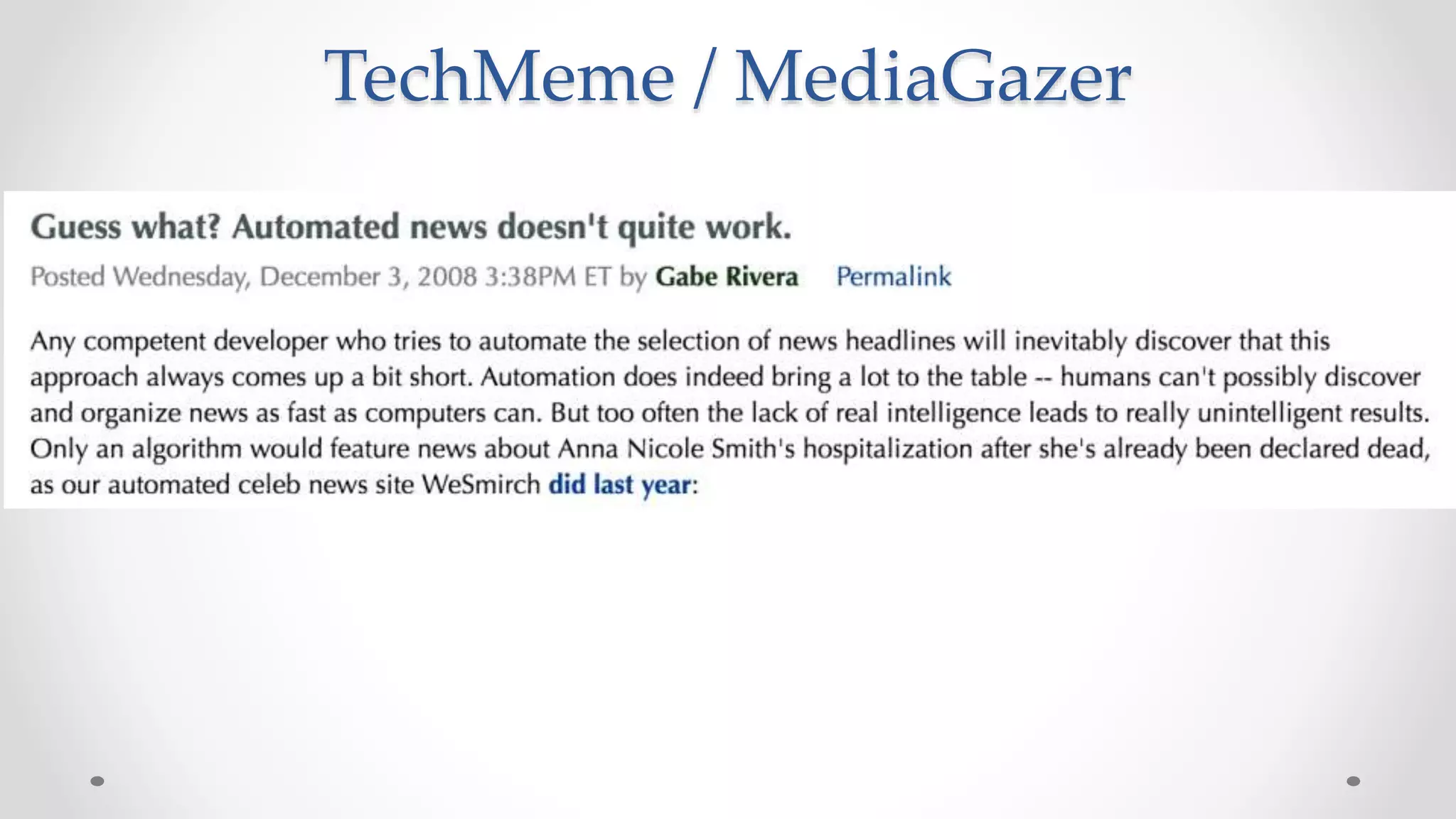
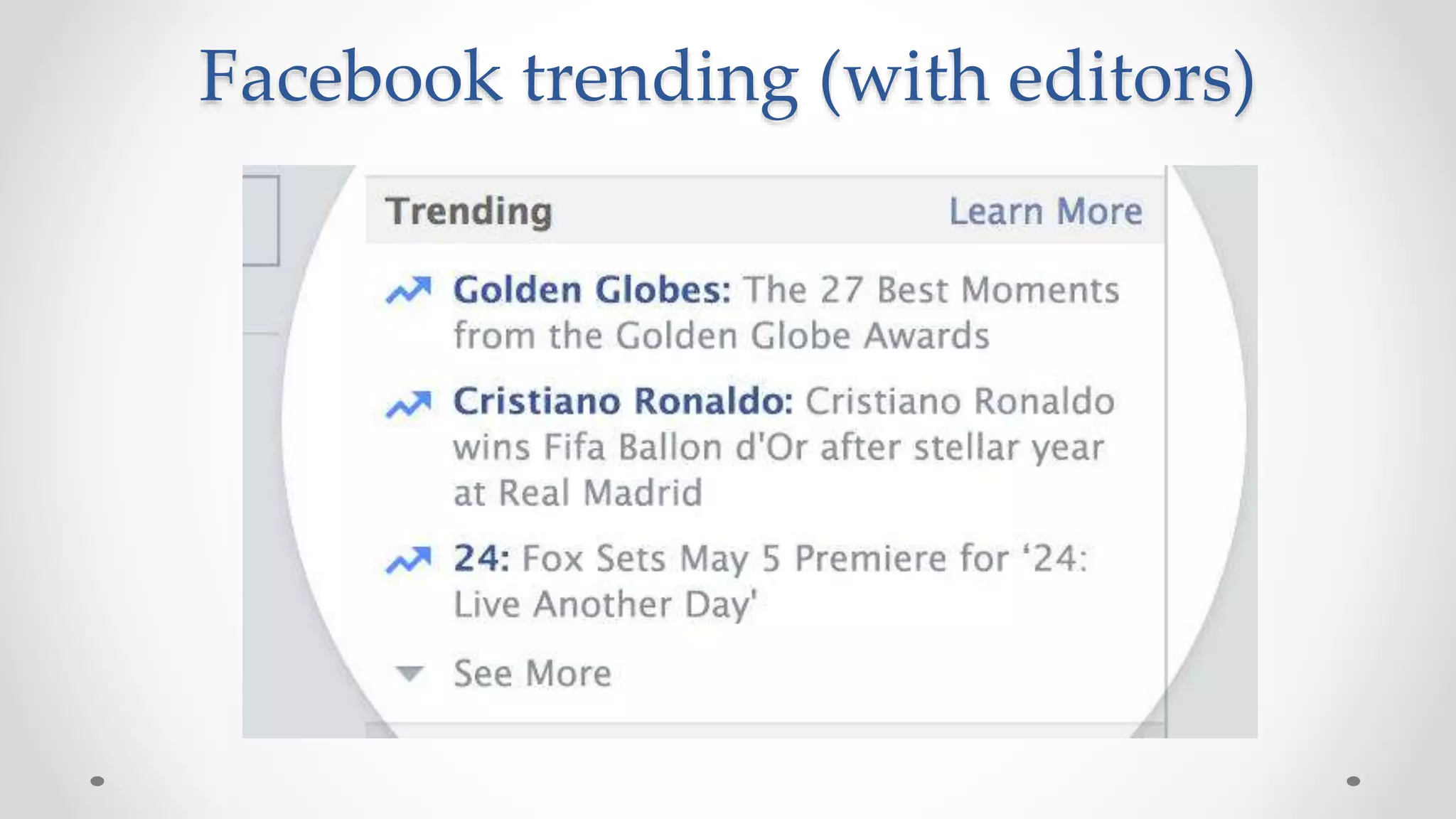
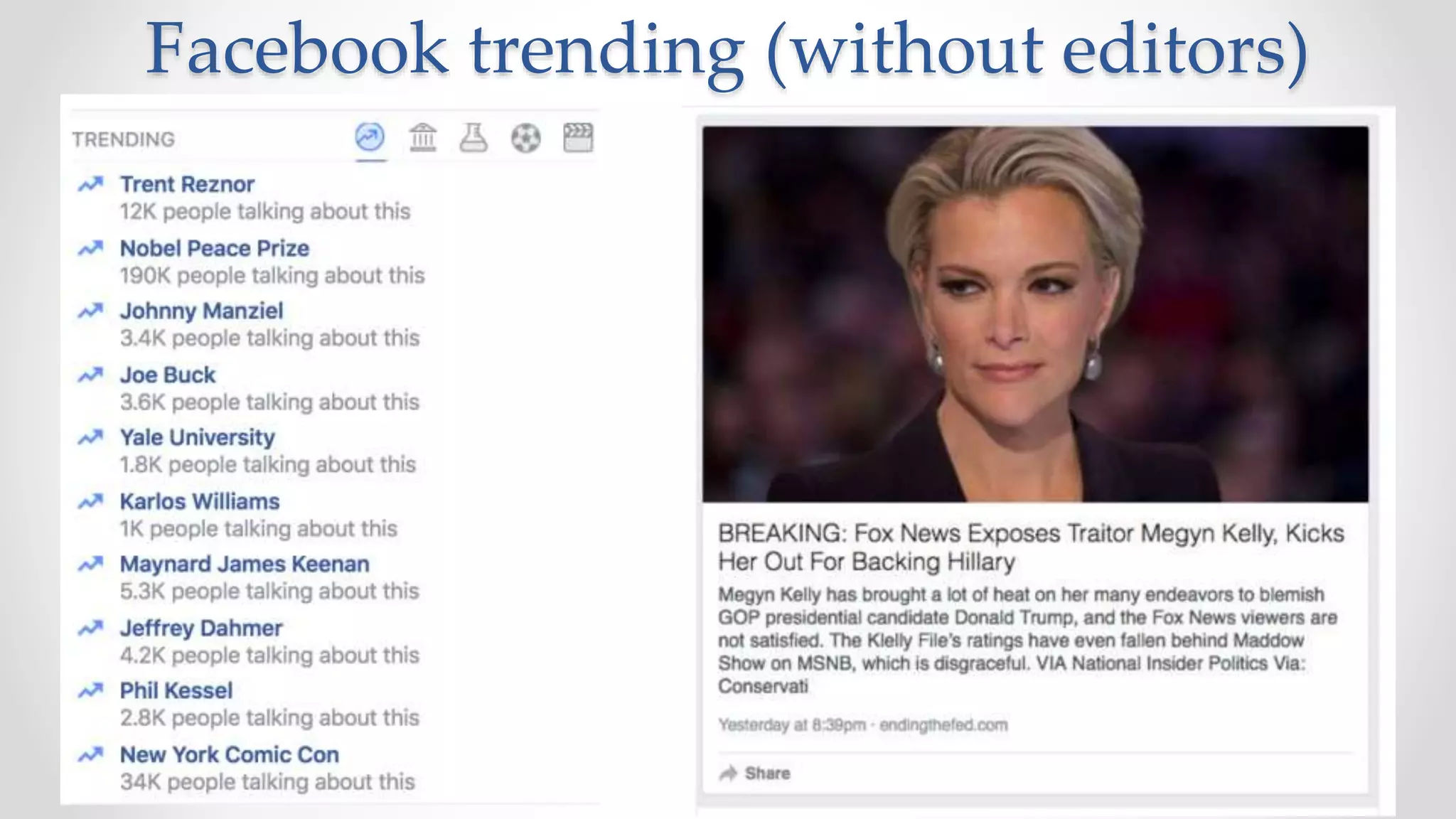
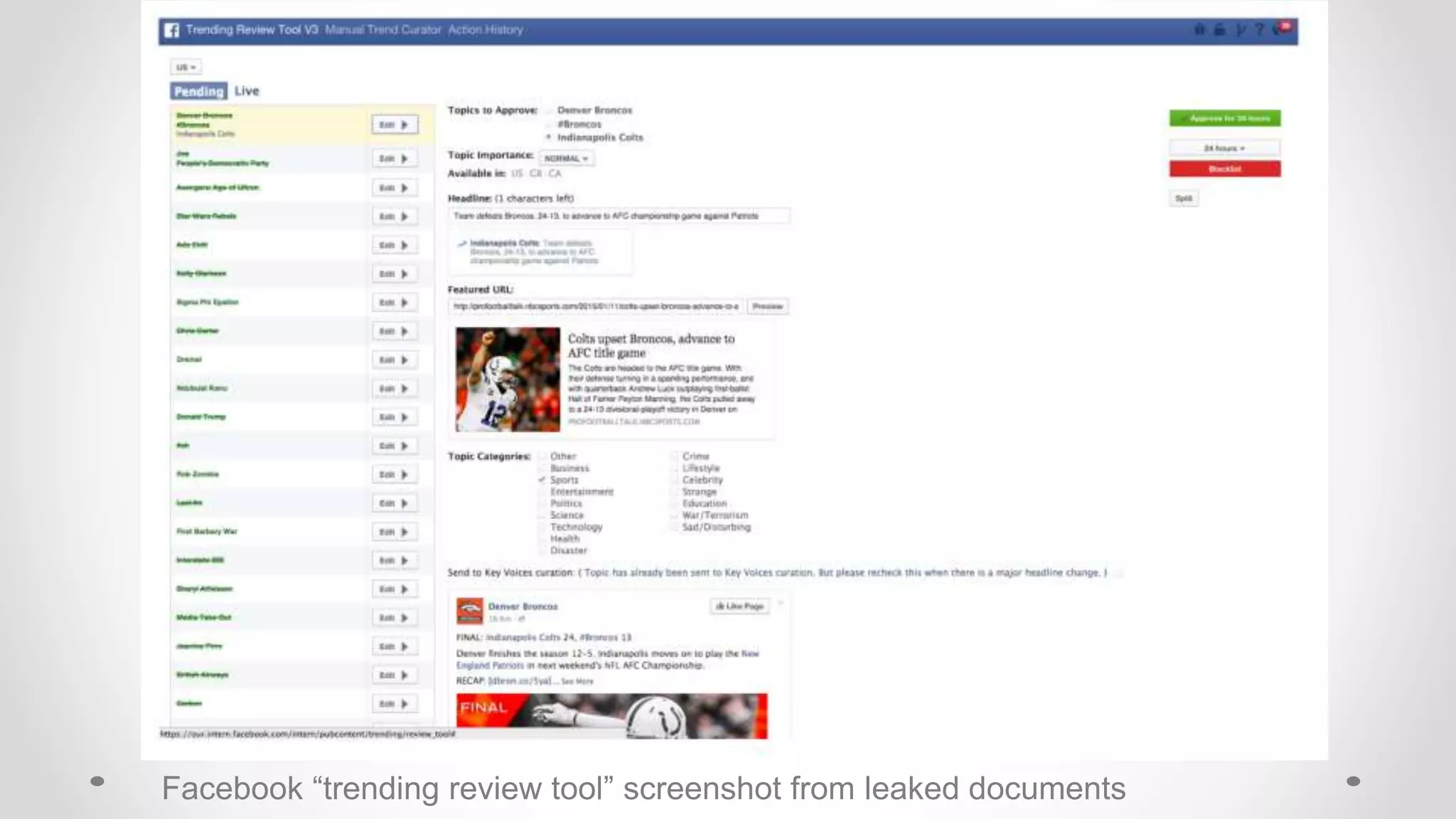
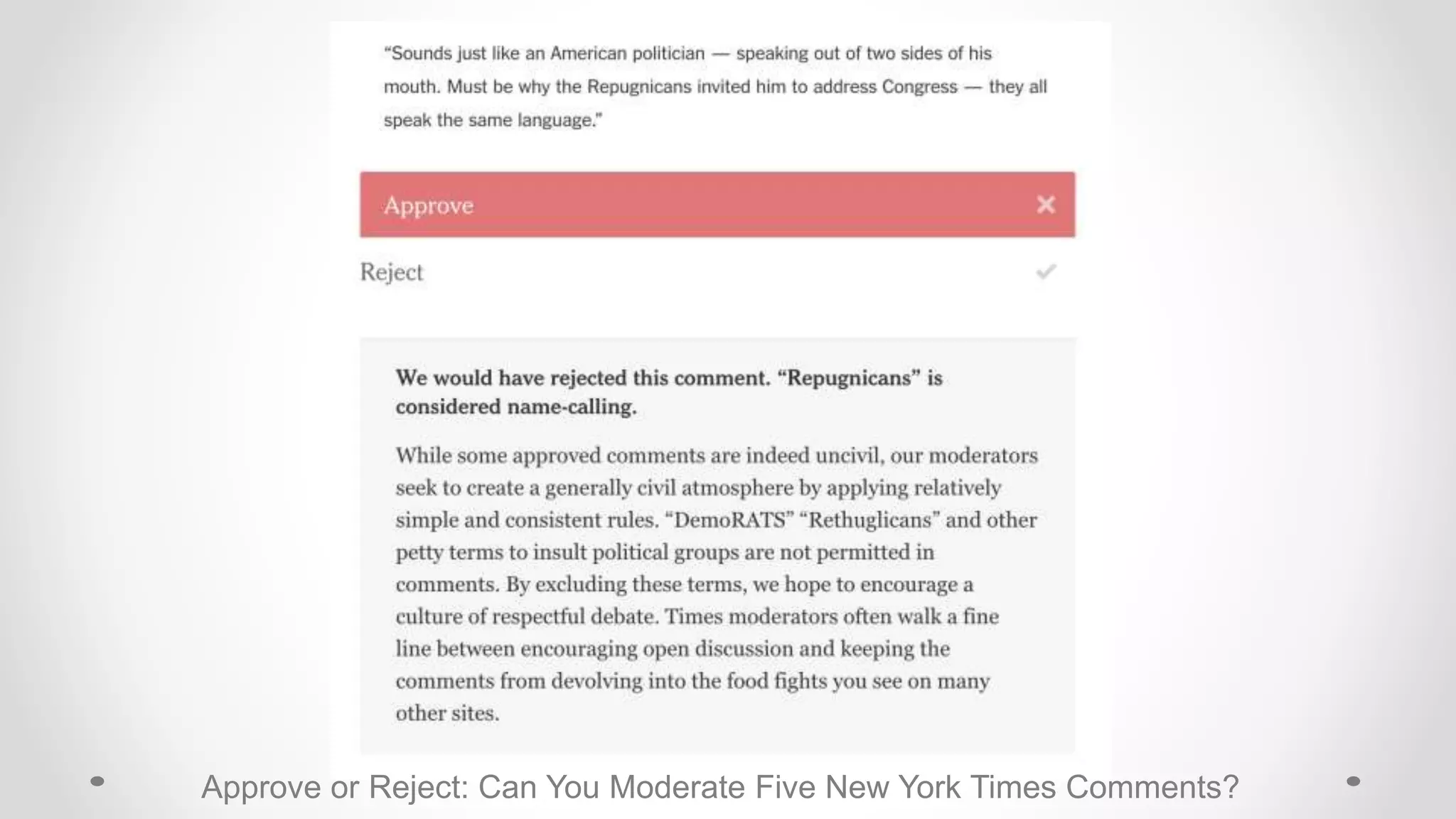
