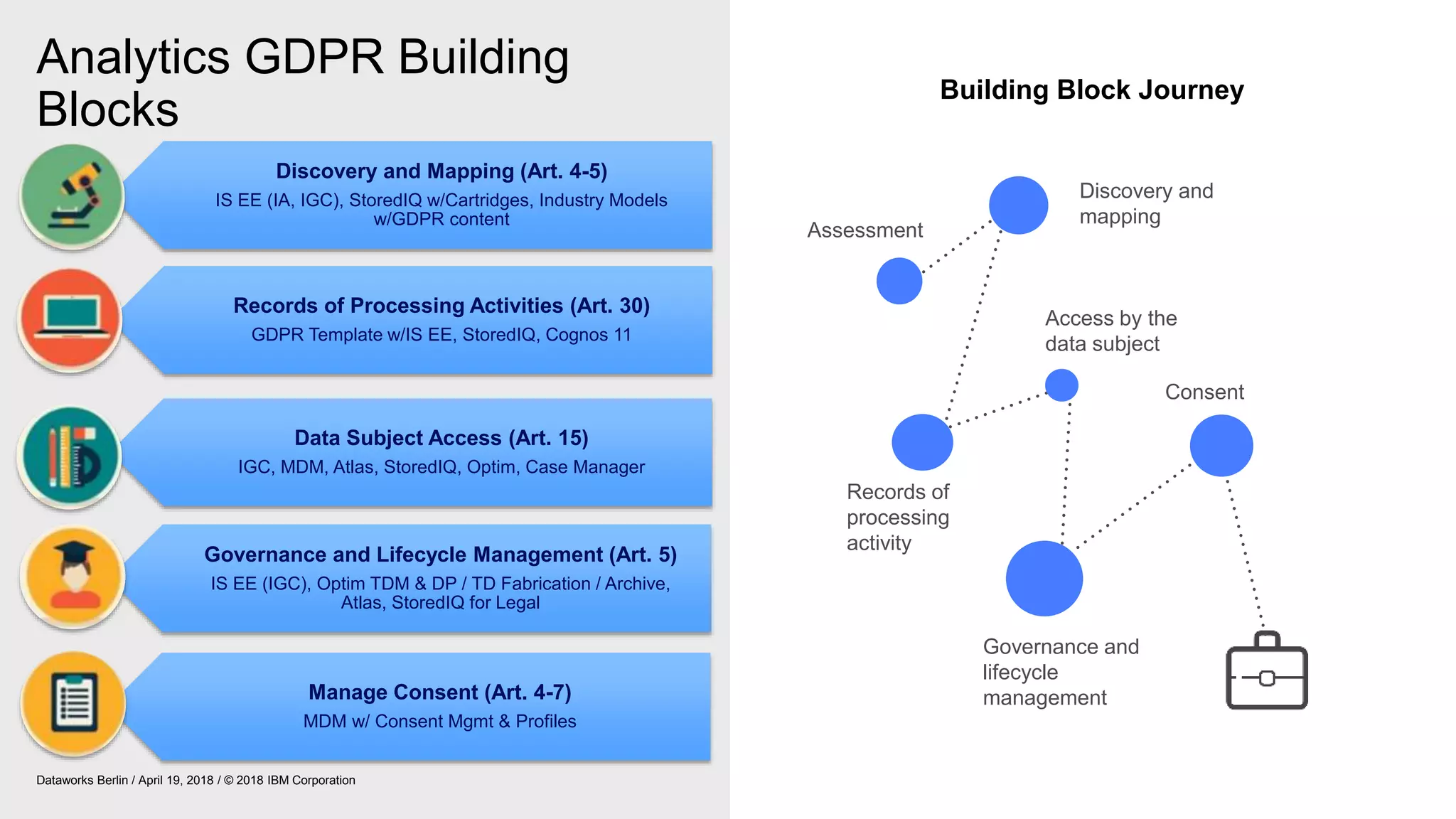
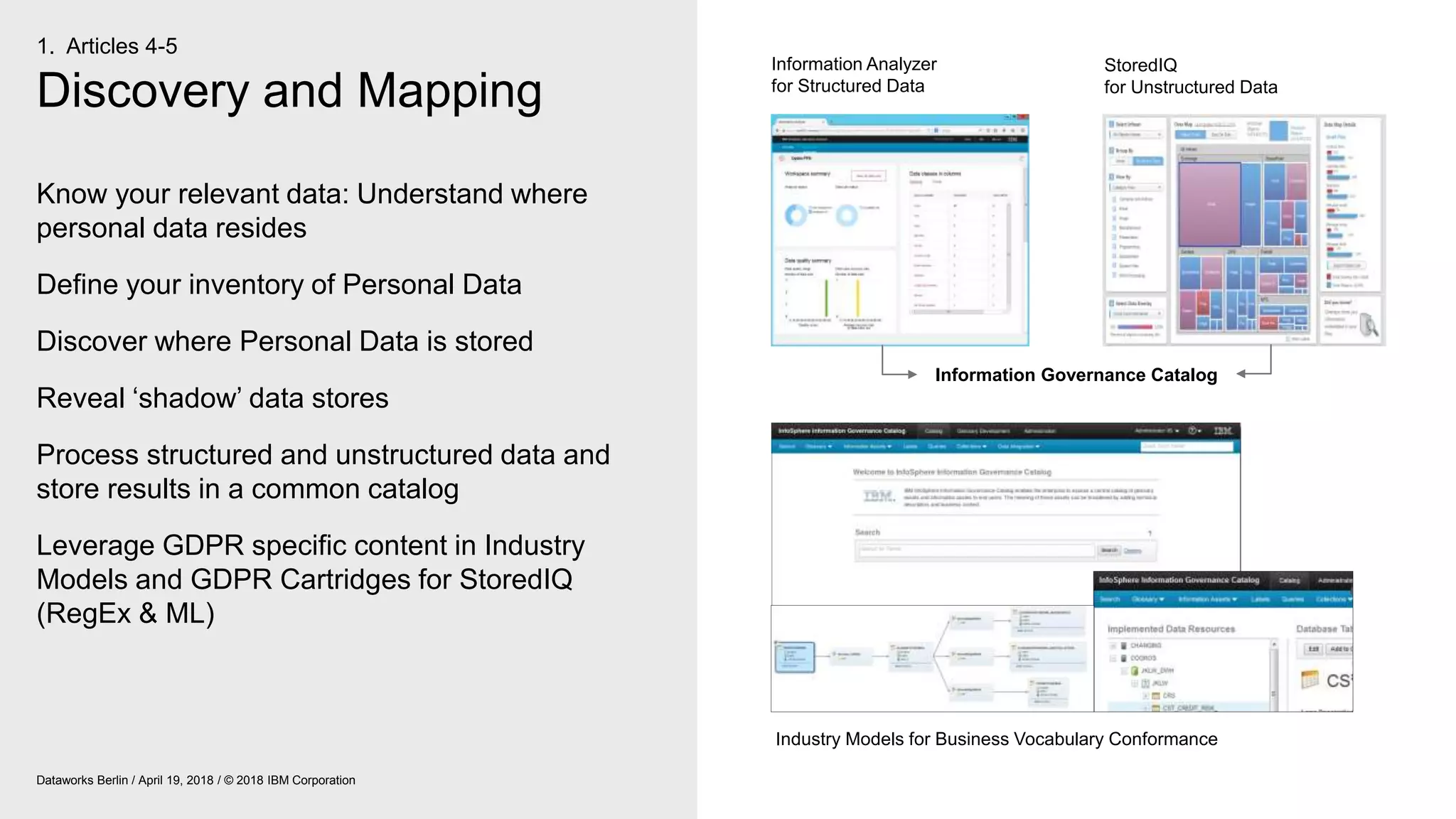






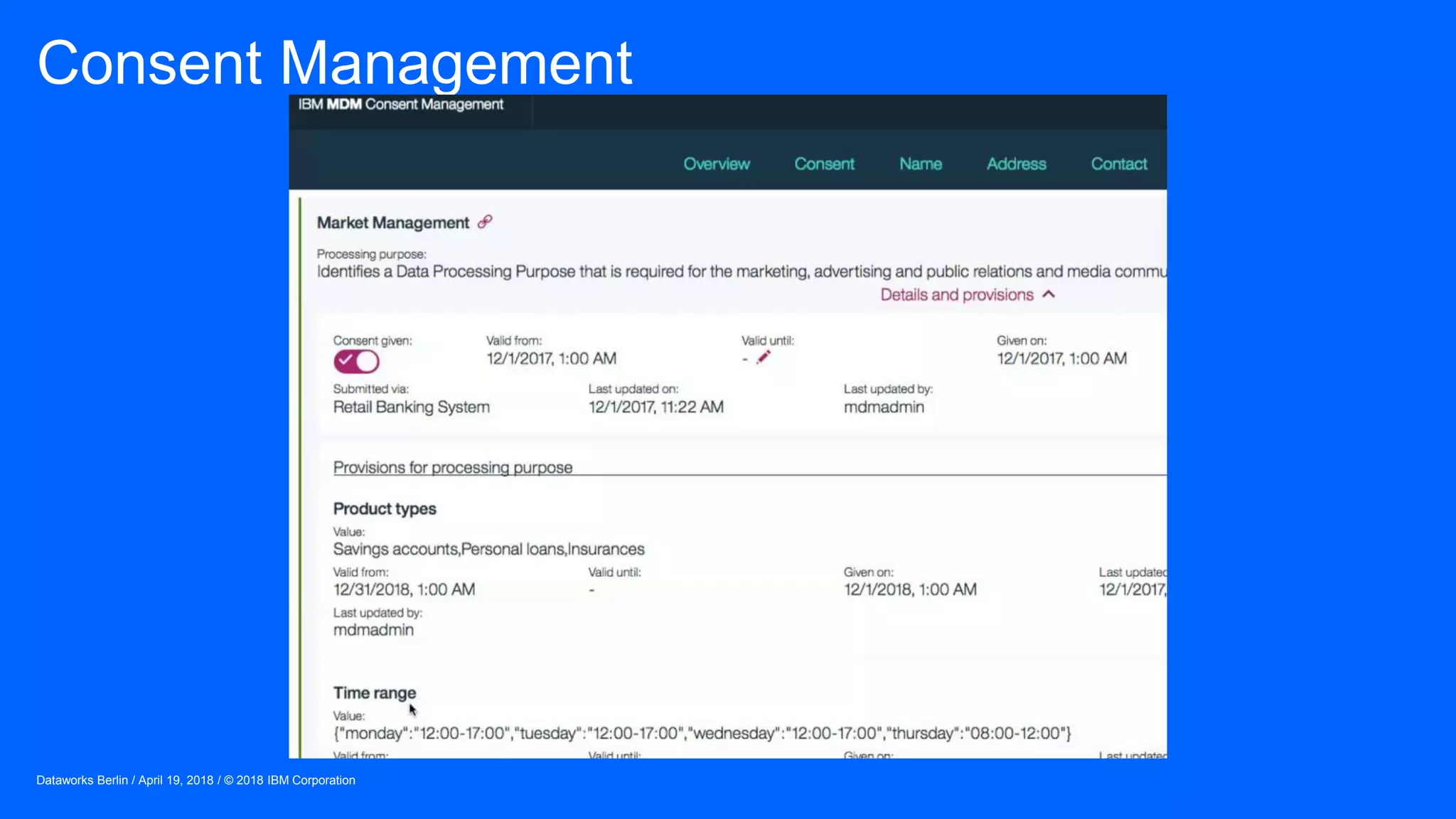





The document outlines IBM's journey and strategies for achieving compliance with the European Union's General Data Protection Regulation (GDPR). It emphasizes the importance of data governance, the rights of data subjects, and the responsibilities of organizations in managing personal data. Additionally, it highlights IBM's initiatives and frameworks aimed at assisting clients in their own GDPR compliance efforts.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










