Downloaded 27 times





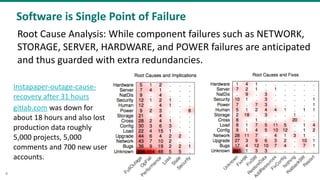



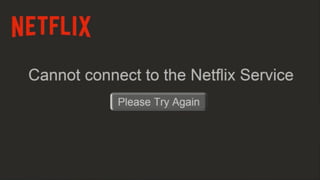
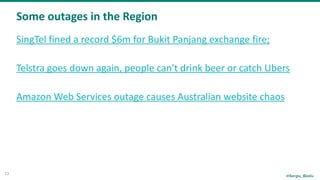
















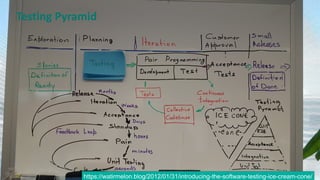








The document discusses the concept of chaos engineering, which aims to enhance the resilience of distributed systems by intentionally introducing failures to build confidence in their ability to withstand real-world challenges. It categorizes organizations into four types based on their resilience: fragile, resilient, robust, and antifragile, highlighting the importance of adapting and evolving in response to stress. Additionally, it emphasizes the necessity of rigorous testing and collaboration across teams to ensure reliability and effective risk management in software development.









































