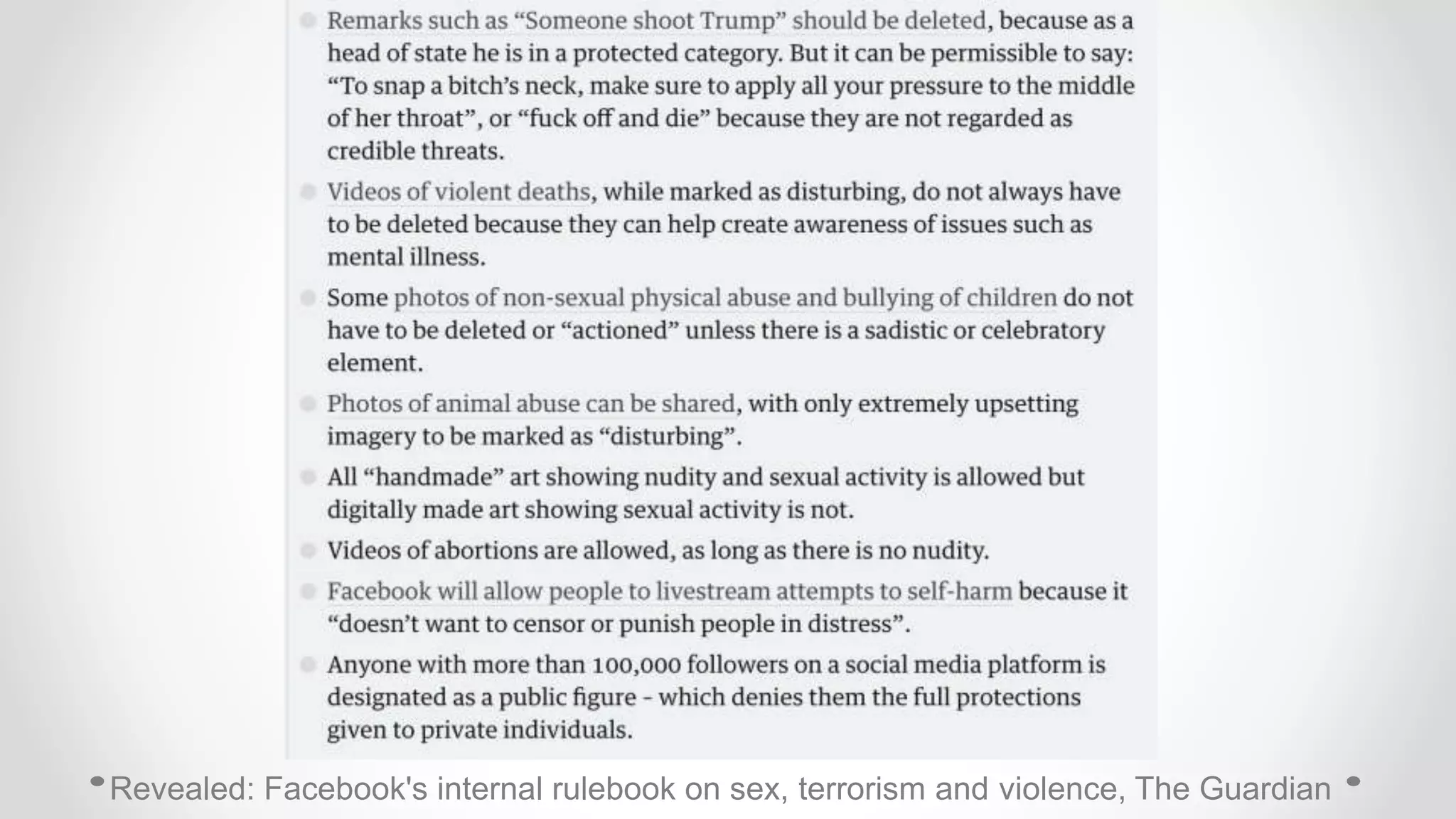
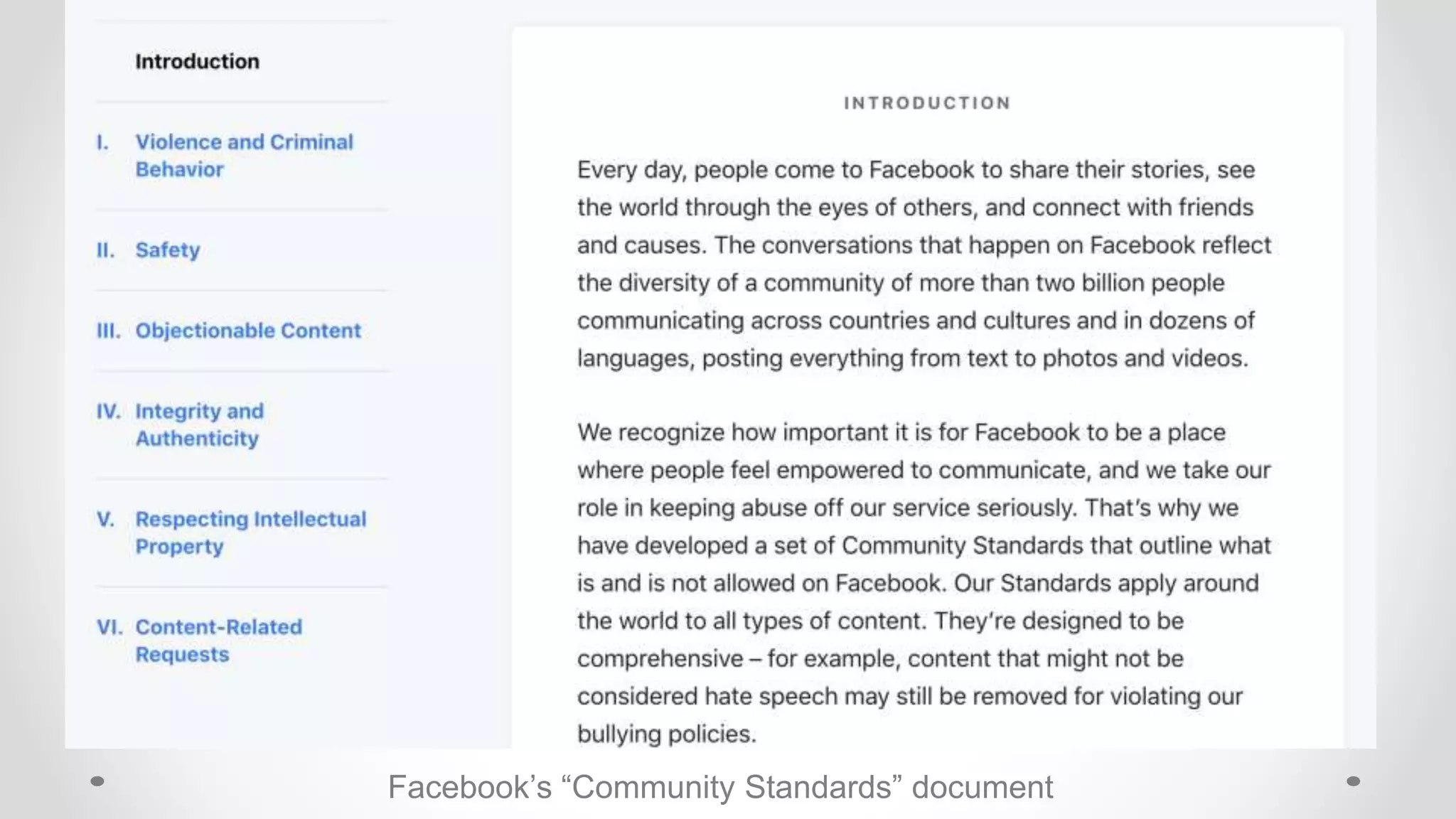
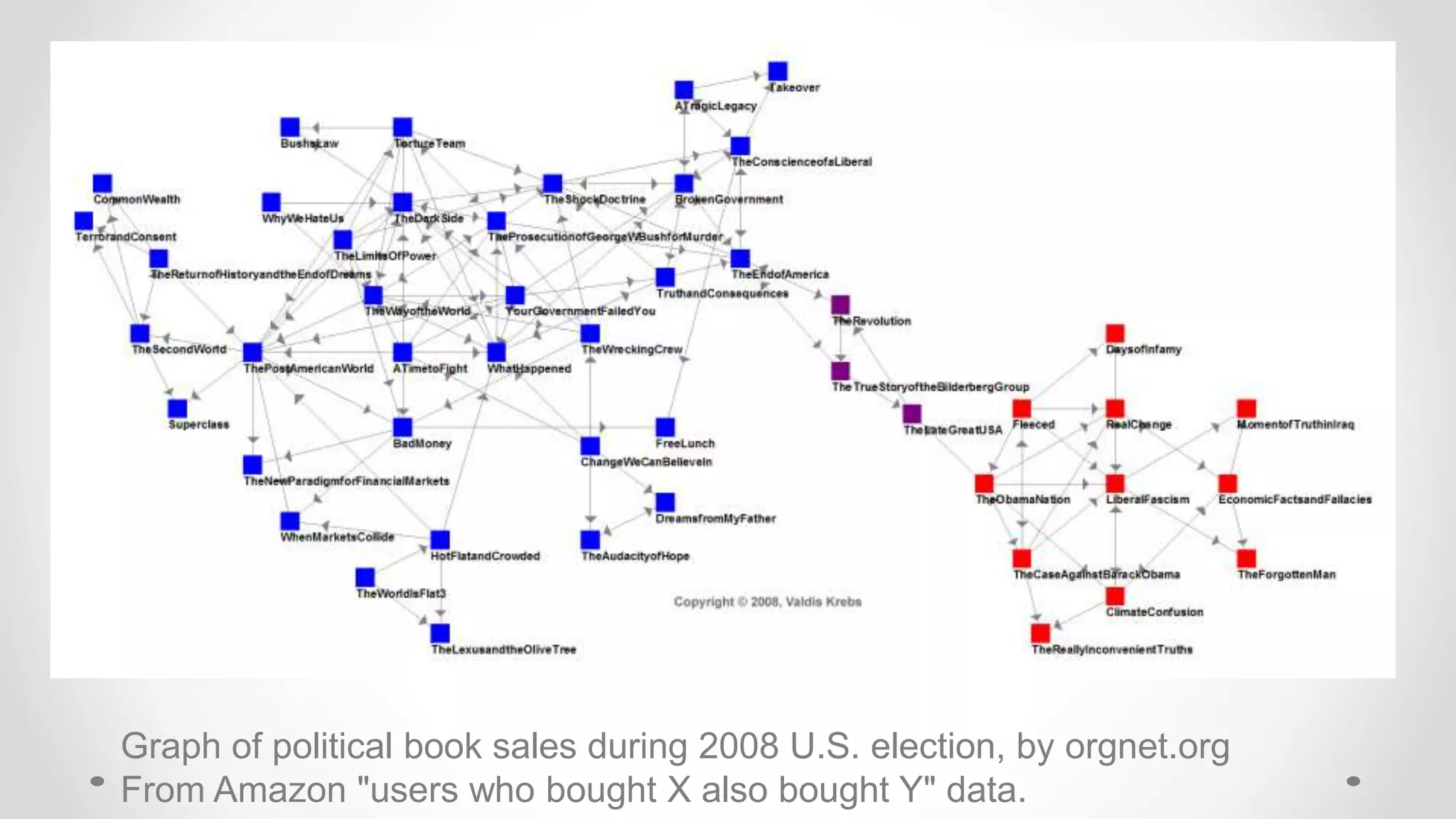
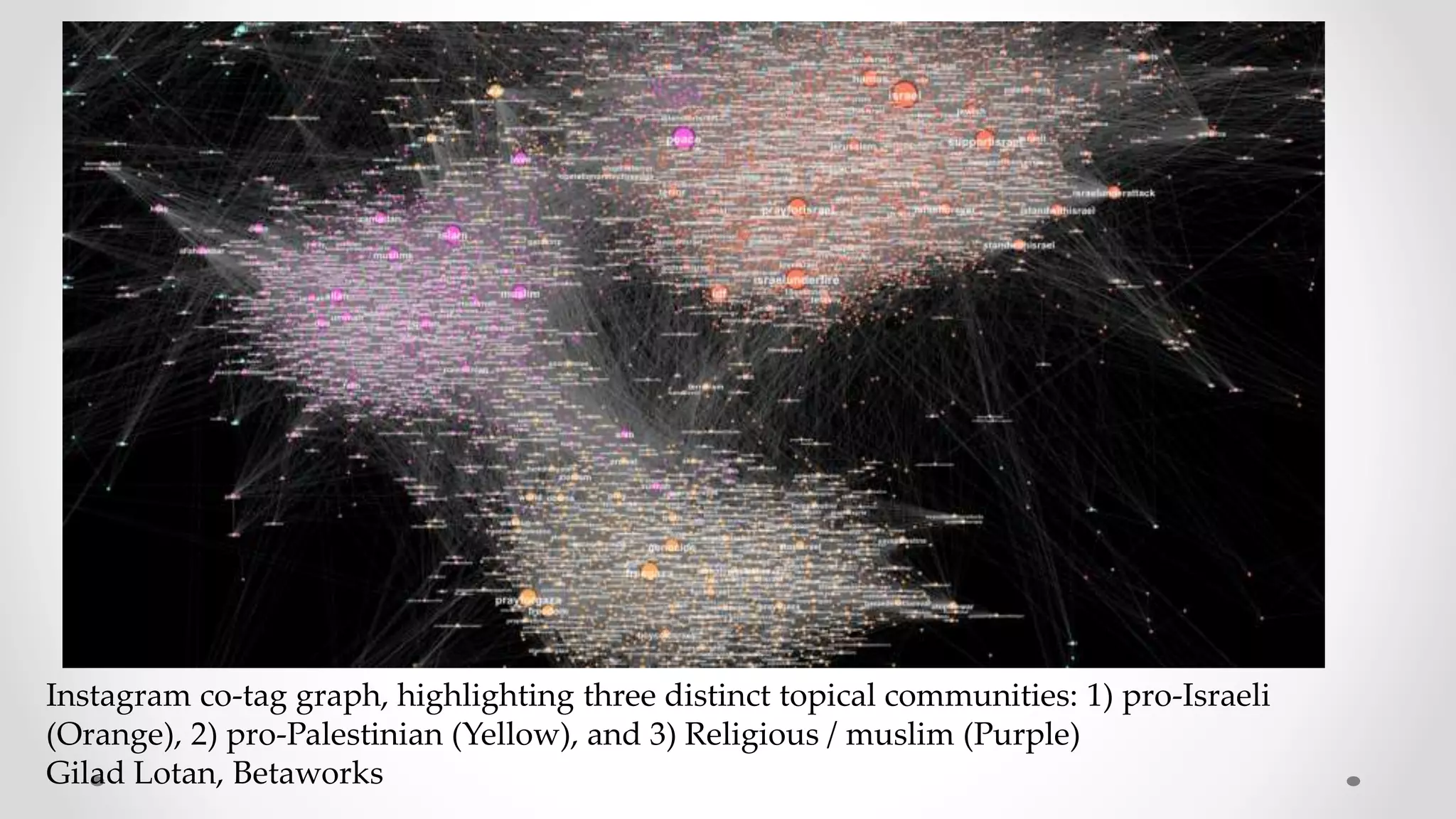
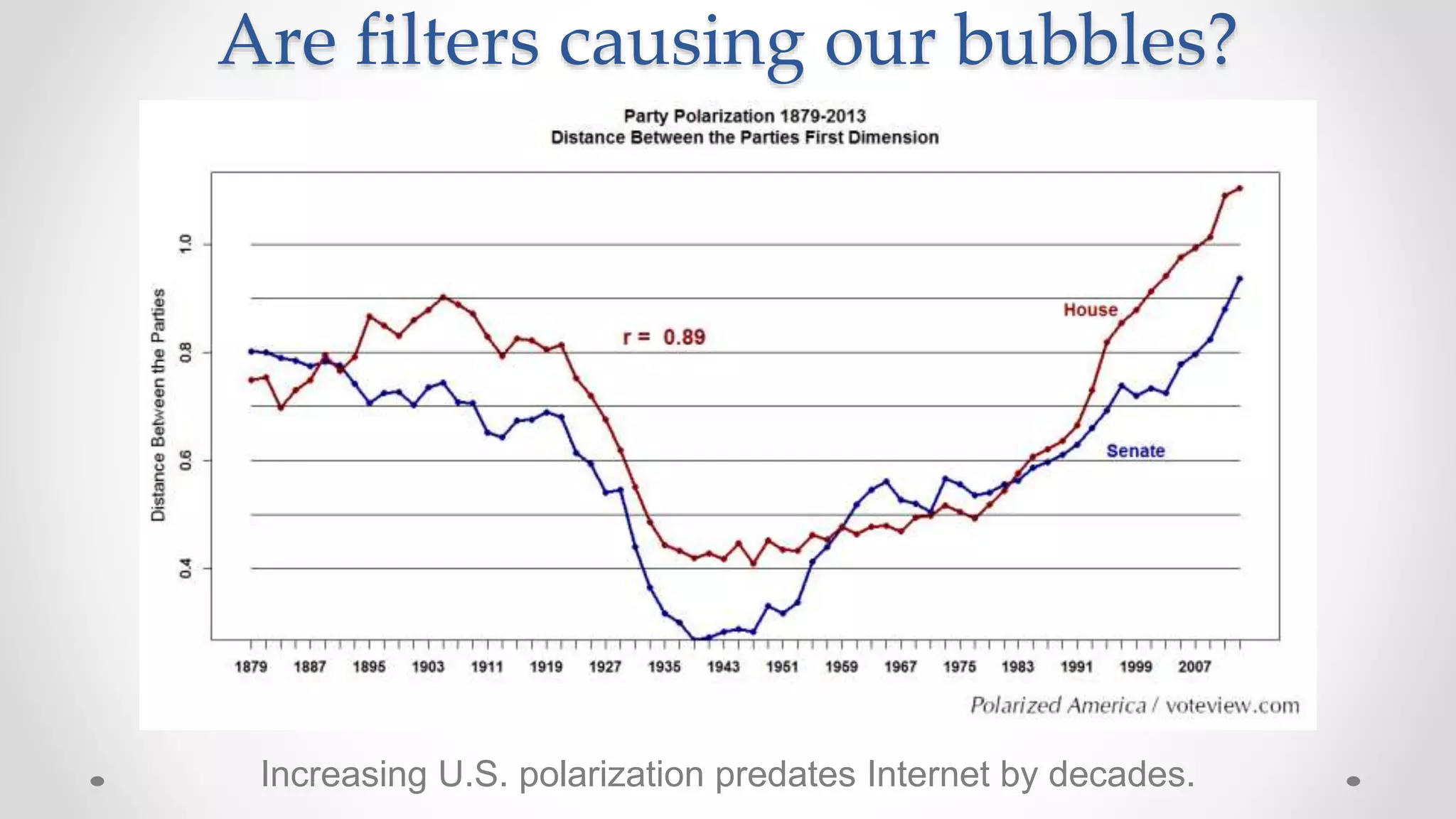
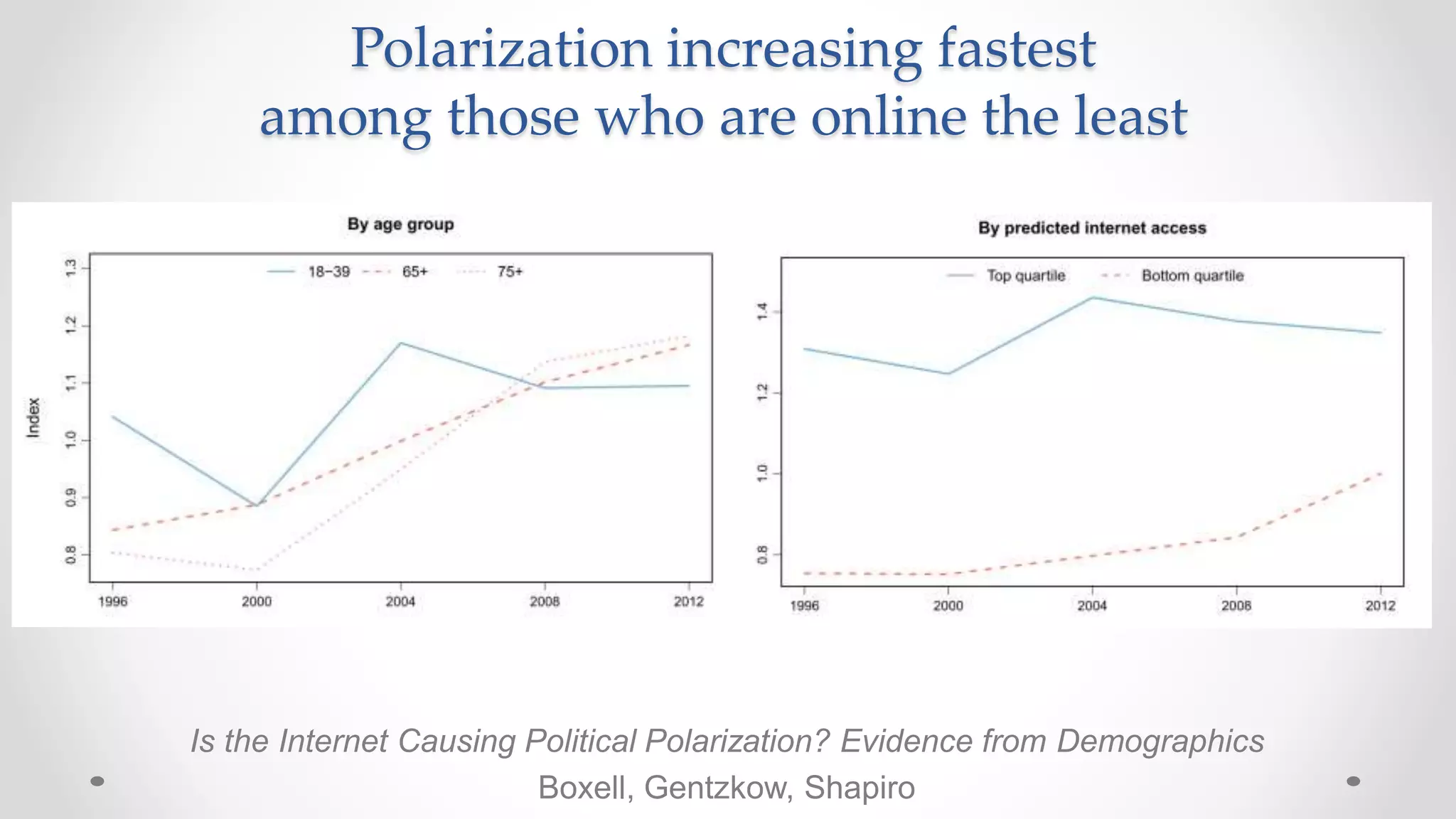
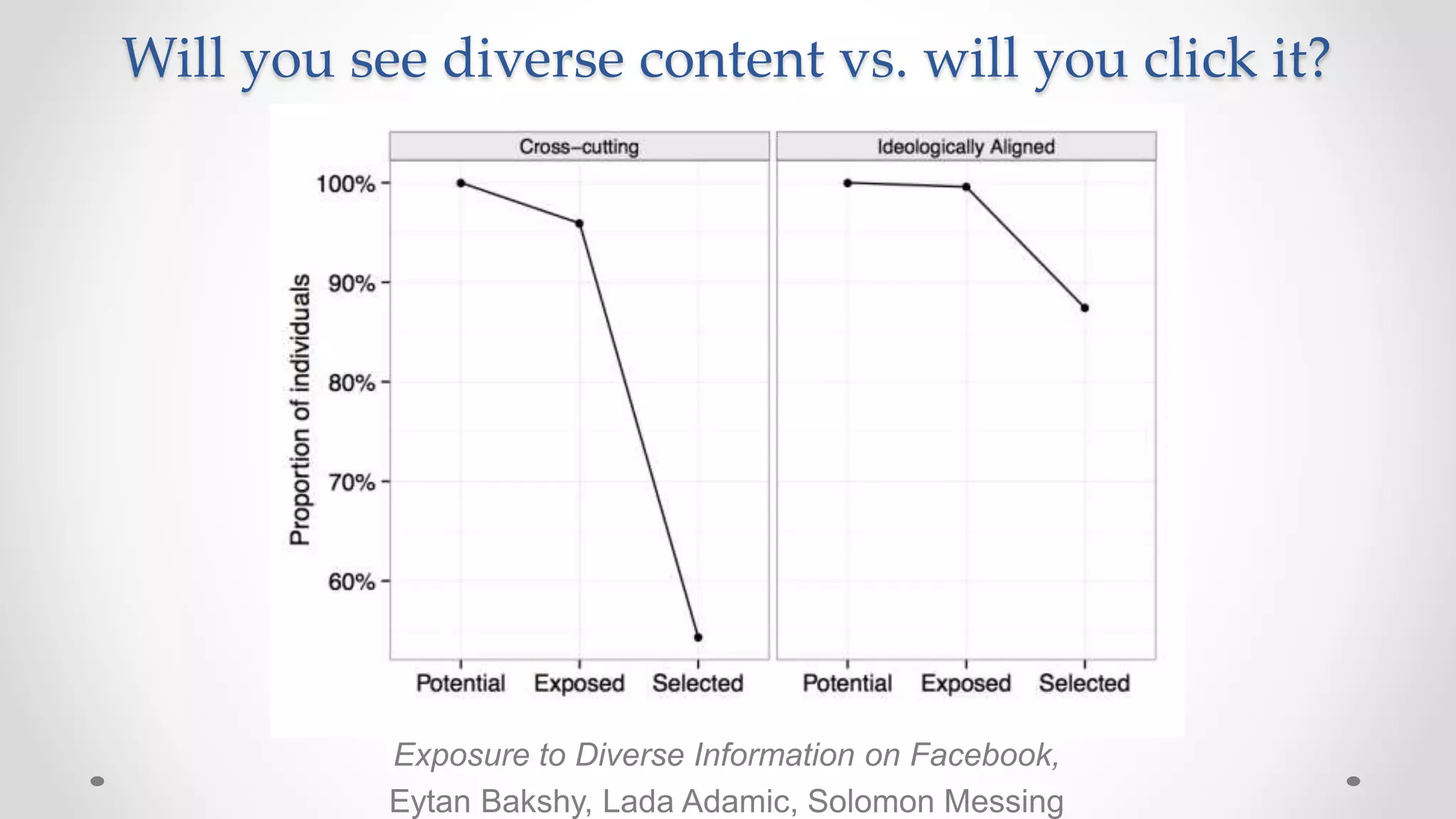
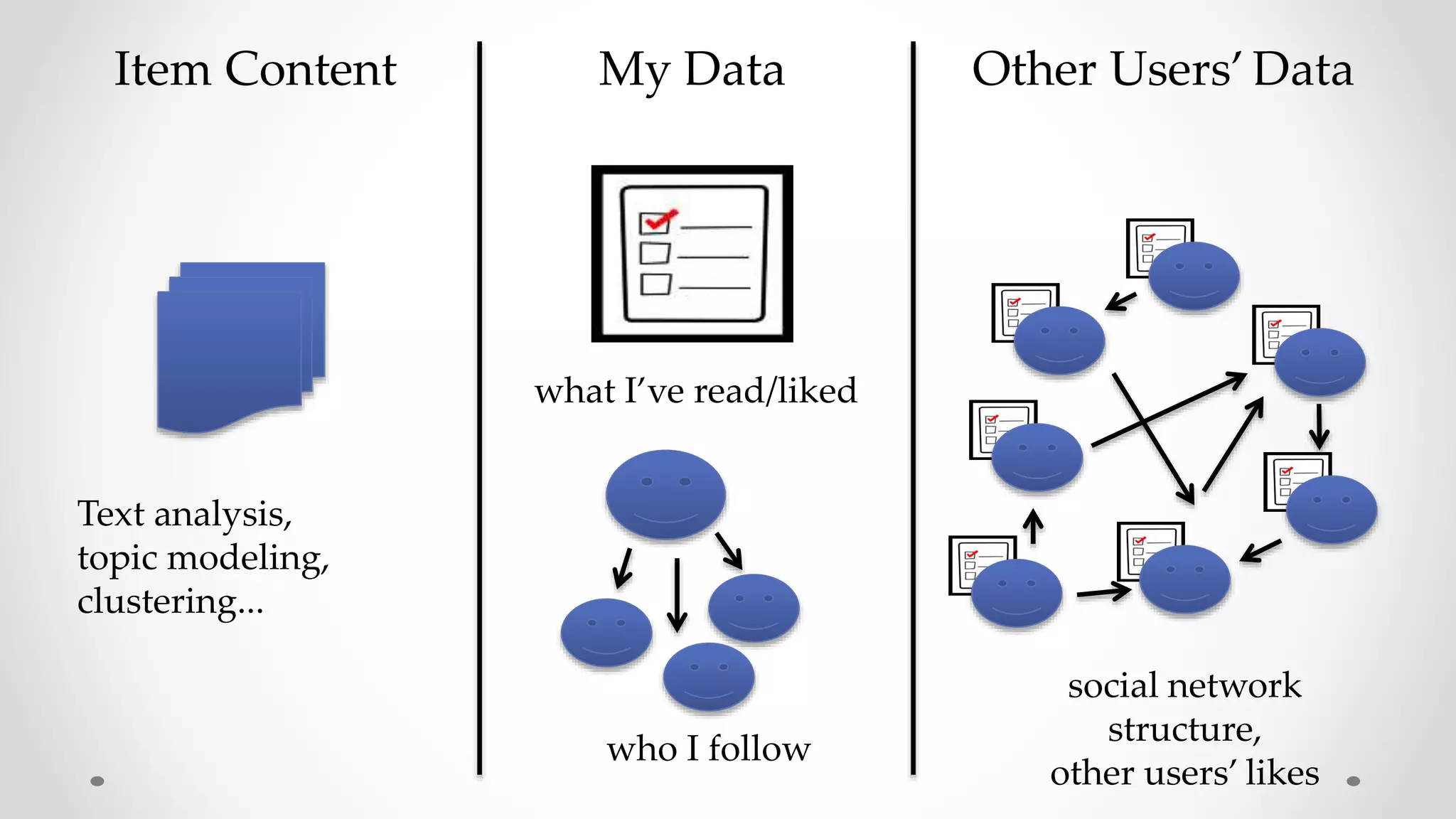
The document discusses information filtering, highlighting the overwhelming volume of content generated daily and the challenges of current filtering systems, such as user-item recommendation and comment ranking algorithms. It emphasizes the problems of filter bubbles and political polarization, suggesting that these issues arise from how digital media influences user preferences and choices. The text also explores various approaches to filter design and evaluation, advocating for diversity in information exposure.
















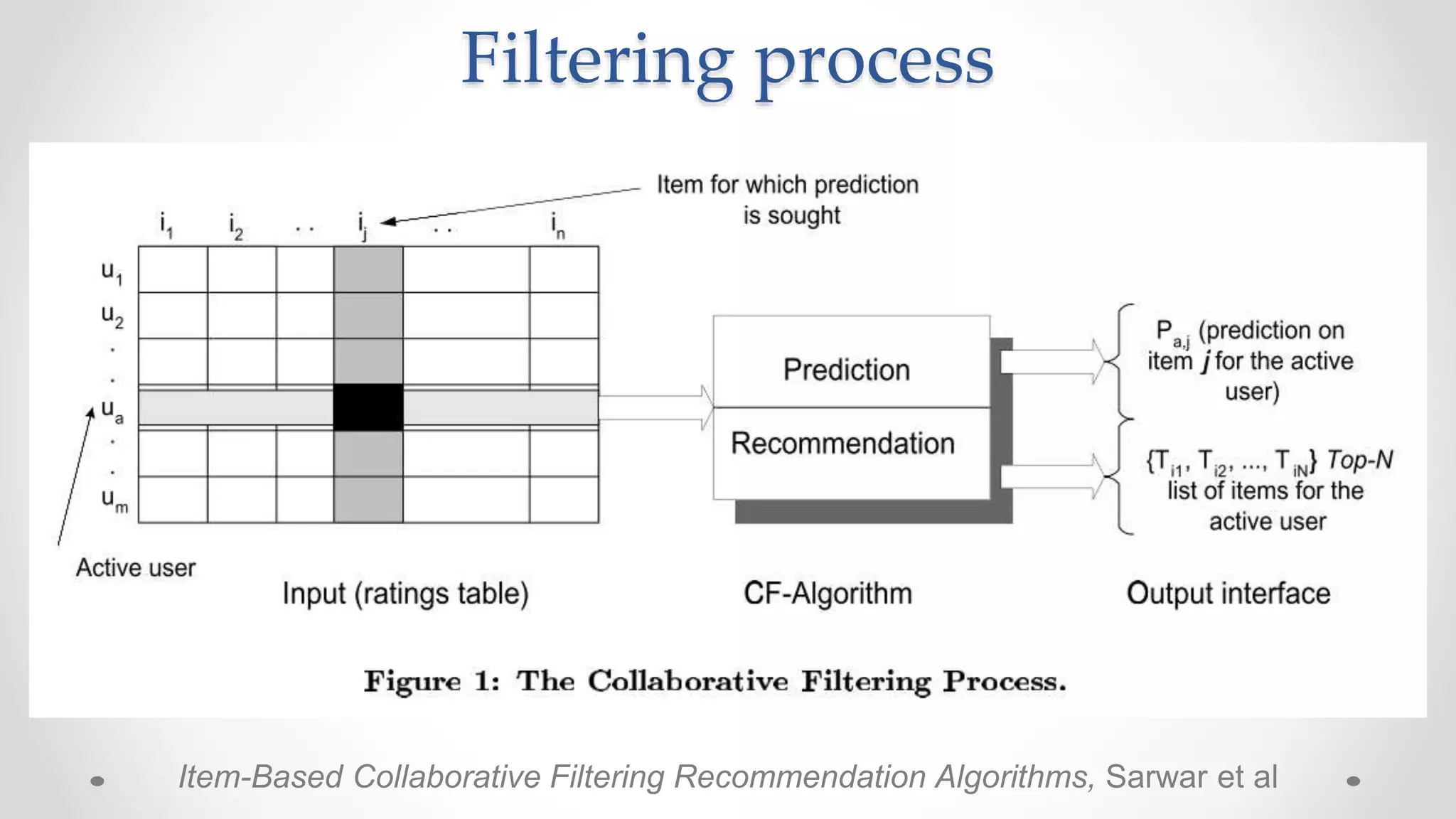

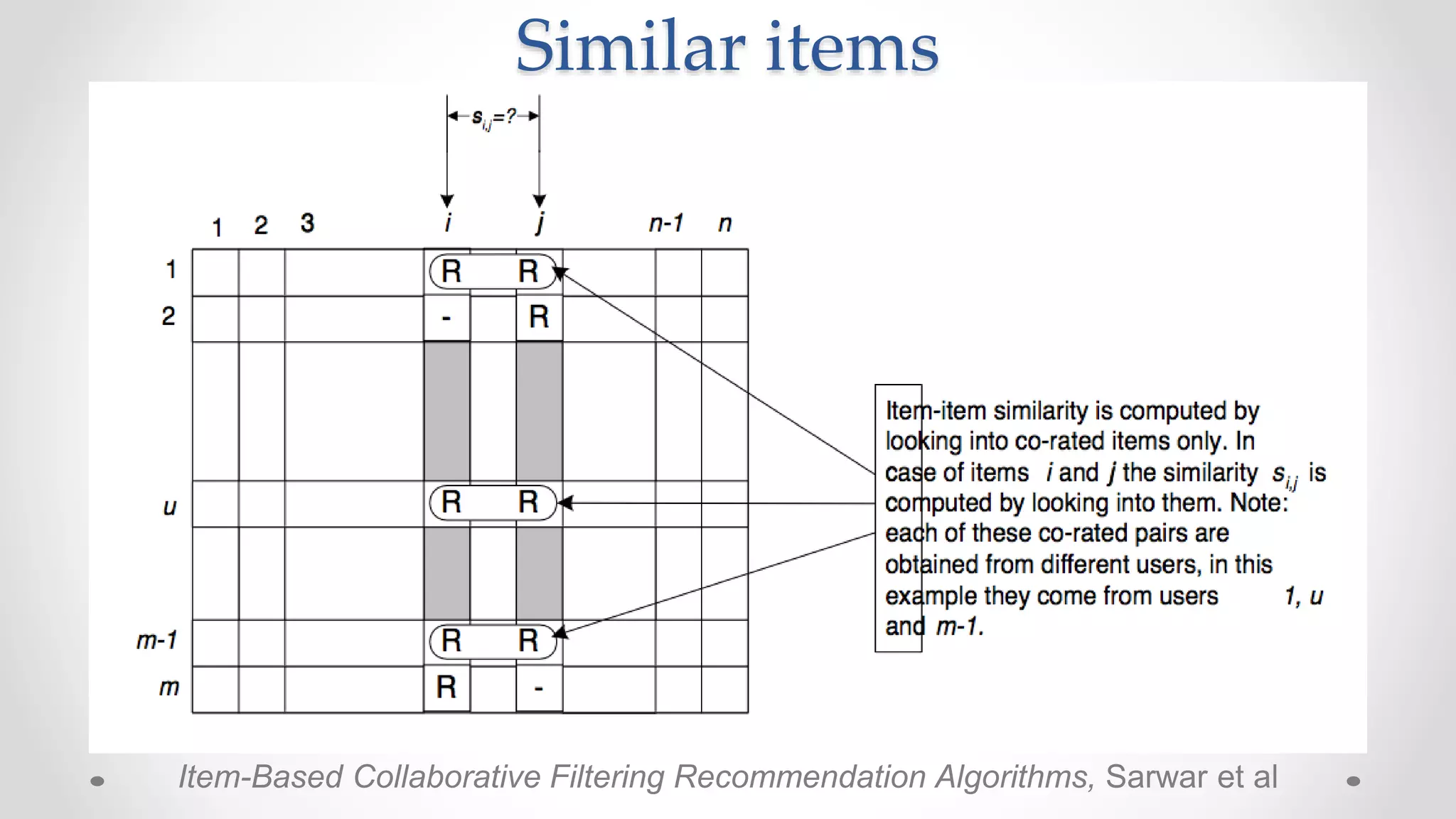





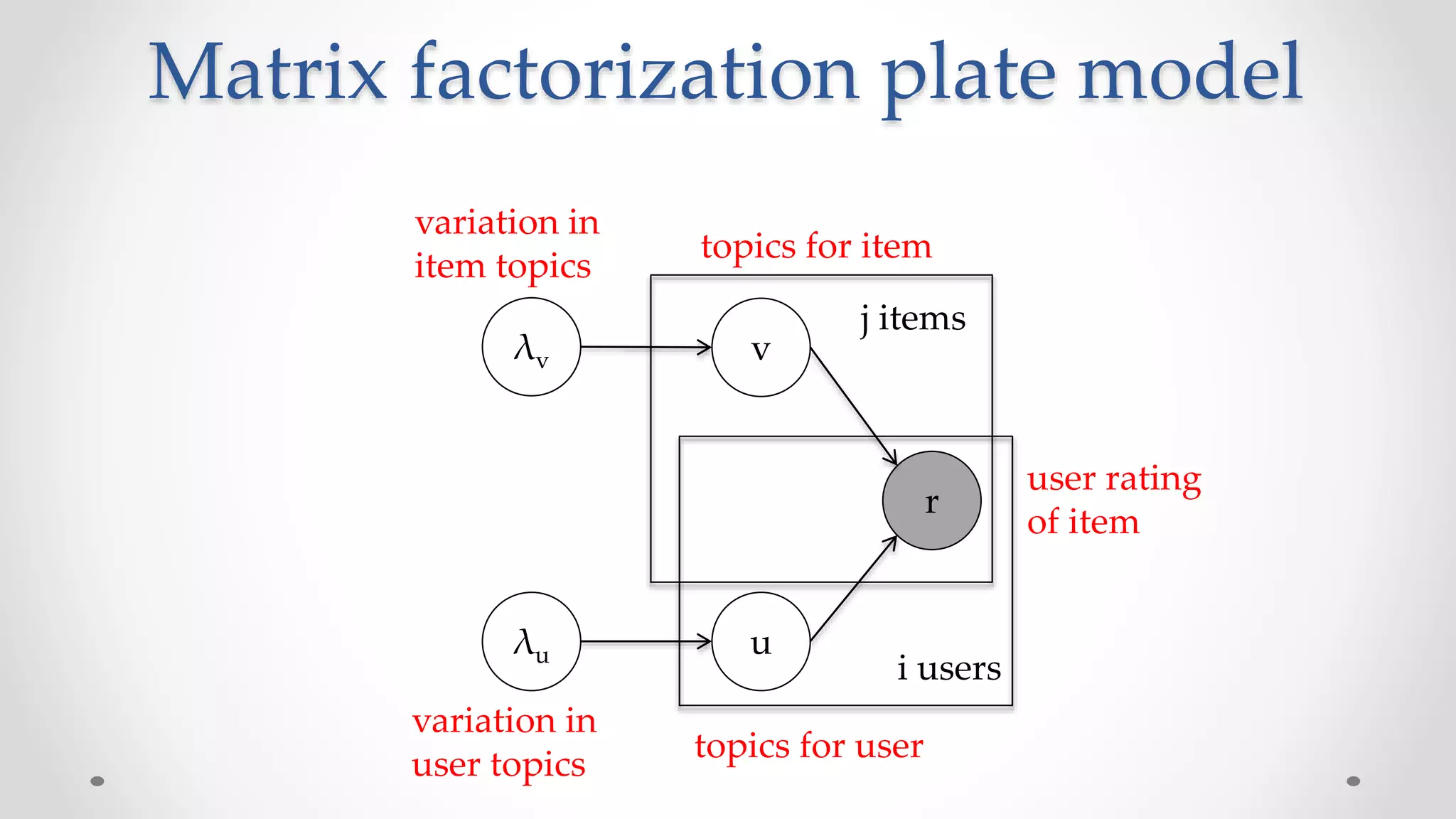



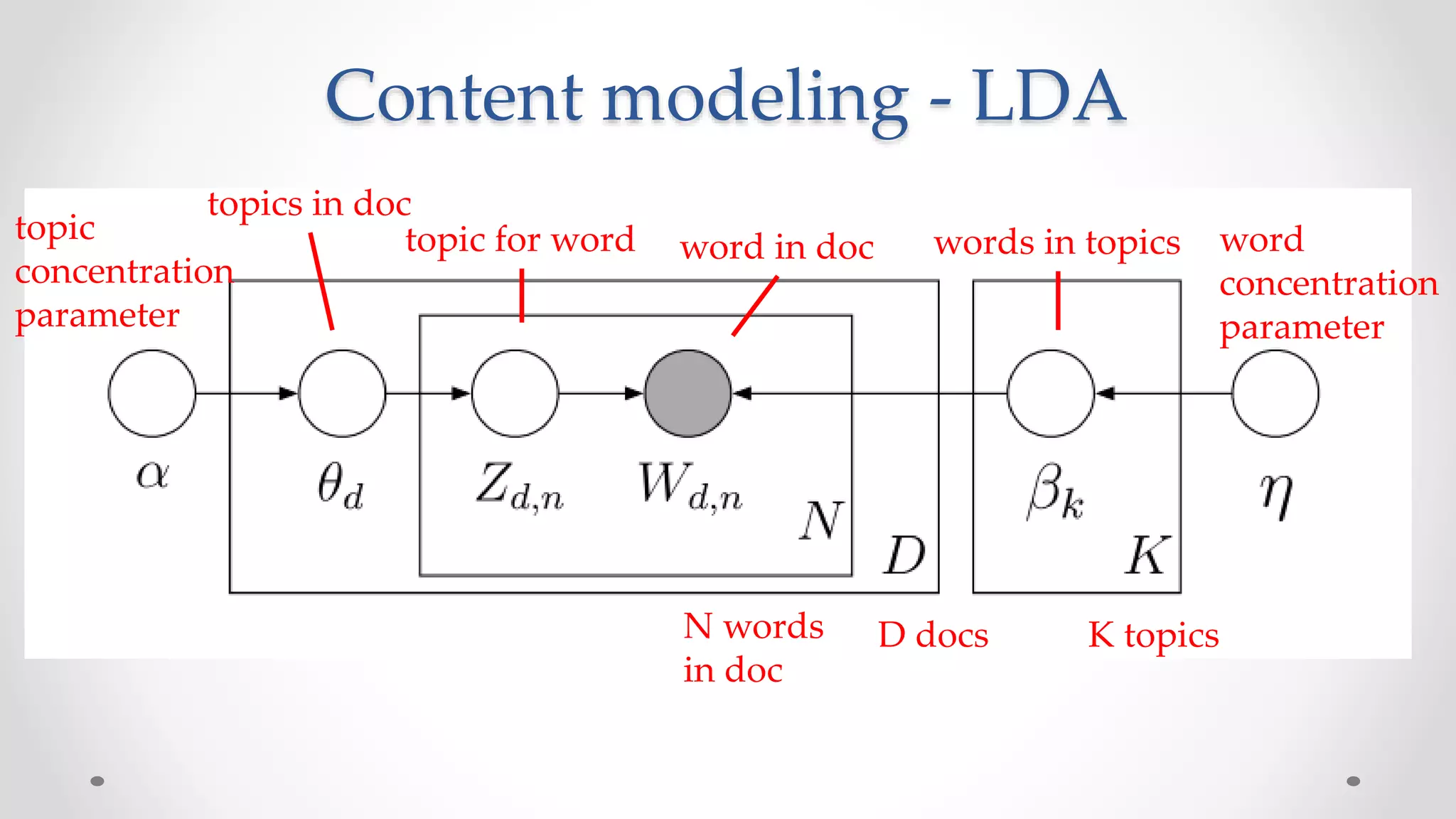
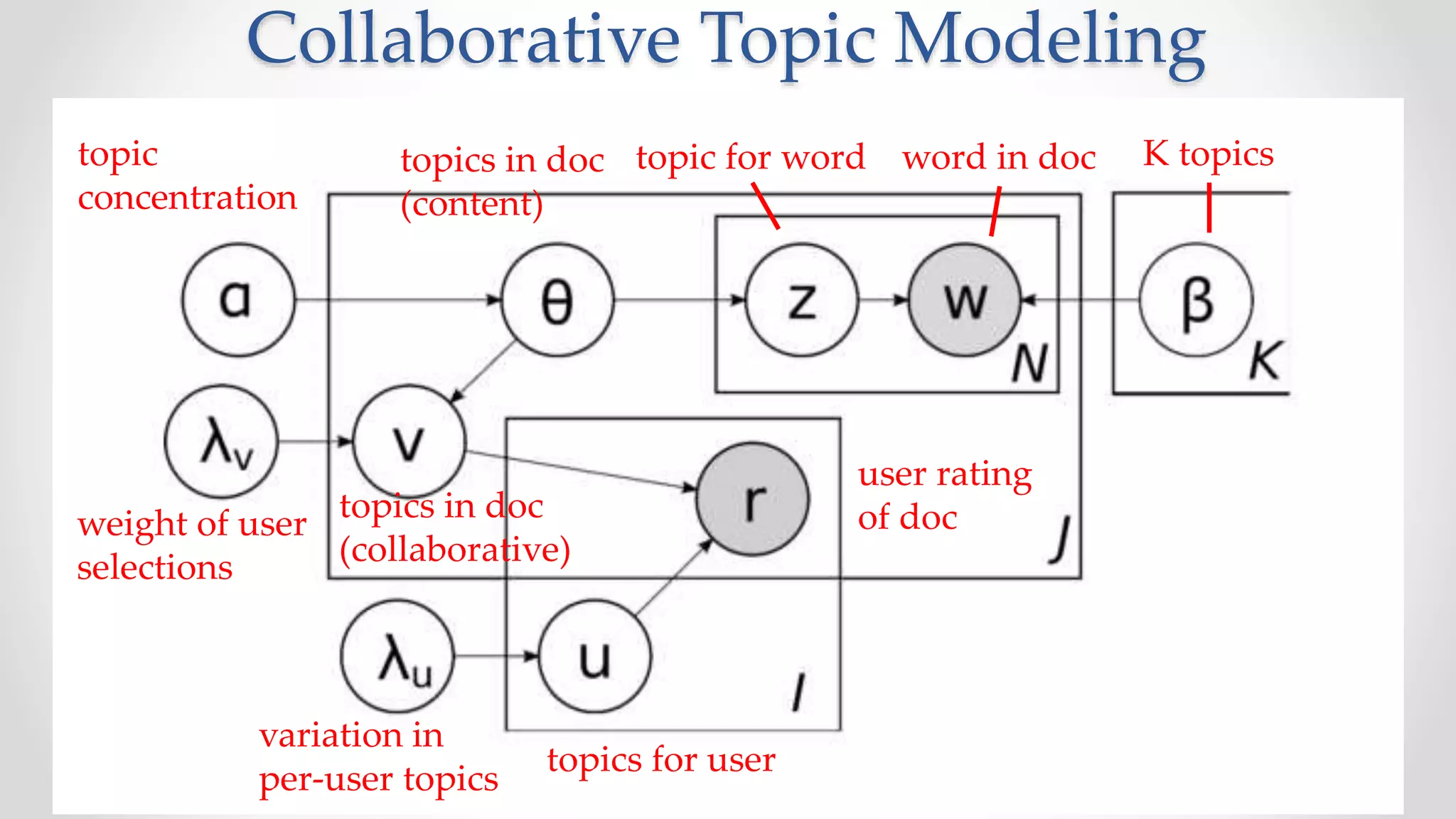

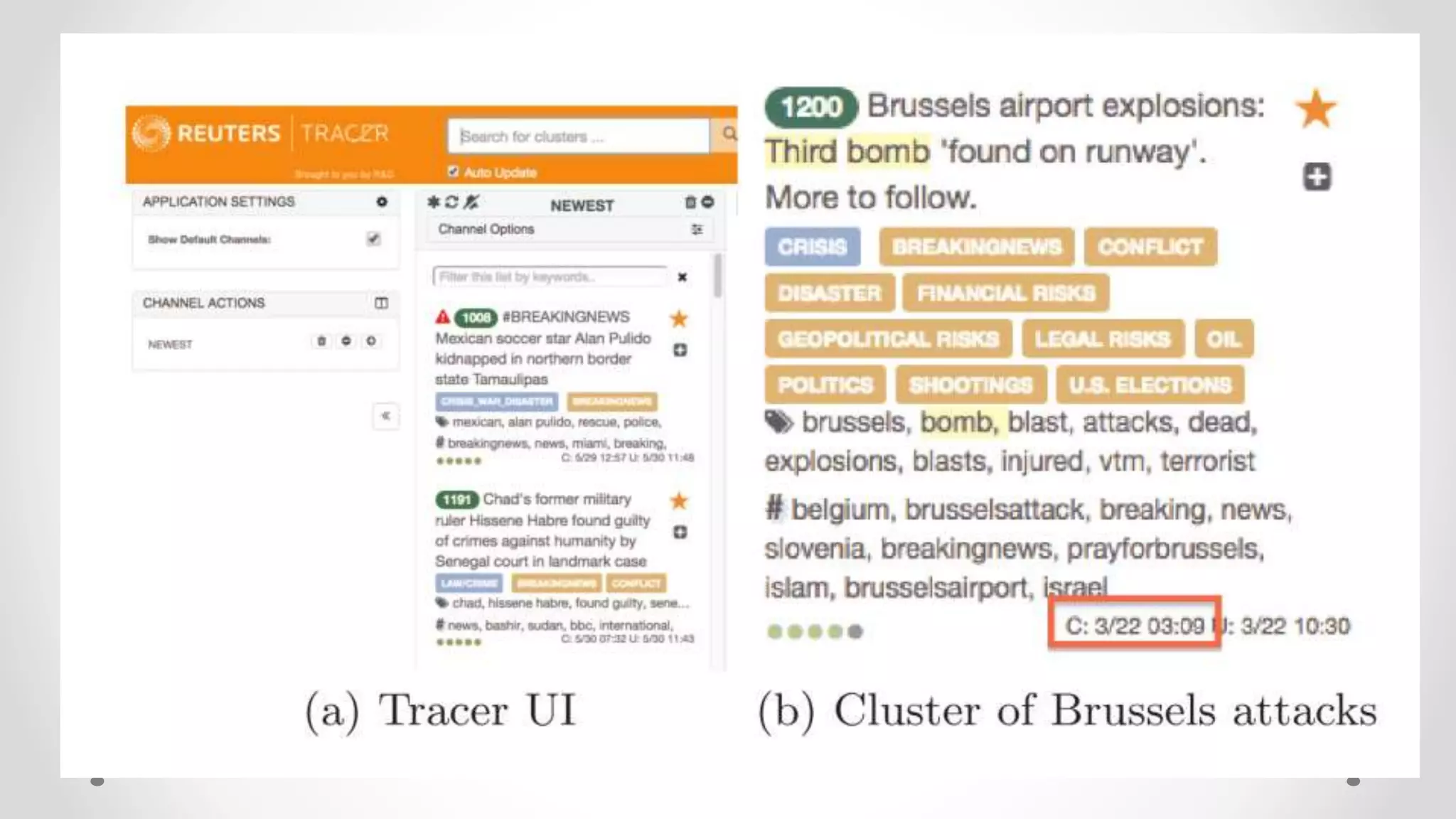
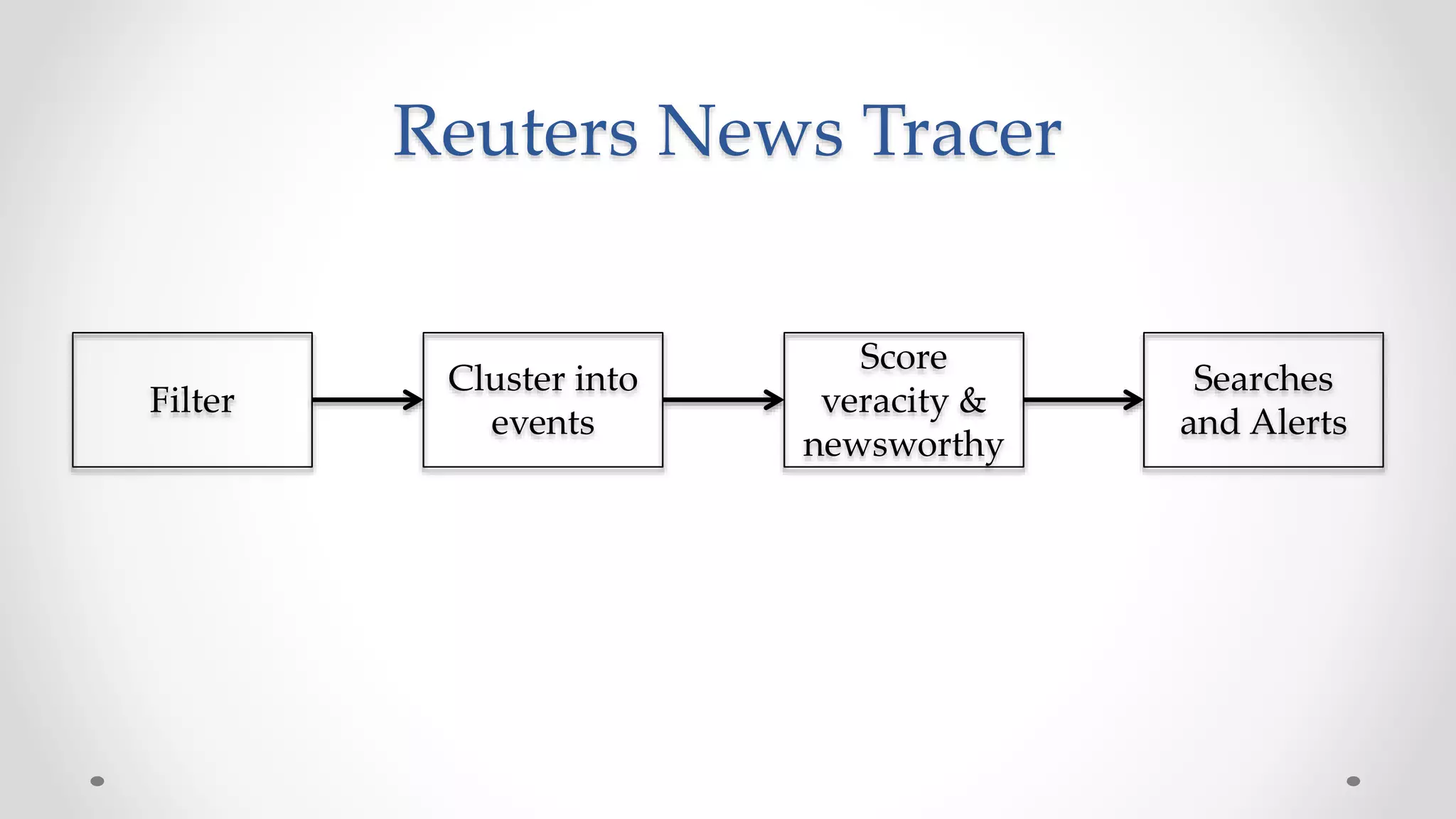
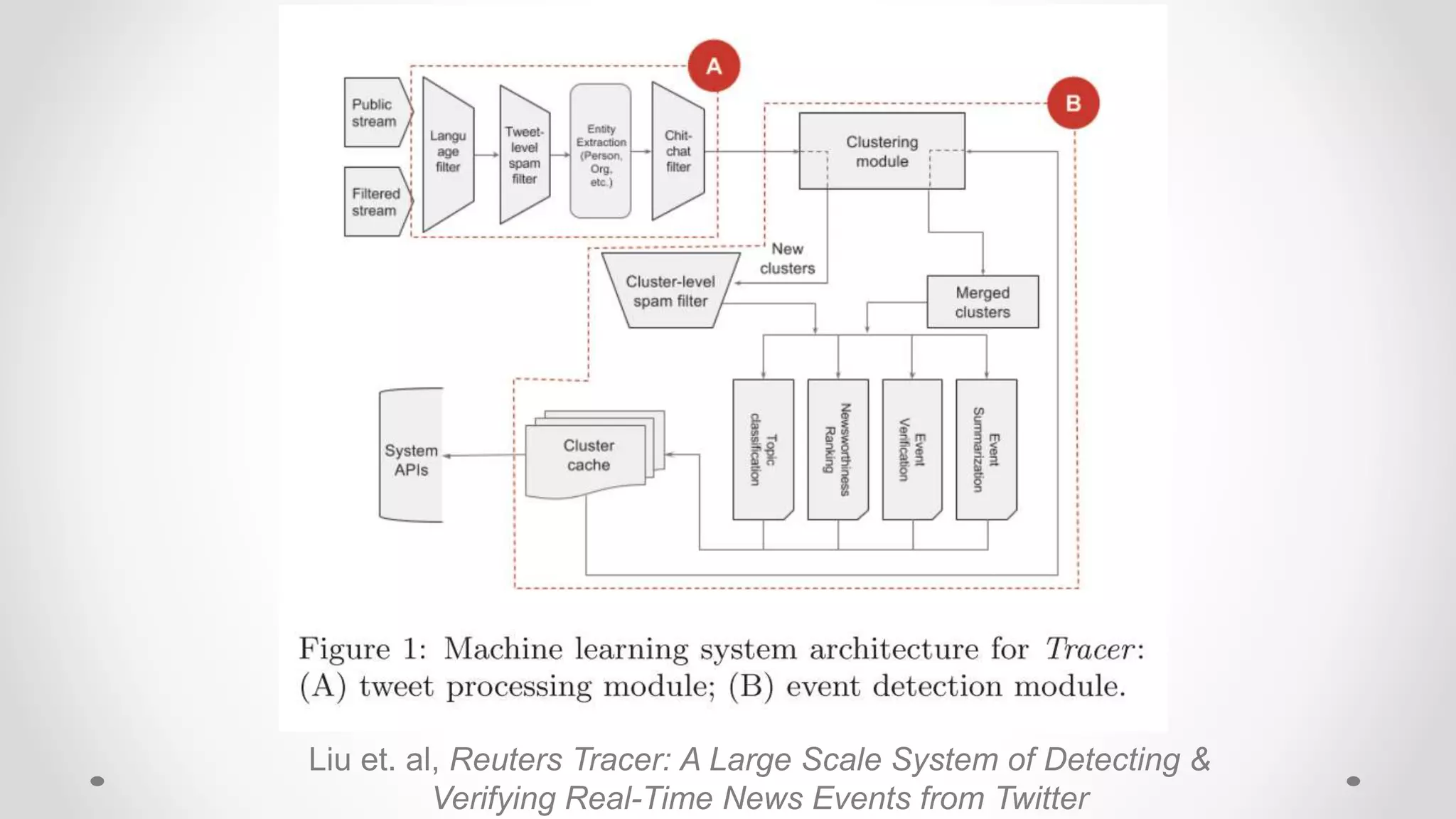

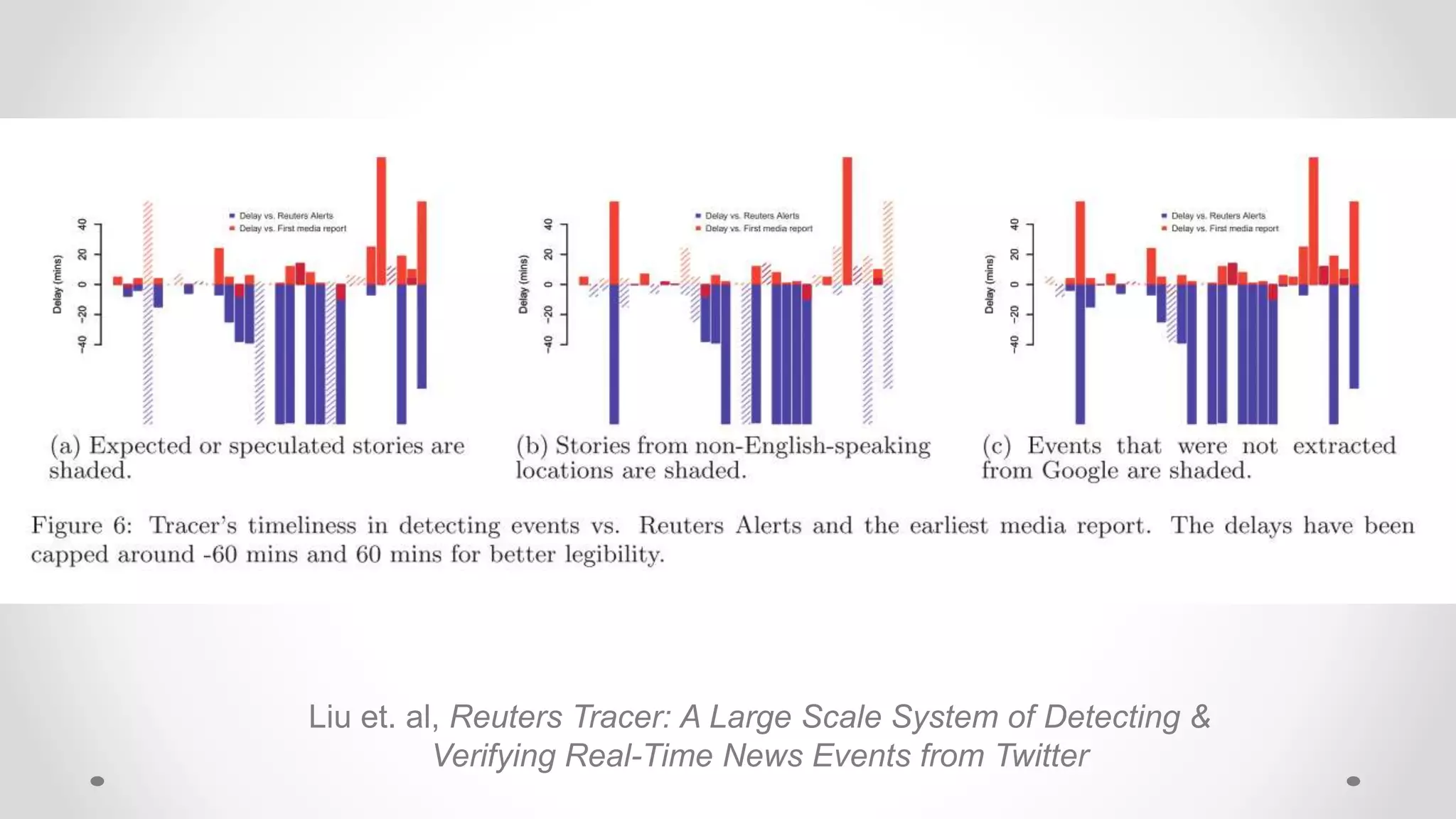





![Filter design problem
Formally, given
U = user preferences, history, characteristics
S = current story
{P} = results of function on previous stories
{B} = background world knowledge (other users?)
Define
r(S,U,{P},{B}) in [0...1]
relevance of story S to user U](https://image.slidesharecdn.com/lecture3informationfilterdesign3-181004180234/75/Frontiers-of-Computational-Journalism-week-3-Information-Filter-Design-62-2048.jpg)




















































































